TEST - Ein kompakter Leitfaden zum Fine-Tuning und Erstellen benutzerdefinierter LLMs
von Team Databricks
Einleitung
Generative KI (GenAI) hat das Potenzial, KI zu demokratisieren, jede Branche zu transformieren, jeden Mitarbeiter zu unterstützen und jeden Kunden zu binden. Um am nützlichsten zu sein, benötigen GenAI-Modelle ein tiefes Verständnis der Unternehmensdaten einer Organisation. Bisher sind die beliebtesten Techniken, um GenAI-Modellen Wissen über Ihr Unternehmen zu vermitteln, Prompt Engineering, Retrieval Augmented Generation (RAG), Chains und Agents. Diese Techniken stoßen jedoch an ihre Grenzen, wenn allgemeine Modelle verwendet werden, die nicht auf bestimmte Domänen und Anwendungen zugeschnitten sind. Um die generierten Ergebnisse zu verbessern und die Kosten zu senken, müssen Entwickler von GenAI-Anwendungen auf das Erstellen benutzerdefinierter Modelle durch Fine-Tuning oder Pretraining zurückgreifen.
Fine-Tuning spezialisiert ein bestehendes KI-Modell für eine bestimmte Domäne oder Aufgabe, indem es weiter auf einem kleineren Satz benutzerdefinierter Daten trainiert wird. Zu den Techniken gehören supervised Fine-Tuning für die Befolgung von Anweisungen oder Chat sowie fortgesetztes Pretraining. Pretraining erstellt ein völlig neues Modell, indem es von Grund auf auf vollständig anpassbaren Daten trainiert wird. All diese Techniken ermöglichen es Entwicklern, geistiges Eigentum und Differenzierung für ihre Domäne oder Anwendung zu schaffen, mit dem Potenzial, bessere, genauere Modelle zu erstellen und kleinere, kostengünstigere Modellarchitekturen zu verwenden.
In diesem Leitfaden zur Erstellung benutzerdefinierter Modelle behandeln wir:
- Motivation: Warum und wann sollten Sie ein benutzerdefiniertes GenAI-Modell erstellen?
- Prinzipien: Welche übergeordneten Praktiken sollten Ihre Strategie und Implementierung beim Erstellen benutzerdefinierter Modelle leiten?
- Techniken: Wie können Sie benutzerdefinierte Modelle erstellen? Auf welche Techniken und „Fallstricke“ sollten Sie bei der Datenvorbereitung, beim Training und bei der Evaluierung achten?
Dieser Leitfaden richtet sich an Praktiker, die planen, benutzerdefinierte Modelle zu erstellen. Wir gehen von einem Verständnis von GenAI und Large Language Models (LLMs) aus, einschließlich Begriffen wie Prompt Engineering, RAG, Agents, Fine-Tuning und Pretraining. Für Einführungsmaterialien siehe mehr über generative KI und LLMs.
Über Databricks
Databricks bietet vereinheitlichte Tools zum Erstellen, Bereitstellen und Überwachen von KI- und ML-Lösungen – vom Erstellen prädiktiver Modelle bis hin zu den neuesten GenAI- und LLMs. Auf der Databricks Data Intelligence Platform aufgebaut, ermöglicht Databricks Organisationen, ihre Unternehmensdaten sicher und kostengünstig in den KI-Lebenszyklus mit jedem GenAI-Modell zu integrieren. Wir ermöglichen es Kunden, von Databricks feinabgestimmte oder vorab bereitgestellte Modelle wie Meta Llama 3, DBRX oder BGE oder von anderen Modell-Anbietern wie Azure OpenAI GPT-4, Anthropic Claude, AWS Bedrock und AWS SageMaker bereitzustellen, zu verwalten, abzufragen und zu überwachen. Zum Anpassen von Modellen mit Unternehmensdaten bietet Databricks jedes Architekturmuster von Prompt Engineering, RAG, Fine-Tuning und Pretraining.
Databricks bietet GenAI-Fine-Tuning- und Pretraining-Funktionen, die von keiner anderen KI-Plattform übertroffen werden. Bis Juni 2024 hatten Databricks-Kunden im Vorjahr über 200.000 benutzerdefinierte KI-Modelle erstellt. Darüber hinaus verfügt Databricks über vortrainierte Modelle, die von Kunden direkt genutzt werden können. Im März 2024 veröffentlichte Databricks DBRX, ein neues, leistungsstarkes Open-Source-LLM, das von Grund auf neu trainiert wurde und unter einer kommerziell nutzbaren Lizenz steht. Im Juni 2024 veröffentlichten Databricks und Shutterstock ein weiteres vortrainiertes Modell, Shutterstock ImageAI, Powered by Databricks, ein hochmodernes Text-zu-Bild-Modell.
Die Infrastruktur und Technologie, die wir zum Erstellen dieser leistungsstarken Modelle verwendet haben, ist dieselbe Infrastruktur und Technologie, die unseren Kunden zur Verfügung gestellt wird. Sehen Sie sich unsere Databricks-Kundengeschichten an, um Erfolge in den Bereichen Daten und KI in allen Branchen zu lesen.
Motivation: Warum Fine-Tuning oder benutzerdefinierte LLMs erstellen?
Kunden beginnen im Allgemeinen mit der Erstellung benutzerdefinierter GenAI-Modelle, wenn bestehende Modelle schmerzhafte Einschränkungen in Bezug auf Qualität, Kosten oder Latenz aufweisen. Die Einzelheiten sind für jeden Anwendungsfall unterschiedlich, aber Beispiele sind:
- „Ich benötige ein Modell, um die spezielle Abfragesprache meines Produkts zu generieren. Ich kann dies mit Modell-APIs und Few-Shot-Prompting tun, aber es ist sehr langsam und teuer.“
- „Mein RAG-Bot funktioniert gut, aber er verwendet eine große, leistungsstarke Modell-API, die für meinen Anwendungsfall mit hohem Durchsatz zu teuer ist. Ich benötige kein so allgemeines Modell und möchte daher ein kleines, gezieltes, günstiges Modell feinabstimmen.“
- „Ich kann kein Open-Source-Modell finden, das gut in Sprache X ist, daher möchte ich ein Modell erstellen, das darauf zugeschnitten ist, X zu verstehen.“
Die berühmtesten GenAI-Modelle sind allgemeine Modelle, die (fast) alles tun sollen. Obwohl diese Modelle beeindruckend sind, sind sie für die meisten Anwendungsfälle zu groß und zu teuer und sie wissen nichts über Ihre proprietären Daten oder Ihre Anwendung. In jedem der obigen Beispiele erhöhte die Erstellung eines benutzerdefinierten, spezialisierten Modells die Qualität oder senkte die Kosten und die Latenz. Das benutzerdefinierte Modell wurde zu geistigem Eigentum und bot einen Wettbewerbsvorteil für das Produkt des Kunden.
Eine weniger verbreitete, aber dringendere Motivation für die Erstellung benutzerdefinierter Modelle ergibt sich aus rechtlichen oder regulatorischen Bedenken, insbesondere in stärker regulierten Branchen. Einige Kunden wünschen oder benötigen die volle Kontrolle über ihre Modelle, um Risiken zu managen, wie z. B. Vorwürfe der illegalen Nutzung von Inhalten für das Modelltraining. Durch das Vortrainieren eines vollständig benutzerdefinierten Modells können Sie genau wissen und nachweisen, wie das Modell erstellt wurde.
Wie können Sie also loslegen? Obwohl GenAI ein komplexes Forschungsgebiet ist, kann die Anpassung von GenAI-Modellen einfach sein. Es gibt einen natürlichen Weg vom einfachen Fine-Tuning zum komplexen Pretraining, und die Databricks-Plattform unterstützt diesen gesamten Workflow. Wenn Sie diesen Weg gehen, bauen Sie Fachwissen und Daten auf, die in zukünftige, komplexere Arten der Modellanpassung einfließen werden.
Prinzipien: Wann und wie sollten Sie Fine-Tuning oder benutzerdefinierte Modelle erstellen?
Wann, warum und wie sollten Sie benutzerdefinierte Modelle erstellen?
Auf hoher Ebene können GenAI-Systeme auf zwei Arten angepasst werden:
- Compound AI: Ausgehend von einem oder mehreren bestehenden Modellen können Sie RAG, Agents und andere Compound-KI-Systeme um diese Modelle herum erstellen.
- Benutzerdefinierte Modelle: Sie können ein bestehendes Modell anpassen (Fine-Tuning) oder ein völlig neues Modell erstellen (Pretraining).
Diese beiden Optionen können kombiniert werden, z. B. RAG mit einem feinabgestimmten LLM. Solche Kombinationen – und die Geschwindigkeit der GenAI-Entwicklung – können die Planung und Erstellung von GenAI-Anwendungen komplex machen. Um Ihren Ansatz zu vereinfachen, empfehlen wir drei Leitprinzipien.
