Orchestrate Production dbt Projects on the Lakehouse With Databricks Workflows
by Bilal Aslam and Lennart Kats
We are delighted to announce that Databricks Workflows, the highly reliable lakehouse orchestrator, now supports orchestrating dbt projects in public preview. This preview allows data teams to coordinate dbt projects along with all the capabilities of the lakehouse, from notebooks to ML models. This feature makes it simple for users of open source dbt to transform data using SQL and monitor and maintain data and ML pipelines across the lakehouse.
When a job runs, your dbt project is retrieved from a Git repository, a single-node cluster is built, and dbt-core and project dependencies are installed on it. The SQL generated by dbt is run on a serverless SQL warehouse, providing easy debugging and great performance. There are also robust and operational capabilities offered, such as the ability to repair failed runs and send alerts via Slack or a webhook destination when a dbt task fails, not to mention the ability to manage such jobs through the Jobs API.
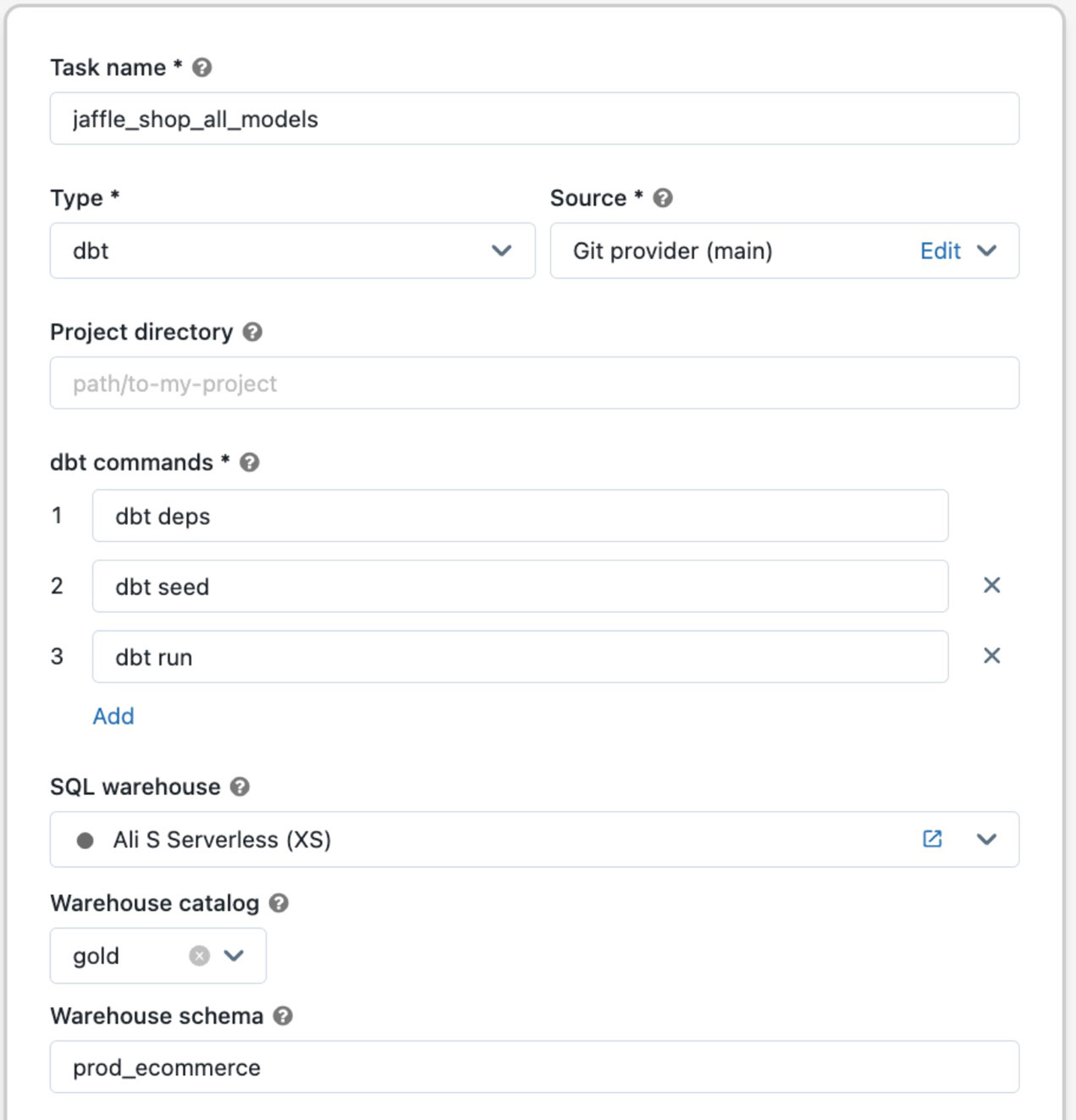
To get started with dbt on Databricks, simply run “pip install dbt-databricks.” This installs the open source dbt-databricks package built together with dbt Labs and other contributors. You can follow our detailed guide to get started with an example project that you can run on a SQL warehouse. Once you commit your source code to a Git repository, you can use the new dbt task type to execute your dbt models in production (see our docs for Azure, AWS, coming soon for GCP). This feature is available in all regions that support serverless SQL warehouses (Azure, AWS).
We are excited about the future of dbt on Databricks Workflows. We look forward to expanding the availability of this preview in more regions, and offering additional compute options. We would love to talk to you at dbt Coalesce, where we hope to meet you at the Databricks booth. In the meantime, we would love to hear your feedback on this new capability.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.