Save Time and Money on Data and ML Workflows With “Repair and Rerun”
Databricks Jobs is the fully managed orchestrator for all your data, analytics, and AI. It empowers any user to easily create and run workflows with multiple tasks and define dependencies between tasks. This enables code modularization, faster testing, more efficient resource utilization, and easier troubleshooting. Deep integration with the underlying lakehouse platform ensures workloads are reliable in production while providing comprehensive monitoring and scalability.
To support real-life data and machine learning use cases, organizations need to build sophisticated workflows with many distinct tasks and dependencies, from data ingestion and ETL to ML model training and serving. Each of these tasks needs to be executed in a specific order.
But when an important task in a workflow fails, it impacts all the associated tasks downstream. To recover the workflow you need to know all the tasks impacted and how to process them without reprocessing the entire pipeline from scratch. The new “Repair and Rerun” capability in Databricks jobs is designed to tackle exactly this problem.
Consider the following example which retrieves information about bus stations from an API and then attempts to get the real-time weather information for each station from another API. The results from all of these API calls are then ingested, transformed, and aggregated using a Delta Live Tables task.

During normal operation this workflow will run successfully from beginning to end. However, what happens if the task that retrieves the weather data fails? Perhaps the weather API is temporarily unavailable for some reason. In that case, the Delta Live Tables task will be skipped because an upstream dependency failed. Obviously we need to rerun our workflow, but starting the entire process from the beginning will cost time and resources to reprocess all the station_information data again.
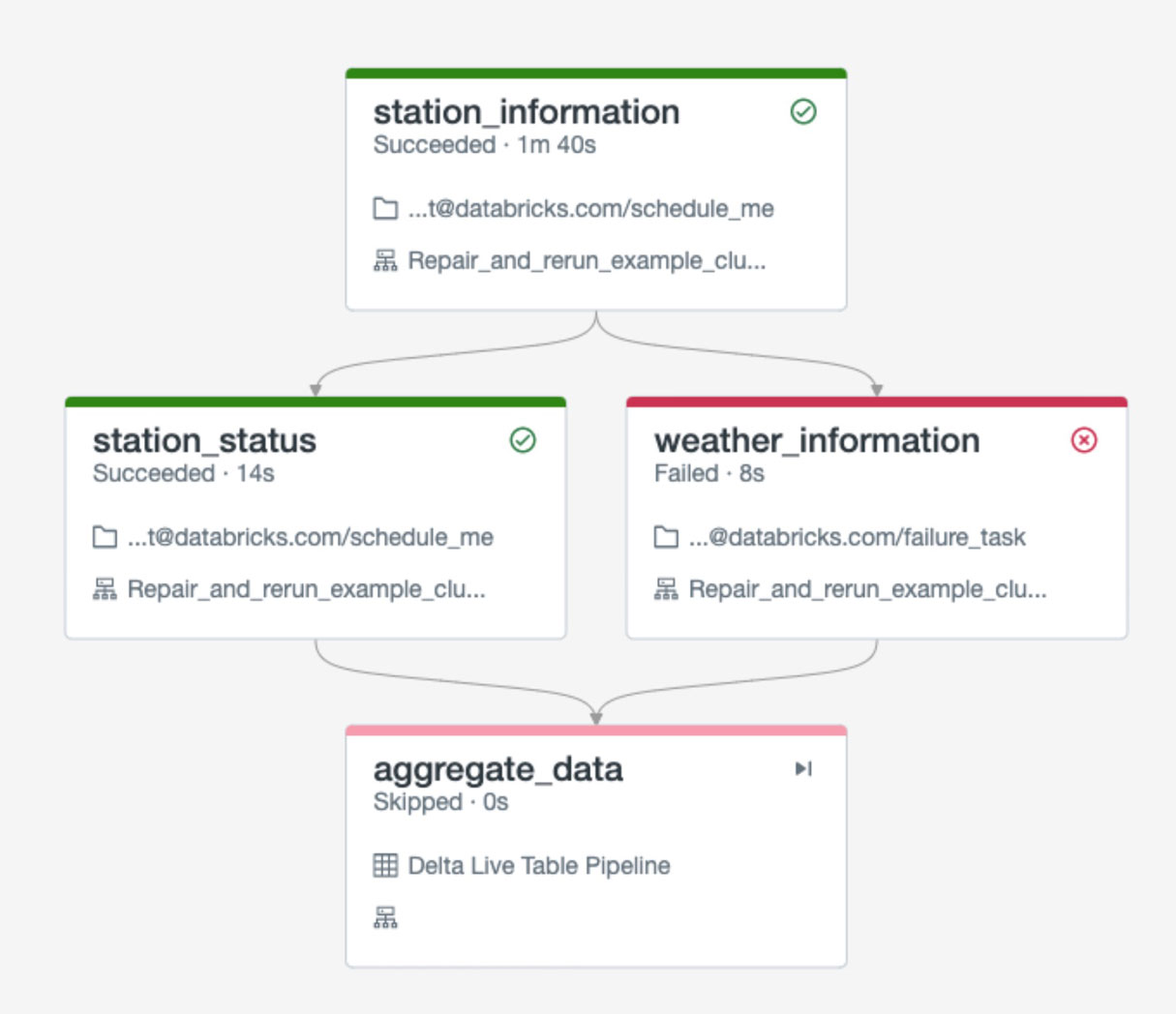
The newly-launched “Repair and Rerun” feature not only shows you exactly where in your job a failure occurred, but letsyou to rerun all of the tasks that were impacted. This saves significant time and cost as you don’t need to reprocess tasks that were already successful.