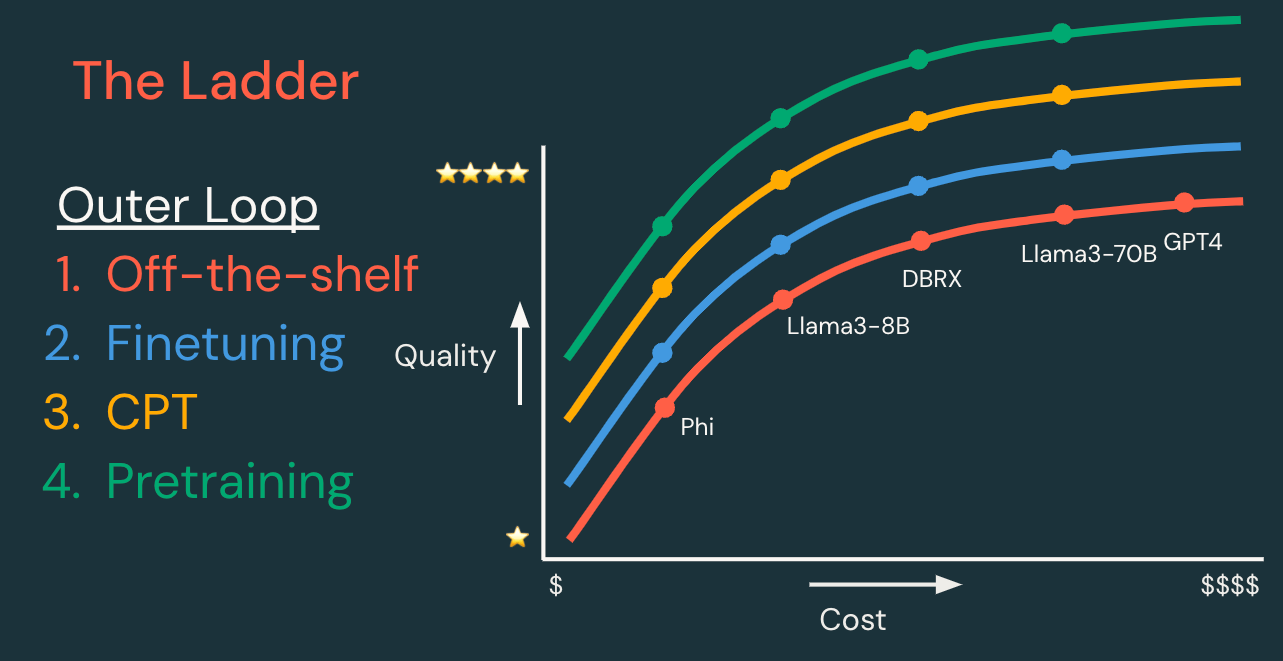
Prinzip 1: Klein anfangen und sich hocharbeiten
Für jede GenAI-Anwendung empfehlen wir, einfach zu beginnen und bei Bedarf Komplexität hinzuzufügen. Das kann bedeuten, mit einem bestehenden Modell zu beginnen (z. B. über die Databricks Foundation Model APIs) und einfaches Prompt Engineering durchzuführen. Fügen Sie dann bei Bedarf Techniken hinzu, um Ihre Metriken für Qualität, Kosten und Geschwindigkeit zu verbessern.
Die „Leiter“ der Techniken kann in innere und äußere Entwicklungsloops unterteilt werden, wie unten dargestellt.
Äußerer Loop: Leiter der Modell-Anpassung | ||||
Jeder Schritt hat das Potenzial, ein Modell mit höherer Qualität, niedrigeren Kosten und/oder geringerer Latenz zu erstellen. | Erforderliche Daten | Entwicklungszeit | Entwicklungskosten | |
Bestehendes Modell | Beginnen Sie mit einem bestehenden Modell oder einer Modell-API und iterieren Sie zuerst im inneren Loop. | Keine oder Daten für RAG | Stunden | $ |
Supervised Fine-Tuning | Passen Sie ein Modell an, um Ihre spezifische Aufgabe besser zu bewältigen. „Erwarten Sie solche Anfragen und geben Sie solche Antworten.“ | Hunderte bis 10.000 Beispiele | Tage | $$ |
Fortgesetztes Vortraining | Passen Sie ein Modell an, damit es Ihre Domäne besser versteht. „Lernen Sie die Sprache dieser Nischenanwendungsdomäne.“ | Millionen bis Milliarden von Tokens | Wochen | $$$ |
Vortraining | Erstellen Sie ein neues Modell, um die volle Kontrolle, Anpassung und Eigentümerschaft zu haben. „Lernen Sie alles von Grund auf neu!“ | Milliarden bis Billionen von Tokens | Monate | $$$$$$ |
Innere Schleife: Kombinierte KI-Techniken | |
Jede der folgenden Techniken kann die Generierungsqualität für ein bestimmtes Modell verbessern. Diese Techniken sind in (ungefährer) Reihenfolge ihrer Komplexität aufgeführt, können aber beliebig kombiniert werden. | |
Prompt Engineering | Erstellen Sie aufgabenspezifische Prompts, um das Modellverhalten zu steuern. |
Few-Shot-Prompting | Stellen Sie Daten in Prompts bereit, um Modelle zur Inferenzzeit zu trainieren. |
RAG | Stellen Sie modellspezifische Daten als zusätzlichen Kontext bereit. |
Agenten | Stellen Sie Modellen aufrufbare Werkzeuge und/oder komplexe Kontrollflüsse zur Verfügung. |
Die Übernahme einer Technik aus der inneren Schleife ist relativ günstig und schnell, verglichen mit dem Aufstieg in der äußeren Schleife. Daher lohnt es sich immer, wenn Sie in der äußeren Schleife aufsteigen, einige oder alle Techniken der inneren Schleife zu wiederholen. Diese Bezeichnung „innen“ versus „außen“ ist umgekehrt zu dem, was Sie von der Systemarchitektur erwarten würden – die „innere“ Schleife des Compound AI umschließt die „äußere“ Schleife Ihres Modells. Wir nennen die Modellanpassung die „äußere“ Schleife, weil sie die äußere Schleife in Bezug auf Ihren Workflow ist, wie durch die relativen Kosten der inneren und äußeren Schleifen vorgegeben.
Prinzip 2: Datengetrieben handeln
Bevor Sie ernsthaft in ein Projekt investieren, definieren Sie sorgfältig Ihr Erfolgsmaß und folgen Sie gängigen praxisorientierten Entwicklungsmethoden zur Evaluierung.
Auf der Ebene von KI-Systemen sollten Sie Metriken für Qualität, Kosten und Latenz berücksichtigen.
- Qualität wird wahrscheinlich mehrere Metriken umfassen: Genauigkeit, Nutzerfeedback, Toxizität usw.
- Kosten für Systeme in der Produktion konzentrieren sich im Allgemeinen auf Modellinferenz und Datenbereitstellung
- Latenz kann die End-to-End-Latenz bedeuten oder die Zeit bis zum ersten Token für interaktivere Anwendungen
Welche Zahlen müssen diese Metriken erreichen, um den Erfolg zu erklären? Welche harten Einschränkungen haben Sie bei diesen Metriken, um eine gute Benutzererfahrung, einen positiven Return on Investment oder andere Geschäftsanforderungen zu gewährleisten? Sehen Sie sich diesen Vortrag unseres Chief AI Scientist an für weitere Diskussionen.
Analysieren Sie auf Projekt- und Geschäftsebene den Return on Investment.
- Kosten (Investition) sollten in zwei Phasen unterteilt werden:
- Entwicklungskosten können Rechen- und Personalkosten für Datenaufbereitung, Modelltraining und Systementwicklung umfassen
- Laufende Kosten können Modell- und Datenbereitstellung sowie Wartungsaufwand umfassen
- Geschäftsauswirkungen (Rendite)
- Umsatz oder andere Geschäftsziele und Key Results (OKRs) können von der Einsparung menschlicher Arbeitszeit (für einen GenAI-Support-Bot) bis hin zu direkten Umsätzen (für ein GenAI-gestütztes Produkt) reichen
- IP-Erstellung, wie z. B. neue Modelle oder Daten, ist möglicherweise am schwierigsten zu messen, aber langfristig am wichtigsten. Jeder kann dieselben API-Anbieter für Modelle nutzen, aber nur Sie können Ihre proprietären Modelle und Daten nutzen.
Ihre datengesteuerten Ziele werden Ihre Entscheidungen bezüglich der Modellanpassung (Prinzip 1) beeinflussen. Wenn Sie beispielsweise Ihre Qualitätsmetriken erreichen, aber Ihre Kostenbeschränkungen mit einer teuren Modell-API überschreiten, könnten Sie zum Fine-Tuning eines kleineren, effizienteren Modells übergehen, das auf Ihre spezifische Aufgabe zugeschnitten ist, um die Kosten zu senken und gleichzeitig die Qualität zu erhalten. Das Fine-Tuning verursacht zusätzliche Entwicklungskosten, reduziert aber die laufenden Kosten – und die Gesamtkosten langfristig.
