From Apache Airflow® to Lakeflow Jobs: How the Industry is Shifting from Workflow-First to Data-First Orchestration
Apache Airflow® was built for the last era of data platforms. Lakeflow Jobs powers the next one: unified governance, event-driven pipelines, and AI-native data engineering workflows.
by Saad Ansari and Joanna Zouhour
- Orchestrators built around handwritten DAGs are fading. Modern data platforms expect data-aware, event-driven workflows with built-in governance.
- Apache Airflow® served the previous generation of data stacks. Lakeflow Jobs powers the new Data Intelligence Platform with native triggers, lineage, and AI-ready pipelines.
- Migration from Apache Airflow® to Lakeflow Jobs is simple. You keep your Python, parameters, and patterns without managing schedulers, workers, or metadata databases.
If you’ve built pipelines in the last decade, you’ve probably used Apache Airflow. Data engineering teams needed a way to schedule Python, run ETL, and manage dependencies, and Apache Airflow filled that gap.
That model no longer fits.
Modern pipelines are data-first. They run on governed platforms with catalogs, unified identity, serverless runtimes, and AI-driven automation. They’re triggered by table updates, lineage events, SLAs, quality checks, or model drift, not cron.
Lakeflow Jobs, Databricks’ native orchestrator (formerly known as Databricks Workflows), is designed for the Data Intelligence Platform: data-aware triggers, governed identities, built-in lineage, and multimodal tasks across Databricks SQL, ML, BI, agents, and streaming. It treats orchestration as a native platform capability, not a separate system to manage.
This shift makes Lakeflow Jobs fundamentally more modern than Apache Airflow in five important ways.
- Orchestration Management
- Version Management
- Orchestration Type
- Security and governance
- Pricing
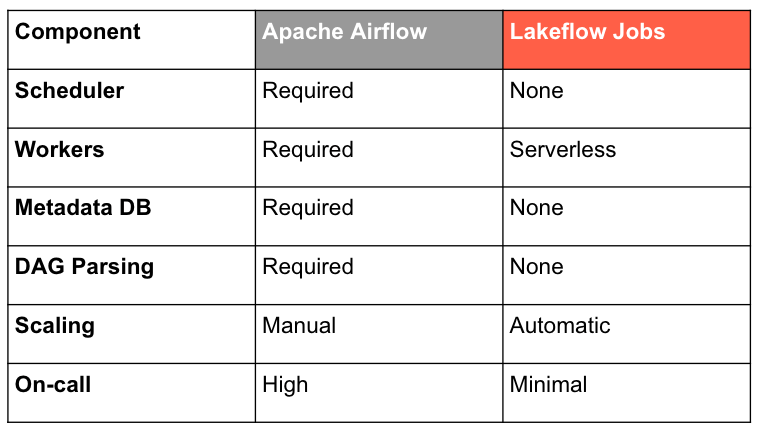
1. No Schedulers. No Workers. No Infrastructure to Run.
Apache Airflow’s architecture is powerful but heavy: a scheduler that parses every DAG, executor fleets, a metadata database, queues, plugins, and operational glue around all of it. Most Apache Airflow users know the symptoms:
- scheduler stalls
- workers losing heartbeats
- metadata tables bloating
- DAG parsing getting slower over time
- tuning executors to keep data pipelines flowing
Running Apache Airflow means running infrastructure (1 in 5 talks at the Airflow Summit this year was about infrastructure or operations). Lakeflow Jobs removes this burden by providing
- fully managed control plane
- serverless execution
- automatic scaling
- no scheduler to babysit
- no metadata DB to maintain
- 99.95% uptime SLA backed by Databricks
- hundreds of millions of tasks run each week
You write your workflow. The platform handles the rest, supporting tens of thousands of jobs with thousands of tasks with no scheduler or infrastructure to manage.