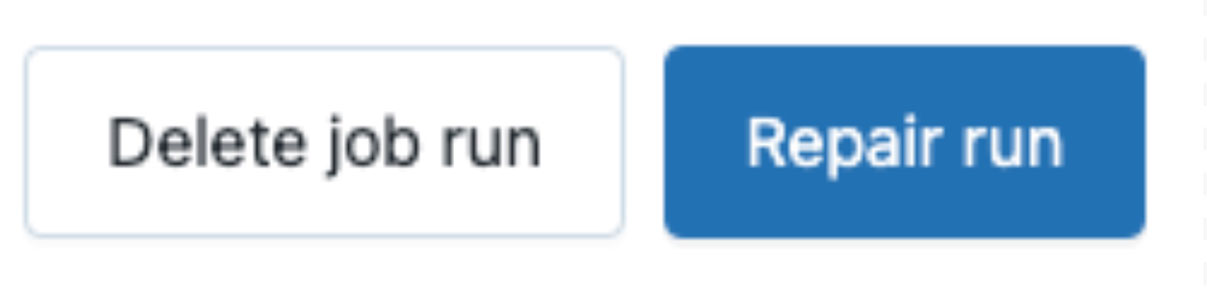
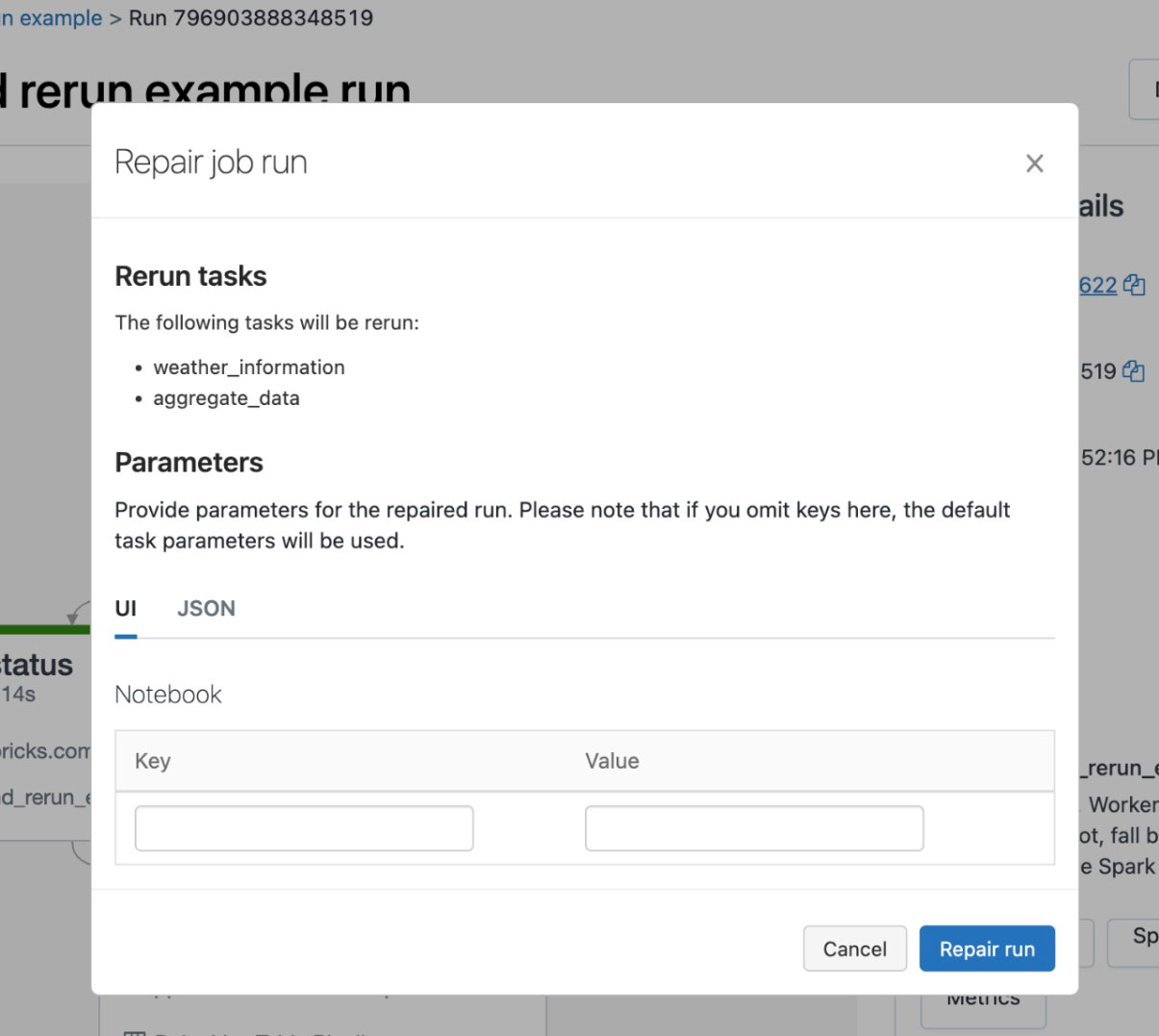
In the event that a job run fails, you can now click on “Repair run” to start a rerun. The popup will show you exactly which of the remaining tasks will be executed
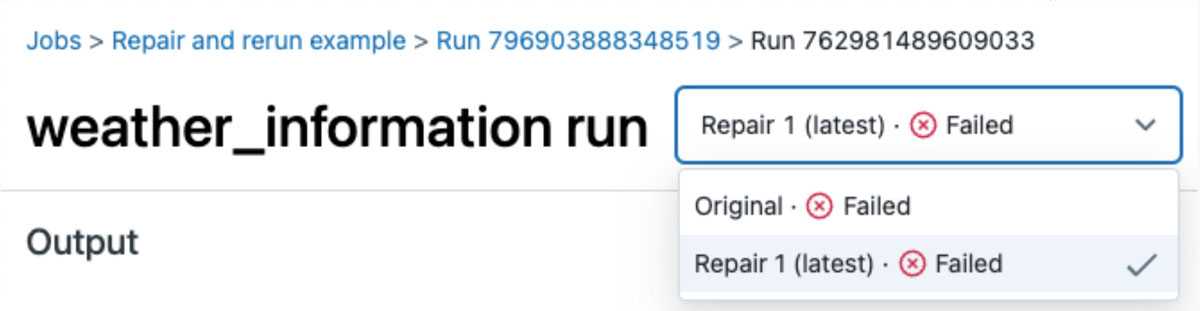
The new run is then given a unique version number, associated with the failed parent run making it easy to review and analyze historical failures.
When tasks fail, “Repair and Rerun” for Databricks Jobs helps you quickly fix your production pipeline. The intuitive UI shows you exactly which tasks are impacted so you can fix the issue without rerunning your entire flow. This saves time and effort while providing deep insights to mitigate future issues.
“Repair and Rerun” is now Generally Available (GA), following on the heels of recently launched cluster reuse.
What's Next
We are excited about what is coming in the roadmap, and look forward to hearing from you.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.