Prinzip 3: Praktisch bleiben
Die Evaluierung von GenAI-Modellen und -Systemen ist eine Herausforderung. Fine-Tuning- und Vortrainingstechniken sind ein heißes Forschungsgebiet. Akademische und industrielle Begeisterung (und LLMs) erzeugen weitaus mehr Inhalte, als man lesen kann. Diese Verwirrungsquellen machen es schwierig zu wissen, wann man welche Techniken anwenden sollte. („Brauche ich LoRA? Was ist Curriculum Learning? Welche Modellarchitektur ist die beste?“)
Viele, die neu in GenAI sind, haben gehört, dass man GenAI riesige Datenmengen zuführen kann und es erstaunliche Dinge lernt. Dämpfen Sie diese Erwartungen. Die Datenmenge ist wichtig, aber auch die Datenqualität, die Trainingstechniken und die Evaluierung sind wichtig.
Databricks-Kunden können sich teilweise auf die integrierte Anleitung von Databricks auf ihrem Weg zur GenAI-Anpassung verlassen. Diese Anleitung reicht von einfachen APIs für allgemeine Modelle über das Agent Bricks Custom Agents für RAG und Agenten bis hin zu einer Benutzeroberfläche und API für das Fine-Tuning und sogar einer geführten API für das Vortraining.
Je weiter Sie die Anpassung vorantreiben, desto mehr Techniken und Entscheidungen müssen Sie treffen. Wir empfehlen Ihnen, praktisch zu bleiben. Techniken, die in der Forschung funktioniert haben, funktionieren möglicherweise nicht in realen Anwendungen. Modelle, die für eine Aufgabe gut sind, können für eine andere schlecht sein. Die besten Techniken werden sich im Laufe der Zeit ändern. Um diese Komplexität zu bewältigen, behalten Sie die Prinzipien 1 und 2 im Hinterkopf: Definieren Sie Ihren Nordstern und folgen Sie ihm basierend auf Daten und Metriken.
Wir empfehlen Ihnen auch, mit uns zusammenzuarbeiten. Über Ihr unmittelbares Databricks-Team hinaus kann unser Professional Services-Team Sie von ersten Proof of Concepts bis hin zu vollständigen Vortraining-Läufen begleiten. Unser Mosaic Research-Team arbeitet mit vielen Kunden an Vortraining-Läufen zusammen und bietet ihnen Zugang zu Spitzenwissen und Beratung.
Techniken zum Erstellen benutzerdefinierter LLMs
Wenn Sie die äußere Schleife der Modellanpassung erklimmen möchten, wie sollten Sie die mit Prinzip 1 eingeführten Techniken angehen? Dieser Abschnitt befasst sich mit der Evaluierung und taucht dann in die wichtigsten Anpassungstechniken ein.
Hinweis: Dieser Leitfaden konzentriert sich nicht auf die innere Schleife der Iteration an einem festen Modell. Weitere Hintergrundinformationen zu diesen Techniken finden Sie in den Kursen Generative AI Fundamentals und Generative AI Engineering With Databricks.
Dieser Abschnitt entwickelt die zuvor im äußeren Regelkreis von Prinzip 1 dargelegten Anpassungstechniken. Wir listen sie hier auf und weisen darauf hin, dass Ihre Wahl der Technik weitgehend von den verfügbaren Daten bestimmt wird (Prinzip 2).
Äußerer Regelkreis: Leiter der Modelloptimierung | ||
Erforderlicher Datentyp | Richtlinien zur Datengröße | |
Vorhandenes Modell | N/A | Keine oder Daten für RAG |
Überwachtes Fine-Tuning | Abfrage-Antwort-Daten (oder anderweitig „gelabelte“ Daten) | Mindestens Hunderte bis Zehntausende von Beispielen |
Fortgesetztes Pre-Training | „Rohe“ Texte für die Vorhersage des nächsten Tokens | Millionen bis Milliarden von Tokens oder 1 % des ursprünglichen Trainingsdatensatzes |
Pre-Training | „Rohe“ Texte für die Vorhersage des nächsten Tokens | Milliarden bis Billionen von Tokens |
Im nächsten Abschnitt behandeln wir jede Technik detaillierter, beginnend mit Richtlinien, die für alle Techniken konstant bleiben.
Daten
Ihre Daten müssen zu Ihrem Anwendungsfall passen. Wenn Sie ein Modell feinabstimmen, um auf eine bestimmte Weise zu antworten, müssen Ihre Trainingsdaten „gute“ Antworten demonstrieren. Wenn Sie ein fortgesetztes Pre-Training durchführen, um eine bestimmte Domäne zu verstehen, müssen Ihre Daten diese Domäne repräsentieren.
Klären Sie rechtliche und lizenzrechtliche Fragen von Anfang an. Bei der Verwendung öffentlicher Daten, insbesondere für das Pre-Training, beachten Sie, dass einige öffentliche Datensätze gut kuratiert sind, um rechtliche Komplikationen zu vermeiden, und einige Datensätze nicht. Bei der Verwendung Ihrer eigenen Unternehmensdaten stellen Sie sicher, dass Sie sich über die Herkunft im Klaren sind, insbesondere darüber, ob die Daten von Kunden oder von GenAI-Modellen mit restriktiven Lizenzen stammen.
Sammeln Sie Daten früh und oft. Abfragen, Antworten und Benutzerfeedback aus Ihren heutigen Anwendungen können zu Eingaben für das Tuning und Training Ihrer GenAI-Modelle in der Zukunft werden – aber nur, wenn Sie sorgfältig vorgehen. Viele proprietäre und Open-Source-Modelle unterliegen Nutzungsbeschränkungen. Verfolgen Sie daher die Herkunft generierter Antworten sorgfältig. Um sich zukünftige Flexibilität zu verschaffen, vermeiden Sie die Vermischung von Modellen und Daten mit inkompatiblen Lizenzen und bevorzugen Sie offene Lizenzen.
Verwenden Sie synthetische Daten mit Bedacht. Synthetische Daten können hilfreich sein, aber echte Unternehmensdaten sind fast immer wertvoller. „Echte“ Daten können verwendet werden, um LLMs darüber zu informieren, wie synthetische Daten generiert werden, was Sie später in diesem Leitfaden erfahren werden. Synthetische Daten sind immer noch ein aktives Forschungsgebiet.
Modelle
Beachten Sie Basis- vs. Instruct/Chat-Modelle. Die meisten großen LLM-Releases enthalten sowohl Basismodelle (vorab trainiert, aber nicht feinabgestimmt) als auch Instruktions-folgende oder Chat-Varianten (feinabgestimmt). Sehen Sie unsere Empfehlungen, welche Art in den folgenden Abschnitten zu verwenden ist.
Verwenden Sie die von den Databricks-Funktionen vorgeschlagenen Modelle. Mosaic Research untersucht modernste Modellarchitekturen, teilt einige Top-Empfehlungen für GenAI-Modelle und priorisiert diese Top-Modelle in Databricks Model Training und anderen Funktionen.
Gehen Sie bei Bedarf zu benutzerdefiniertem Code über. Wenn Standardmodelle oder Trainingsmethoden nicht Ihren Anforderungen entsprechen, können Sie jederzeit „in den Stack absteigen“ und benutzerdefinierteren Code verwenden. Die GPU-beschleunigten Cluster von Databricks (allgemeine Rechenleistung) und Databricks Model Training (spezialisierte Deep-Learning-Rechenleistung) unterstützen beide beliebigen Trainingscode für GenAI und andere Deep-Learning-Modelle.
Identifizieren Sie Modelle, die für Ihren Anwendungsfall vielversprechend sind. Untersuchen Sie vor dem Tuning, ob das generische Modell für Ihre Anwendung vielversprechend ist. „Vielversprechend“ kann durch Ad-hoc-Manuelltests mit dem AI Playground oder durch rigorosere Tests mit einem Benchmark-Datensatz oder Ihrem benutzerdefinierten Evaluationsdatensatz gemessen werden. Tests können ein kleinskaliges Training erfordern. Verbessert sich das Modell nach dem Fine-Tuning mit einer kleinen Menge von 100 Beispielen? Verbessert sich das Modell durch fortgesetztes Pre-Training auf einem bestimmten Datensatz?
Denken Sie an Ihre Einschränkungen. Wählen Sie Ihre Modellgröße basierend auf Ihren Kosten- und Latenzeinschränkungen zur Inferenzzeit. Denken Sie auch daran, dass das Erstellen benutzerdefinierter Modelle nur der äußere Regelkreis ist; Sie können Kosten und Latenz auch im inneren Regelkreis optimieren, z. B. indem Sie einfachere Anfragen an kleinere Modelle weiterleiten.
Tipp: Ihre Arbeit an einfacheren Techniken wird nicht verschwendet, da diese Techniken eine Sequenz bilden. Nachdem Sie beispielsweise ein Modell vortrainiert haben, führen Sie normalerweise als Nächstes ein überwachtes Fine-Tuning durch.
Evaluierung
Prinzip 2 empfiehlt, datengesteuert mit Metriken zu arbeiten. Bevor wir uns mit den Einzelheiten des Erstellens benutzerdefinierter Modelle befassen, werden wir die Metriken für Evaluierung und Qualität behandeln, die Ihre Arbeit leiten können.
Wie im Software Engineering empfehlen wir, einer Testpyramide zu folgen.
Analogie zu Softwaretests | Geschwindigkeit/Kosten vs. Genauigkeit | Beispiele |
Unit-Tests | Schnelle und kostengünstige Proxy-Messungen | Tests mit richtigen/falschen Antworten |
Integrationstests | Tests mit mittlerer Geschwindigkeit/Kosten | LLM-als-Richter-Metriken auf Benchmark-Datensätzen |
End-to-End-Tests | Langsame, aber realistische Tests | Menschliches Feedback |
Die Beispiele in der obigen Testpyramide sind allgemein gehalten und vermeiden die Frage, ob Modelle (äußerer Regelkreis aus Prinzip 1) oder zusammengesetzte KI-Systeme (innerer Regelkreis) getestet werden. Beim Erstellen eines benutzerdefinierten Modells möchten Sie sowohl das Modell selbst als auch die KI-Systeme testen, die es verwenden werden. Beispielsweise könnten „LLM-als-Richter-Metriken“ verwendet werden, um die Fähigkeit eines Modells zur Befolgung von Anweisungen zu testen, und sie könnten verwendet werden, um die Abrufabfragen und die Frage-Antwort-Metriken eines RAG-Systems zu testen.
Spezifische vs. allgemeine Modelle und Aufgaben
Ihre Testpyramide wird sehr unterschiedlich aussehen, wenn Sie ein Modell für eine bestimmte Aufgabe feinabstimmen, im Vergleich zum Pre-Training eines Allzweckmodells. Datengesteuert und metrikorientiert zu sein bedeutet,Ihre Testpyramide auf die nachgelagerten Anwendungsfälle Ihres Modells zuzuschneiden.
Wenn Sie ein Modell für eine bestimmte Aufgabe feinabstimmen, denken Sie daran, klein anzufangen (Prinzip 1). Sie könnten zum Beispiel:
- Erstellen Sie einen „goldenen“ Abfrage-Antwort-Datensatz zur Evaluierung. Stellen Sie sicher, dass er über potenzielle Abfragen und Themen hinweg ausgewogen ist.
- Verwenden Sie LLM-als-Richter-Metriken, um die Evaluierung zu skalieren. Wählen oder passen Sie Metriken für Ihre spezifische Aufgabe an.
- Verwenden Sie menschliche oder Benutzerbewertungen als abschließenden Test
Wenn Sie mit fortgesetztem Pre-Training oder vollständigem Pre-Training beginnen, können Ihre Evaluierungen komplexer werden. Wenn Sie Ihre Testpyramide planen, zerlegen Sie Ihre Evaluierung nach den verschiedenen Fähigkeiten, die Ihr Modell Ihrer Meinung nach benötigt, damit Sie sich auf die wichtigen Bereiche konzentrieren können. Das kann bedeuten:
- Fähigkeiten wie Allgemeinwissen, Logik oder Leseverständnis
- Domänen wie Finanzen, Recht oder Gesundheitswesen
- Sprachen, einschließlich natürlicher Sprachen oder Programmiersprachen
- Andere Dimensionen, von der Kontextlänge bis zu integrierten Schutzvorrichtungen
Tipps:
- Passen Sie Ihre Evaluierung an Ihre Anwendungsfälle an. Wenn Sie beispielsweise ein Modell zur Verarbeitung längerer Kontextlängen modifizieren, denken Sie daran, dass Metriken zur Perplexität beim fortgesetzten Vortraining nicht ausreichen. Ihr Evaluierungsdatensatz muss auch Aufgaben mit langem Kontext enthalten.
- Testen Sie sowohl Lernen als auch Vergessen. Wenn Sie ein fortgesetztes Vortraining durchführen, um das Verständnis eines Modells für eine bestimmte Sprache (z. B. Malaiisch) zu verbessern, überlegen Sie, ob Ihre Anwendungsfälle erfordern, dass das Modell sein bestehendes Sprachverständnis (z. B. Englisch) beibehält. Wenn ja, sollte Ihre Evaluierung sowohl Malaiisch als auch Englisch testen.
- Testen Sie, was Ihre Kunden tatsächlich nutzen werden. Wenn Sie ein neues (Basis-)Modell vortrainieren, werden Sie wahrscheinlich ein Instruction Fine-Tuning durchführen, um die Modellversion zu erstellen, die Ihre Kunden tatsächlich nutzen werden. Ihre endgültige (End-to-End-)Evaluierung sollte auf dem feinabgestimmten Modell und nicht auf dem Basismodell erfolgen.
Beispiele aus der Erstellung von DBRX
Im Mai 2024 veröffentlichte Databricks DBRX, ein (damals) hochmodernes Open-Source-LLM. Seine Evaluierungssuite liefert ein gutes Beispiel für eine Testpyramide, die unten skizziert ist.
Analogie zu Softwaretests | Beispielmetriken aus der Erstellung von DBRX | |
Unit-Tests | 39 öffentlich verfügbare Benchmarks, aufgeteilt in sechs Kernkompetenzen: Sprachverständnis, Leseverständnis, symbolische Problemlösung, Weltwissen, gesunder Menschenverstand und Programmierung | |
Integrationstests | Benchmark-Daten für Multi-Turn-Konversationen und Befolgung von Anweisungen | |
Benchmark-Daten für Befolgung von Anweisungen | ||
Chatbot Arena-basierter Generator für Benchmark-Daten menschlicher Präferenzen | ||
End-to-End-Tests | Internes und Kundenfeedback und A/B-Tests | Iterative Tests mit internen und externen Benutzern zur Sammlung von A/B-Testmetriken und menschlichen Annotationen |
Red-Teaming | Experten-Tests zur Generierung unerwünschter Ausgaben (anstößig, voreingenommen oder anderweitig unsicher) |
Für weitere Hintergrundinformationen zu Evaluierungsmetriken empfehlen wir diesen Generative AI Engineering-Kurs. Für Werkzeuge empfehlen wir Databricks MLflow, das automatisierte Metriken (LLM-as-a-judge), Evaluierungsdatensätze und eine menschliche Evaluierungs-App unterstützt. Agent Evaluation verwendet Open-Source MLflow APIs für LLM-Evaluierung. Für eine umfassendere Evaluierung für das Vortraining können wir mit Ihnen zusammenarbeiten, um Ihren benutzerdefinierten Evaluierungsplan zu entwickeln.
Supervised Fine-Tuning
Die erste Technik zur Modellkustomisierung, die von den meisten Praktikern verwendet wird, ist Supervised Fine-Tuning (SFT), bei der ein Modell auf gelabelten Daten trainiert wird, um es für eine bestimmte Aufgabe oder ein bestimmtes Verhalten zu optimieren.
Häufige Anwendungsfälle sind:
- Named Entity Recognition: Feinabstimmung eines Modells zur Erkennung domänenspezifischer Entitäten
- Chat-Vervollständigung und Fragebeantwortung: Feinabstimmung eines Modells, um in einem bestimmten Ton zu antworten
- Ausgabeformatierung: Feinabstimmung eines Modells, um mit spezifischen, strukturierten Ausgaben zu antworten
- Befolgen von Anweisungen: Nach dem Vortraining eines allgemeinen Modells ist es üblich, Instruction Fine-Tuning zu verwenden, um dem Modell beizubringen, auf Anweisungen und Abfragen zu antworten, anstatt nur Vervollständigungstext zu generieren
Terminologie: „Fine-Tuning“ wird oft als „Supervised Fine-Tuning“ verwendet, aber technisch gesehen ist „Fine-Tuning“ jede Anpassung eines bestehenden Modells. Fortgesetztes Vortraining und Reinforcement Learning from Human Feedback (RLHF) sind ebenfalls Arten von Fine-Tuning.
Fine-Tuning ist bei weitem die schnellste und günstigste Art der Modellkustomisierung. Zum Beispiel kostete für das im Mai 2023 veröffentlichte MPT-7B-Modell das Instruction Fine-Tuning 46 US-Dollar für die Verarbeitung von 9,6 Millionen Tokens, während das Vortraining 250.800 US-Dollar für die Verarbeitung von 1 Billion Tokens kostete.
Daten
Bei der Vorbereitung Ihrer Daten sind Inhalt und Formatierung entscheidend. Ein großer Teil des Fine-Tunings besteht darin, dem Modell beizubringen, welche Eingaben es erwarten soll und welche Ausgaben Sie erwarten. Wie sehen die Abfragen Ihrer Benutzer in Bezug auf Format, Ton, Themenabdeckung oder andere Aspekte aus? Ihre Trainingsdaten sollten diese Erwartungen widerspiegeln.
Datengröße ist ein häufiges Thema und hängt letztendlich vom Anwendungsfall ab. In einigen Fällen haben wir gute Ergebnisse beim Fine-Tuning auf winzigen Datensätzen mit Hunderten oder Tausenden von Beispielen erzielt, aber einige Anwendungen erfordern 10.000 oder 100.000 Beispiele. Beginnen Sie klein, um Ihren Plan zu validieren, und skalieren Sie dann iterativ hoch, indem Sie Ihren Trainingsdatensatz bei Bedarf erweitern.
Synthetische Daten können für SFT nützlich sein, am häufigsten zur Erweiterung eines zu kleinen Satzes von „echten“ Daten. Ein LLM kann aufgefordert werden, synthetische SFT-Daten zu generieren, die Beispielen aus Ihren echten Daten ähneln.
Siehe auch die Dokumentation zur Datenvorbereitung für Databricks Model Training.
Modelle
Früher in dieser Anleitung haben wir empfohlen, standardmäßig die von Databricks Model Training unterstützten Modelle zu verwenden und Modelle auf ihr Potenzial für Ihren Anwendungsfall zu testen. Ein gutes Beispiel dafür kam von MPT. Obwohl MPT nicht mit Blick auf Japanisch trainiert wurde, führte ein schneller Fine-Tuning-Test mit 100 japanischen Prompt-Antwort-Beispielen zu einem überraschend effektiven Modell für einen Kunden. Dieser schnelle Test validierte den Ansatz und ebnete den Weg für ein größeres Fine-Tuning.
Berücksichtigen Sie bei der Auswahl einer Modellgröße, dass Sie mit einem überdimensionierten Modell beginnen. Beim Tuning mit einem kleinen Datensatz ist ein größeres Modell wahrscheinlich besser geeignet, gute Ergebnisse zu erzielen als ein kleineres Modell. Der Start mit einem großen Modell kann Ihnen das Potenzial Ihrer Daten und Ihres Anwendungsfalls aufzeigen, und SFT ist relativ günstig. Nachdem Sie Potenzial gesehen haben, können Sie mit kleineren Modellen und mehr Daten testen.
Sie können SFT entweder auf Basis- oder auf Instruct/Chat-Varianten von Modellen ausführen. Standardmäßig empfehlen wir die Verwendung einer Instruct/Chat-Variante, insbesondere wenn Sie einen kleinen Datensatz haben. Wenn Sie ein fortgesetztes Vortraining durchgeführt haben, um ein benutzerdefiniertes Basismodell zu erstellen, können Sie SFT auf Ihrem benutzerdefinierten Basismodell ausführen.
Databricks Model Training
Databricks Model Training bietet einfache Schnittstellen (UI und API) für Supervised Fine-Tuning-Aufgaben. Berücksichtigen Sie neben den Tipps zu Daten und Modellen, die bereits in dieser Anleitung enthalten sind:
- Aufgabe: SFT-Aufgaben können auf verschiedene Weise spezifiziert werden, abhängig von Ihrem erwarteten Abfrageformat. Beachten Sie, dass wir standardmäßig die Chat-Vervollständigungsformatierung empfehlen, auch für Aufgaben zur Befolgung von Anweisungen, um gängigen Standards zu entsprechen.
- Konfiguration: Beim Iterieren ist die Lernrate der erste Hyperparameter, der optimiert werden muss. Probieren Sie ein Raster von Raten aus und zoomen Sie dann in ein Raster mit feineren Lernraten, die um die besten anfänglichen Raten zentriert sind, ähnlich wie beim Anpassen von Lernraten in traditionellen Machine-Learning-(ML)-Algorithmen. Berücksichtigen Sie auch die Anpassung der Trainingsdauer (Epochen oder Token) basierend auf Diagrammen des Lernfortschritts. Einige Fine-Tuning-Aufgaben erfordern wenige Epochen, während andere von 50+ Epochen profitieren.
- Evaluierung: Ein Evaluierungsdatensatz angeben, damit Databricks Model Training erste Evaluierungen („Unit-Tests“) berechnen kann. Selbst ein winziger Datensatz mit 50 Abfrage-Antwort-Paaren kann Ihnen ein Signal geben, obwohl größere und vielfältigere Datensätze besser sind. Verwenden Sie Databricks MLflow für gründlichere Evaluierungen, insbesondere da der Trainingsverlust (oder die Genauigkeit) möglicherweise nicht gut mit den Evaluierungen der Endbenutzer korreliert.
Mehr über supervised Fine-Tuning
Wir empfehlen standardmäßig Databricks Model Training für einen einfachen, effizienten Workflow. Wenn Sie jedoch eine nicht unterstützte Modellarchitektur verwenden müssen oder individuellere Tuning-Methoden benötigen, können Sie vollständig benutzerdefinierten Code auf Databricks GPU-beschleunigten Clustern (allgemeine Rechenleistung) und Databricks Model Training ausführen.
Diese Anleitung befasst sich nicht mit Parameter-Efficient Fine-Tuning (PEFT), einer Familie von Techniken wie Low-Rank Adaptation (LoRA), um Fine-Tuning und Inferenz effizienter zu gestalten. Weitere Beschreibungen und Beispiele dieser Techniken finden Sie in diesem Blog, diesem Blog oder Hugging Face PEFT.
Fortgesetztes Pretraining
Supervised Fine-Tuning (SFT) ist nicht dafür konzipiert, einem Modell das Verständnis einer neuen Domäne beizubringen. Um ein Modell an eine neue Sprache, eine Nische oder einen anderen spezifischen Bereich anzupassen, können Praktiker auf fortgesetztes Pretraining (CPT) zurückgreifen. CPT ähnelt dem Pretraining, außer dass Sie ein bestehendes vortrainiertes Modell nehmen und dann den Pretraining-Prozess mit neuen Daten fortsetzen. Nach CPT zur Anpassung an eine neue Domäne wird das Modell im Allgemeinen durch supervised Fine-Tuning an spezifische Aufgaben angepasst.
Häufige Anwendungsfälle sind:
- Sprachen: Allgemeine Modelle haben in ihren Trainingsdaten oft viele natürliche Sprachen gesehen, aber sie können bei allen Sprachen außer den Top-Sprachen schwach sein. CPT kann das Verständnis eines Modells für eine bestimmte Sprache verbessern.
- Programmierung: Allgemeine Modelle haben in ihren Trainingsdaten oft mindestens einige Programmiersprachen gesehen, aber die Modelle sind möglicherweise nicht primär für das Codieren konzipiert oder verstehen eine bestimmte Programmiersprache möglicherweise nicht gut. CPT kann einem Modell beibringen, wie man in einer bestimmten Programmiersprache codiert.
- Branchen-Domänen: Allgemeine Modelle haben möglicherweise kein tiefgreifendes Wissen über spezifische Themenbereiche wie Molekularbiologie, Umweltrecht oder Finanzvorschriften. CPT kann das Wissen und Verständnis eines Modells für eine bestimmte Domäne verbessern.
Sollte ich supervised Fine-Tuning (SFT) oder fortgesetztes Pretraining (CPT) verwenden, um das Instruction-Following-Modell meines RAG Q&A-Bots zu verbessern?
Beide Techniken können anwendbar sein, aber es hängt davon ab, welche Trainingsdaten Sie haben und was Sie am Modell verbessern möchten. Wenn Sie dem Modell beibringen möchten, auf eine bestimmte Weise zu antworten, verwenden Sie SFT – wenn Sie Abfrage-Antwort-Daten für das Training haben. Wenn das Modell Ihre Domäne oder Sprache nicht versteht, verwenden Sie CPT – wenn Sie eine beträchtliche Menge an Textdaten für das Training haben. Beachten Sie, dass Sie nach CPT wahrscheinlich SFT ausführen müssen, um dem Modell das Antworten auf Abfragen erneut beizubringen.
Kann ich SFT oder CPT verwenden, um meinem Modell neues Wissen und Fakten beizubringen?
Ja, beide Techniken können etwas Wissen vermitteln, aber CPT ist besser geeignet. Unabhängig davon müssen Sie möglicherweise RAG verwenden, um Ihr KI-System robust zu machen, indem Sie Antworten mit Quelldaten verankern.
Daten
Wenn Sie überlegen, welche Daten Sie für CPT benötigen, denken Sie an Prinzip 2 („datengetrieben“). Was möchten Sie am ursprünglichen Modell verbessern? Ihre Daten sollten die Domäne, Sprache, Wissen usw. darstellen, die Sie dem Modell vermitteln möchten. Für einen bestimmten Anwendungsfall bedeutet dies wahrscheinlich, CPT auf Ihren proprietären Unternehmensdaten auszuführen, die für den Anwendungsfall relevant sind – Ihre internen Wissensdatenbankdokumente, relevante Forschungsarbeiten der letzten 20 Jahre usw. Für ein allgemeineres Modell werden unsere Anleitungen für Daten ähnlicher denen für Pretraining, bei denen Sie mehrere Datensätze auswählen können, um die verschiedenen für Ihren Anwendungsfall wichtigen Fähigkeiten darzustellen.
Tipp: Vergessen vs. Lernen. Wenn Sie CPT testen, denken Sie daran, dass es Kompromisse zwischen dem Vergessen von altem Wissen und dem Erlernen von neuem Wissen gibt. Ihr Ziel ist es, das Modellverhalten so zu verschieben, dass es Ihre CPT-Trainingsdaten nachahmt, aber das kann bedeuten, Aspekte der ursprünglichen Vortrainingsdaten zu vergessen. Stellen Sie daher sicher, dass sowohl Ihre CPT-Trainingsdaten als auch Ihre Evaluierungssuite die für Sie wichtigen Domänen abdecken.
Für das Datenformat sind Ihre Daten „roher“ Text. Das heißt, Sie führen CPT durch Vorhersage des nächsten Tokens durch, genau wie beim Pretraining.
Für die Datengröße kann CPT von der Optimierung eines Modells mit wenigen Token bis zur signifikanten Änderung eines Modells mit vielen Token reichen. „Wenige“ und „viele“ hängen von der Modellgröße ab, aber eine vernünftige Schätzung sind Milliarden von Token für moderne mittelgroße LLMs. Eine Faustregel besagt, dass CPT mindestens ~1 % der Größe des ursprünglichen Trainingsdatensatzes erfordert.
Benötige ich sowohl Rohdaten für CPT als auch Prompt-Antwort-Daten für SFT?
Wenn Sie CPT gefolgt von SFT ausführen, dann ja. Wenn Sie jedoch Daten für CPT, aber wenig Daten für SFT haben, können Sie Ihren kleinen SFT-Datensatz mit Abfrage-Antwort-Daten aus anderen SFT-Datensätzen oder synthetischen Daten erweitern.
Synthetische Daten können für CPT nützlich sein, insbesondere für die Destillation, bei der ein großes, leistungsfähiges Modell verwendet wird, um Daten zum Trainieren eines kleineren Modells zu generieren. Destillation kann helfen, kleinere, schnellere, kostengünstigere Modelle zu erstellen und Ihre nicht-synthetischen Daten für Ihre Anwendungsfälle zu ergänzen.
Siehe auch die Dokumentation zur Vorbereitung von Daten für Databricks Model Training.
Modelle
Genau wie bei SFT empfehlen wir standardmäßig die Verwendung der von Databricks Model Training unterstützten Modelle und das Testen von Modellen auf ihr Potenzial für Ihren Anwendungsfall.
Unsere Empfehlungen zur Optimierung eines Basismodells im Vergleich zu einer Instruct/Chat-Variante und zur Ausführung von SFT nach CPT sind miteinander verknüpft. Der häufigste Weg und unsere Standardempfehlung ist die Ausführung von CPT auf einem Basismodell, gefolgt von SFT für Instruction- oder Chat-Fine-Tuning. Es gibt jedoch Nuancen:
- Basis- vs. Instruct/Chat-Variante: Am häufigsten wird CPT auf dem Basismodell ausgeführt. Die Ausführung von CPT auf einem großen Datensatz einer Instruct- oder Chat-Variante kann dazu führen, dass dieses Modell einige seiner Instruction-Following- oder Chat-Fähigkeiten verliert.
- SFT nach CPT: Wenn Sie CPT auf einer großen Datenmenge ausführen, werden Sie wahrscheinlich SFT anschließen. Wenn Sie jedoch CPT auf einem Instruction-Following- oder Chat-Modell mit einer kleinen Datenmenge ausführen, benötigen Sie möglicherweise danach kein SFT mehr. Wir haben einige Kunden gesehen, die dies getan und das resultierende Modell dann direkt in ihren Anwendungen verwendet haben.
Databricks Model Training
Databricks Model Training bietet einfache Schnittstellen (UI und API) für CPT. Die Tipps für SFT, die zuvor in dieser Anleitung erwähnt wurden, gelten größtenteils auch für CPT. Praktischerweise kann die Model Training-Funktion verwendet werden, um sowohl CPT als auch SFT auszuführen.
Ihre Testpyramide aus der vorherigen Evaluierungsdiskussion erfordert robustere und allgemeinere Tests, da CPT das Modell grundlegender verändern kann als SFT. Wenn Sie CPT skalieren, kann Ihre Testpyramide eher einer Pretraining-Testsuite ähneln.
Mehr über CPT
Wenn Ihre CPT-Workloads stärker angepasst und größer werden, möchten Sie möglicherweise auch den unten besprochenen Pretraining-Stack erkunden.
CPT ist nützlich für das Testen von Daten für Pretraining. Wenn Ihre CPT-Daten eine neue Domäne abdecken (z. B. eine neue Programmiersprache), zeigt der Erfolg mit CPT an, dass die Daten als Teil eines Pretraining-Datensatzes nützlich sein könnten.
Pretraining
Angenommen, Ihre GenAI-Anwendung hat das Continued Pretraining durchlaufen und Sie glauben, dass das Pretraining eines vollständig benutzerdefinierten Modells der nächste Schritt zur Verbesserung Ihrer Anwendung ist. Dieser Abschnitt skizziert den Prozess und die Best Practices auf hoher Ebene, aber in der Praxis sollten Sie den Pretraining-Prozess mit Ihrem Databricks-Team durchlaufen.
Sollten Sie jemals direkt mit dem Pretraining beginnen?
Nein. Selbst wenn regulatorische oder andere Einschränkungen erfordern, dass Sie ein neues Modell erstellen, das Sie vollständig besitzen, ist es besser, zuerst auf niedrigeren Stufen der Anpassungsleiter zu prototypisieren. Dies ermöglicht es Ihnen, kostspieligere und komplexere Pretraining-Läufe zu de-risken.
Was sind die Schritte für das Pretraining?
Die Realität ist, dass Pretraining ein iterativer, adaptiver Prozess ist, aber die allgemeinen Schritte beim Pretraining umfassen:
- Arbeiten Sie sich zuerst durch Fine-Tuning und Continued Pretraining. Machen Sie Ihre Hausaufgaben!
- Bereiten Sie Datensätze vor. Dies geschieht während Schritt 1, bei dem CPT Ihnen hilft, die Nützlichkeit bestimmter Datensätze zu testen.
- Trainieren Sie ein Basismodell, das Textvervollständigung durchführen kann. Dies beinhaltet die Überwachung des Trainings, die Anpassung des Laufs währenddessen und adaptive Techniken wie Curriculum Learning, um die Datenmischung anzupassen.
- Führen Sie Instruction- oder Chat-Fine-Tuning durch, um eine Instruct/Chat-Variante zu erstellen.
- Verwenden Sie möglicherweise Techniken wie Reinforcement Learning from Human Feedback (RLHF), um das Modell weiter zu optimieren.
- Bewerten Sie Ihre Modelle in jedem der obigen Schritte.
Diese kurze prozedurale Zusammenfassung betont Due Diligence und Evaluierung aufgrund der relativ hohen Kosten des vollständigen Pretrainings. Erinnern Sie sich an das zuvor genannte Beispiel des MPT-7B-Modells, dessen Pretraining 5452-mal mehr kostete als Instruction Fine-Tuning.
Daten
Ihre Wahl und Behandlung von Daten spielen eine große Rolle bei der Bestimmung des Erfolgs Ihrer Pretraining-Läufe.
Welche Daten?
Ihre Datenmischung sollte sorgfältig ausgewählt werden, um Ihre Zielanwendung zu repräsentieren.
- So wie Auswertungen nach den Fähigkeiten aufgeschlüsselt werden müssen, die Ihr Modell haben soll, überlegen Sie, was jeder Datensatz, den Sie zum Pretraining mitbringen, dem Modell beibringen wird. Sie können die Auswirkungen dieser Datensätze im Voraus mit Continued Pretraining testen.
- Nur wenige leistungsstarke Modelle veröffentlichen Details zu ihren Datenmischungen. Einige ältere Modelle haben veröffentlichte Listen (z. B. MPT, LLaMA, OLMo). Sehen Sie sich auch diese Diskussion über Datenmischungen an.
- Sie werden wahrscheinlich öffentliche und proprietäre Datensätze mischen. Richtig geprüfte öffentliche Datensätze können einige Ihrer Trainingsanforderungen erfüllen, z. B. Sprachfähigkeiten, allgemeines Wissen und einige spezifische Fähigkeiten vermitteln. Proprietäre Datensätze verleihen Ihren Modellen einen Wettbewerbsvorteil, der niemand anderem zur Verfügung steht.
Datenmenge und Datenqualität sind wichtig, aber zu unterschiedlichen Zeiten. Es ist üblich, mit dem Pretraining auf „allen Daten“ mit lockereren Qualitätskontrollen zu beginnen. Anfangs führen mehr Tokens zu mehr Erlernen grundlegender Sprachfähigkeiten. Später, während des Pretrainings, ist es jedoch üblich, die Datenmischung zu einem kleineren, qualitativ hochwertigeren Satz zu ändern. „Hohe Qualität“ hat keine akademische Definition, aber intuitiv bedeutet es, dass es mit Common-Sense-Techniken kuratiert wurde. Weitere Informationen zur Datenaufbereitung finden Sie hier.
Wie viele Daten?
- Ihre Datengröße sollte unter Berücksichtigung der Modellgröße und -architektur gewählt werden.
- Die „Chinchilla“-Faustregel ist die bekannteste: # Tokens = 20 * # Parameter. Um die Inferenzkosten zu senken, empfehlen wir, ein kleineres Modell mit mehr Daten zu trainieren, um eine ähnliche Generierungsqualität zu erzielen, gemäß den Ergebnissen dieses LLaMA-Papiers.
- Mixture of Experts (MoEs)-Architekturen können diese Berechnung ändern und erfordern oft weniger Daten für eine gegebene Modellgröße. Verwenden Sie für MoEs die Anzahl der aktiven Parameter (nicht die Gesamtzahl der Parameter), um diese Berechnung durchzuführen.
- Beachten Sie, dass einige Aufgaben schwieriger sind als andere. Zum Beispiel benötigen 7B-Parameter-Modelle mindestens 2 Billionen Tokens an Trainingsdaten, um den HumanEval-Coding-Benchmark zu bewältigen.
Wie sollten Daten vorbereitet werden?
- Herunterladen und Parsen: Sie müssen Daten im Allgemeinen selbst beschaffen. Nur wenige Anbieter bieten Internet-Daten in vorab heruntergeladener Form an, und die regulatorischen Anforderungen können je nach Kunde variieren.
- Bereinigung: Während Pretraining von großen Mengen qualitativ minderwertiger Daten profitieren kann, ist es lohnenswert, die Datenqualität zu verbessern. Zum Beispiel schätzt dieses RefinedWeb-Papier, dass etwa 11 % von Common Crawl nützlich sind. Datenbereinigung für Pretraining ist ein großes, unübersichtliches Thema mit viel aktiver Forschung. Sehen Sie sich dieses Papier für eine ausgezeichnete Übersicht über gängige Schritte an, einschließlich:
- Sprachfilterung, um Text auf die primären Sprachen von Interesse zu beschränken
- Heuristische Filterung, um Boilerplate-Text, zu kurze oder zu lange Dokumente, nicht-natürliche Sprachtexte usw. zu entfernen
- Qualitätsfilterung, um Text zu identifizieren, der wahrscheinlich von Menschen geschrieben oder überprüft wurde
- Domänenfilterung, um Text über die interessierenden Domänen zu identifizieren
- Deduplizierung von Inhalten innerhalb oder über Datensätze hinweg
- Filterung von toxischen und expliziten Inhalten basierend auf Herkunft oder Text
- Beachten Sie, dass all diese Techniken Vorbehalte haben. Für jede muss die Filterstärke abgestimmt werden, um Präzision und Recall abzuwägen. Für einige kann der Filter irreführend sein: Duplizierung kann darauf hindeuten, dass Text gültiger oder wichtiger ist, und ein Modell, das noch nie toxische Inhalte gesehen hat, erkennt möglicherweise keine Toxizität und wiederholt daher leicht toxische Benutzereingaben.
- Wie erwähnt, kann frühes Pretraining mehr Daten mit lockereren Qualitätskontrollen verwenden, während späteres Pretraining sich auf sorgfältiger bereinigte Teilmengen von Daten konzentrieren kann.
- Vorkompilierung: Vortokenisierung und Verknüpfung von Daten, um deren Format für das Pretraining zu optimieren, kann die Effizienz verbessern.
Datenverarbeitung ist die ursprüngliche Stärke von Databricks. Nutzen Sie Folgendes:
- Workflows für die Definition von Jobs und Orchestrierung, mit Apache Spark™ und Delta-Optimierungen für die Scale-Out-Verarbeitung
- Delta Lake als Ihr Datenspeicherformat
- Unity Catalog für die Datenverwaltung
- Notebooks, IDE integration und Databricks SQL für Entwicklung und Datenexploration
- Lakehouse Monitoring für die langfristige Überwachung von Datenpipelines und -quellen
Modelle
Während Forscher natürlich neue Modellarchitekturen als große Durchbrüche preisen, gibt es einen Grund, warum die Transformer-Architektur immer noch dominiert, obwohl sie aus dem Jahr 2017 stammt – sie funktioniert wirklich gut. Ebenso empfehlen wir im Allgemeinen, sich an bewährte architektonische Entscheidungen zu halten, wie zum Beispiel:
- Verwenden Sie Standard-Aufmerksamkeitsmechanismen wie quadratische Aufmerksamkeit oder FlashAttention-2 anstelle von weniger getesteten Methoden aus der Forschung
- Erwägen Sie Mixture-of-Experts (MoEs)-Architekturen für effizienteres Training und Inferenz sowie für Arithmetik mit niedrigerer Präzision
- Trainieren Sie Ihren Transformer mit Next-Token-Prediction
Databricks unterstützt das Vortraining auf beliebigen Architekturen, aber wir bieten einfachere Vortrainings-Setups für die am häufigsten empfohlenen Architekturen über Databricks Model Training an, das verwaltete, optimierte Versionen von Tools wie Mosaic LLM Foundry und Mosaic Diffusion bereitstellt. Diese Tools können die Auswahl vereinfachen, indem sie Standard- und gut getestete Standardeinstellungen bieten. Zum Beispiel empfiehlt LLM Foundry ab Juli 2024 FlashAttention-2 als Standard-Aufmerksamkeitsmechanismus und unterstützt MoEs-Architekturen wie DBRX. Für Ihre spezielle Anwendung können wir Sie bei Architekturspezifika beraten.
Was die Modellgröße betrifft, denken Sie daran, klein anzufangen (Prinzip 1). Das Training eines Modells mit 7 Milliarden Parametern kostet etwa 10x weniger als das eines Modells mit 70 Milliarden Parametern und kann Ihre Modellierungsentscheidungen für spätere Skalierungen beeinflussen. Berücksichtigen Sie auch die Latenz- und Kostenbeschränkungen Ihres Anwendungsfalls als Obergrenzen für die potenzielle Modellgröße.
Training-Stack und Infrastruktur
Wenn Ihre Daten und Modellierungsentscheidungen vorbereitet sind, sind Sie möglicherweise bereit für das Vortraining. Dies kann der kostspieligste Schritt sein, den Sie mit GenAI unternehmen, daher die sorgfältige Vorbereitung in den früheren Schritten. Während dieses Schritts ist es entscheidend, robuste Tools und erfahrene Berater einzusetzen, um das Vortraining reibungslos ablaufen zu lassen.
Vortrainingsläufe sind mit vielen Herausforderungen verbunden. Die Databricks-Plattform bewältigt viele dieser Herausforderungen automatisch für den Benutzer.
Herausforderung | Databricks |
Datenladen: Möglicherweise müssen Sie Billionen von Tokens laden. | Databricks bietet schnelle Start- und Wiederherstellungszeiten. |
Skalierung und Optimierung: Möglicherweise müssen Sie von 10 auf 1000 GPUs skalieren. Es gibt viele Techniken zur Optimierung der Trainingsleistung. | Databricks bietet nahtlose Skalierung durch Datenparallelität und FSDP sowie eine Bibliothek von komponierbaren Optimierungen. Es erreicht erstklassige Model FLOPS Utilization (MFU). |
Fehlerwiederherstellung: Sie können mit etwa 1 Infrastrukturausfall pro 1000 GPU-Tagen in den meisten Clouds rechnen. Vortrainingsjobs können Verlustspitzen oder Divergenzen aufweisen. | Databricks erkennt Fehler automatisch und führt schnelle Neustarts durch. Der Training-Stack reduziert auch Verlustspitzen. |
Determinismus: Verteiltes Laden und Trainieren von Daten erschwert den Determinismus, aber er ist wertvoll für die Wiederherstellung und Reproduzierbarkeit. | Die Datenlade- und Trainingsalgorithmen von Databricks machen das Vortraining wesentlich reproduzierbarer. |
Der Databricks Training-Stack reicht von der Hardware bis zur Workload-Verwaltung. Die folgende Tabelle listet die wichtigsten Komponenten auf, die Sie zuerst lernen sollten.
Phase | Databricks-Komponente | Details |
Daten laden | Bietet schnelles, reproduzierbares Streaming von Trainingsdaten aus dem Cloud-Speicher, einschließlich schneller Starts und Wiederaufnahmen. | |
Training | Bietet komponierbare Best Practices und Techniken für effizientes, verteiltes Training. | |
Workflow-Konfiguration | Ermöglicht die einfache Definition von Workflows, einschließlich Datenaufbereitung, Training, Fine-Tuning und Evaluierung. Databricks kann Standardkonfigurationen bereitstellen, um Ihnen den Einstieg in das Vortraining gängiger Architekturen zu erleichtern. | |
Experiment-Tracking | Verfolgt Evaluierungs- und andere Metriken während der Vortrainingsläufe. Databricks unterstützt auch Weights & Biases. |
Ihr Anwendungsfall kann den von LLM Foundry als Konfigurations-"Rezepte" vorgegebenen, ausgetretenen Pfaden folgen, in diesem Fall kann Ihr Workflow sehr konfigurationsgesteuert sein. Oder, wenn Sie benutzerdefiniertere Architekturen oder Code benötigen, können Sie sich auf niedrigere Ebenen des Stacks konzentrieren, wie z. B. MCLI, und direkter mit der Databricks-Infrastruktur arbeiten.
Berechnung und Kosten
Bevor Sie ein Modell vortrainieren, ist es wichtig, die Kosten abzuschätzen. Die Kosten für das Vortrainings-Compute sind oft einfach zu schätzen, da sie auf der Schätzung der GPU-Stunden basieren, abhängig von der Daten- und Modellgröße. Ihr Databricks-Team kann genaue Schätzungen liefern, aber stellen Sie für jeden Anbieter sicher, dass Sie zwei Schlüsselberechnungen verstehen:
FLOPS = 6 x Parameter x Tokens
Diese Faustregel besagt, dass sich die Rechenleistung (und die Kosten) linear mit der Modellgröße und der Datengröße skalieren. Beachten Sie, dass sich „Parameter“ bei spärlichen Architekturen wie MoEs auf „aktive Parameter“ beziehen.
Model FLOPS Utilization (MFU) = durchschnittliche GPU-Auslastung in der Praxis
MFU ist in der Praxis nie 100 %, und oft weit darunter. Verschiedene Modelle und Datentypen können unterschiedliche MFUs erreichen. Der Databricks-Stack ist darauf optimiert, eine leistungsstarke MFU zu erzielen.
Was ist mit Epochen?
Das Training für N Epochen kostet N Mal so viel wie 1 Epoche. Beim Vortraining ist es jedoch üblich, eine einzige Epoche zu verwenden, obwohl Sie einige wichtige hochwertige Daten in Ihrem Training wiederholen können. Dies unterscheidet sich von den vielen Epochen, die in traditionellerem Deep Learning verwendet werden. Weitere Hintergründe finden Sie in diesem Paper.
Zusätzlich zu den Kosten für das Vortrainings-Compute sollten Sie auch Schätzungen für Folgendes vornehmen:
- Datenkosten, einschließlich Kauf, Kuratierung und Kennzeichnung
- Inferenzkosten
Während des Vortrainings
Sobald Sie mit dem Vortraining beginnen, funktioniert es auf Databricks möglicherweise „einfach“, aber es ist dennoch wichtig, das Training zu überwachen und zu wissen, wie man lernt, Fehler behebt oder verbessert. Ihr Databricks-Team kann Ihnen bei der Überwachung und Fehlerbehebung helfen.
Überwachung umfasst zwei Hauptbereiche:
- Infrastruktur: Databricks Training kümmert sich für Sie um die meisten Infrastrukturprobleme. Zum Beispiel werden automatisch Checkpoints erstellt und das Training fortgesetzt, wenn GPUs, Netzwerke oder andere Infrastruktur ausfallen. Es ist sinnvoll, die Auslastung zu überwachen, insbesondere bei nicht standardmäßigen Konfigurationen.
- Lernfortschritt: Verlust und andere Metriken für Trainings- und Evaluierungsdaten sollten überwacht werden, um Probleme mit Daten und Konfigurationen zu erkennen. Die häufigsten Anzeichen, auf die man achten sollte, sind Verlustspitzen und Divergenz. In Databricks Training empfehlen wir die standardmäßige Protokollierung in MLflow Experiments für die Live-Überwachung und die nachträgliche Überprüfung.
Fehlerbehebung erfordert am häufigsten Anpassungen bei:
- Konfigurationen: Wenn Ihre Konfigurationen schlecht eingestellt sind, treten diese Probleme oft früh während des Trainings auf. Die Lernrate ist die häufigste Konfiguration, die Anpassungen erfordert.
- Daten: Ein häufiges Trainingsproblem ist beispielsweise, dass der Verlust aufgrund von falsch gemischten Datensätzen ansteigt. Databricks Training vereinfacht das Mischen über die Mosaic Streaming-Bibliothek, aber das Mischen verursacht Kosten. Daher unterstützt Streaming verschiedene Mischeinstellungen, um Qualitäts-Kosten-Abwägungen zu unterstützen. Wenn Sie Verlustspitzen sehen, ist es möglich, dass die Einstellung stärkerer Mischeinstellungen in Streaming Spitzen verhindert. Wenn Ihre Daten beispielsweise aus verschiedenen Buckets (Domänen, Sprachen usw.) stammen und nicht richtig gemischt werden, ist die Wahrscheinlichkeit von Verlustspitzen höher.
Curriculum Learning: Vortraining läuft oft nicht auf einem einzigen, homogenen Datensatz. Das endgültige Modell kann oft durch Variation der Datenmischung während des Trainingsprozesses verbessert werden, und die häufigste Technik dafür ist Curriculum Learning, bei dem qualitativ hochwertigere und gezieltere Datensätze später im Trainingsprozess in der Datenmischung betont werden. Die Datenmischungen können im Voraus festgelegt werden, oder die Datenmischung kann manuell angepasst werden, um das Modell in bestimmten Bereichen zu stärken.
Nach dem Vortraining
Nach dem Vortraining können weitere Schritte erforderlich sein, um ein Modell für Endanwendungen vorzubereiten, wie zum Beispiel:
- Weiteres Curriculum Learning oder fortgesetztes Vortraining zur Feinabstimmung des Modells
- Überwachtes Fine-Tuning, z. B. für Instruction-Following oder Chat
- Reinforcement Learning from Human Feedback (RLHF), eine fortgeschrittene Technik zur Feinabstimmung eines Modells, um menschliche Präferenzen anzupassen. Dies kann sehr wirkungsvoll, aber schwierig richtig umzusetzen sein und ist nicht für alle Anwendungen notwendig. Für viele Anwendungen reichen überwachtes Fine-Tuning oder Guardrails aus.
- Iteratives Anwenden der oben genannten Schritte, basierend auf Endbenutzerbewertungen des Modells oder der Anwendung
Die Zukunft
Das Tempo der GenAI-Entwicklung verlangsamt sich nicht. GPUs und andere spezialisierte Hardware werden schneller und günstiger. Software-Stacks werden sich verbessern. Neue Modellarchitekturen und Trainingstechniken werden von der Forschung in die Praxis übergehen. Was können Sie tun, um vorbereitet zu sein?
Mit Databricks können Sie viele Entwicklungen standardmäßig nutzen. Databricks Model Training, Model Serving und andere Funktionen werden weiterhin die neuesten Top-Modelle unterstützen. Neue Trainings- und Inferenztechniken werden im Hintergrund integriert. Für größere, komplexere Workloads unterstützt Databricks die vollständige Anpassung, und die modernsten Workloads werden in enger Zusammenarbeit mit dem Mosaic Research Team durchgeführt.
Konzentrieren Sie sich in Ihrem Unternehmen darauf, flexible, anpassbare Workloads jetzt und in Zukunft zu unterstützen:
- Entwickeln Sie Ihre KI-Infrastruktur. Richten Sie die Governance von Modell-APIs über ein KI-Gateway ein. Richten Sie Sicherheitsprozesse mit einem KI-Sicherheitsframework ein. Standardisieren und vereinheitlichen Sie Daten- und KI-Governance unter Unity Catalog. Entwickeln Sie sowohl die innere Schleife mit dem Agent Framework als auch die äußere Schleife mit Model Training. Entwickeln Sie Ihre MLOps-Praxis, einschließlich robuster Model Serving und Monitoring.
- Entwickeln Sie Ihre KI-Expertise. Arbeiten Sie mit Ihrem Databricks-Team zusammen, um ein Center of Excellence (CoE) für KI zu entwickeln. Nutzen Sie Databricks Training, um Teams auf rollenspezifischen Lernpfaden zu begleiten.
- Entwickeln Sie Ihr geistiges Eigentum. Dieses IP umfasst nicht nur benutzerdefinierte Modelle, sondern vor allem Ihre Unternehmensdaten. Sammeln Sie Daten aus aktuellen Anwendungen und von Benutzern, verfolgen Sie die Herkunft und achten Sie auf Vorschriften und Lizenzen. Diese Daten werden alle Ihre GenAI-Anpassungen antreiben – sowohl RAG in der inneren Schleife als auch Tuning und Vortraining in der äußeren Schleife.
Ressourcen
Kurse
- Nehmen Sie am selbstgesteuerten Tutorial „Get Started With Generative AI“ teil und erhalten Sie ein Databricks-Zertifikat
- Generative AI Fundamentals (Databricks Academy)
- Generative AI Engineering with Databricks (Präsenztraining und Databricks Academy)
- Suchen Sie nach neuen Kursen auf Databricks Training und Databricks Academy
Lektüre
- Das große Buch über Generative AI für eine Sammlung von Blogbeiträgen, die verschiedene Aspekte der Entwicklung von generativen KI-Modellen und -Systemen detailliert behandeln
- Ein kompakter Leitfaden zu Retrieval Augmented Generation (RAG) für einen detaillierten Einblick in die Erstellung von generativen KI-Anwendungen mit LLMs, die mit Unternehmensdaten angereichert wurden
- Mosaic Research Blogbeiträge
- Das große Buch über MLOps: Zweite Auflage für einen detaillierten Einblick in MLOps mit Databricks, einschließlich LLMOps
- Databricks-Seite für eine Produktübersicht, Details zu Funktionen und Links zu vielen Ressourcen
- Databricks-Dokumentation für GenAI für AWS, Azure und GCP
Data + AI Summit 2024 Vorträge
- Anpassen Ihrer Modelle: RAG, Fine-Tuning und Pretraining
- In den Gräben mit DBRX: Erstellung eines State-of-the-Art Open-Source-Modells
Über Databricks
Databricks ist das Unternehmen für Daten und KI. Mehr als 10.000 Organisationen weltweit – darunter Block, Comcast, Condé Nast, Rivian, Shell und 70 % der Fortune 500 – verlassen sich auf die Databricks Data Intelligence Platform, um die Kontrolle über ihre Daten zu übernehmen und sie mit KI nutzbar zu machen. Databricks hat seinen Hauptsitz in San Francisco, mit Niederlassungen auf der ganzen Welt, und wurde von den ursprünglichen Entwicklern von Lakehouse, Apache SparkTM, Delta Lake und MLflow gegründet. Um mehr zu erfahren, folgen Sie Databricks auf LinkedIn, X und Facebook.
Kontaktieren Sie uns für eine personalisierte Demo:
databricks.com/contact
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.