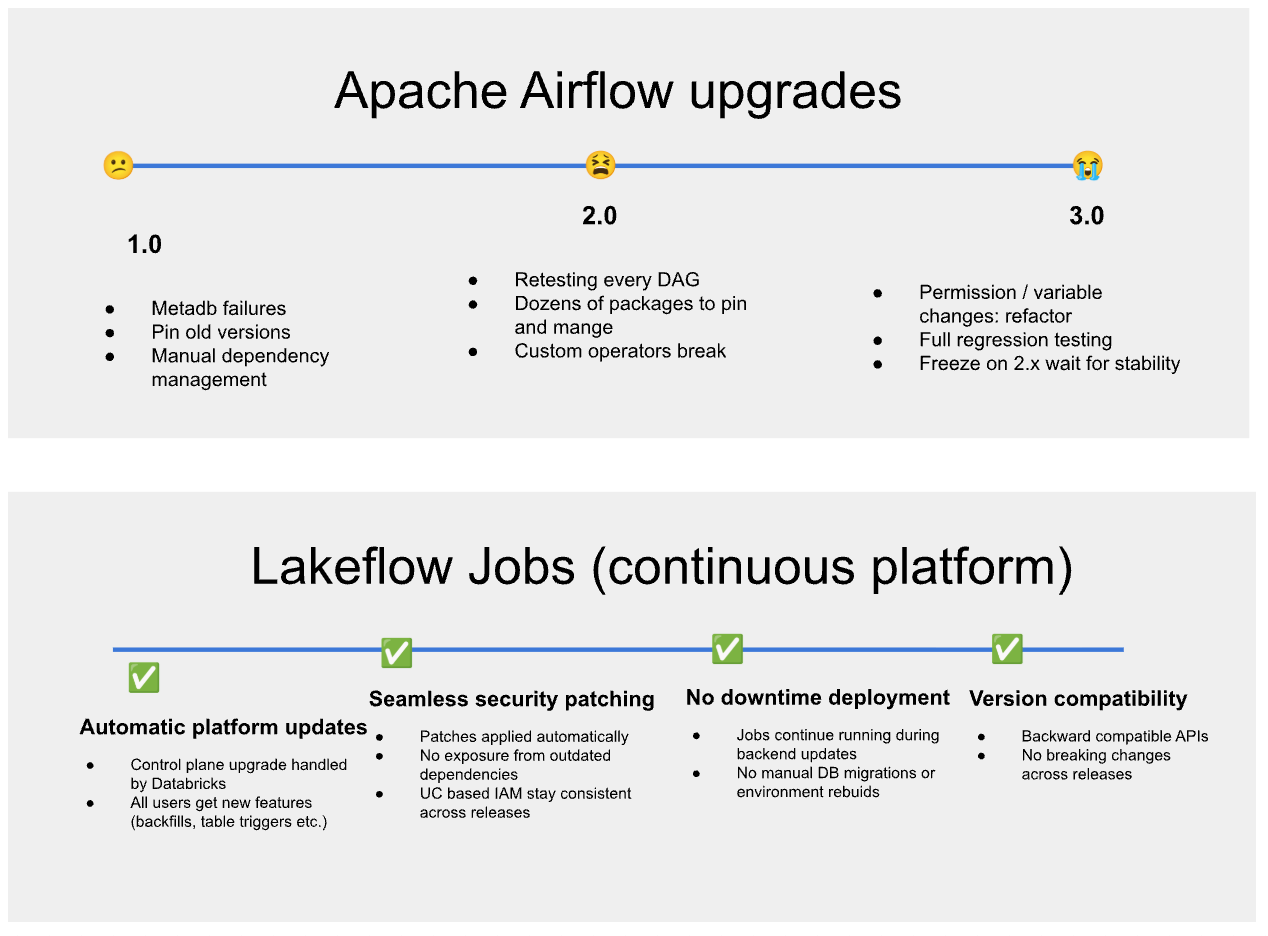
2. Zero Upgrade Burden: Versionless Control Plane and Versionless Compute
Apache Airflow upgrades affect two things at once:
- the orchestrator (scheduler, workers, operators, dependencies)
- your Spark jobs and runtime environment
Both can break DAG logic. This is why many teams stay pinned to old Apache Airflow versions far longer than they’d like. Apache Airflow’s user surveys still show a meaningful minority on 1.x years after 2.0, and studies of Stack Overflow questions and upgrade blog posts repeatedly call out version updates and breaking changes as a source of regressions.
In contrast, Lakeflow Jobs upgrades automatically with no downtime or version pinning.
Control plane: upgrades automatically with backward compatibility.
Compute: serverless, always up-to-date, no user-managed runtime versions.
For example, a job created years ago with the Jobs API v2 continues to run unchanged today, even after new task types, triggers, and API fields are added. Existing definitions keep working because the control plane preserves API compatibility across releases, so teams never need migration sprints or breaking-change rewrites.
No maintenance windows.
No pinning.
No “upgrade and pray.”
New features just appear and your workflows keep running.
3. Data-First, Event-Driven Orchestration by Default
Apache Airflow was built around time-based scheduling and DAG parsing. Modern data pipelines run when:
- a table updates
- a file lands in storage
- a metric drift threshold is hit
- a lineage event occurs
- a model needs retraining
- quality checks fail
These signals are part of the platform, not external events you poll. Lakeflow Jobs is integrated directly with Unity Catalog and system tables so it supports table-update and file-arrival triggers and event-driven pipelines. Developers can build DAGs across SQL, ML, BI, Spark, and dbt and deploy these data engineering workflows using Databricks Asset Bundles.
This is orchestration built around the data layer, not cron.
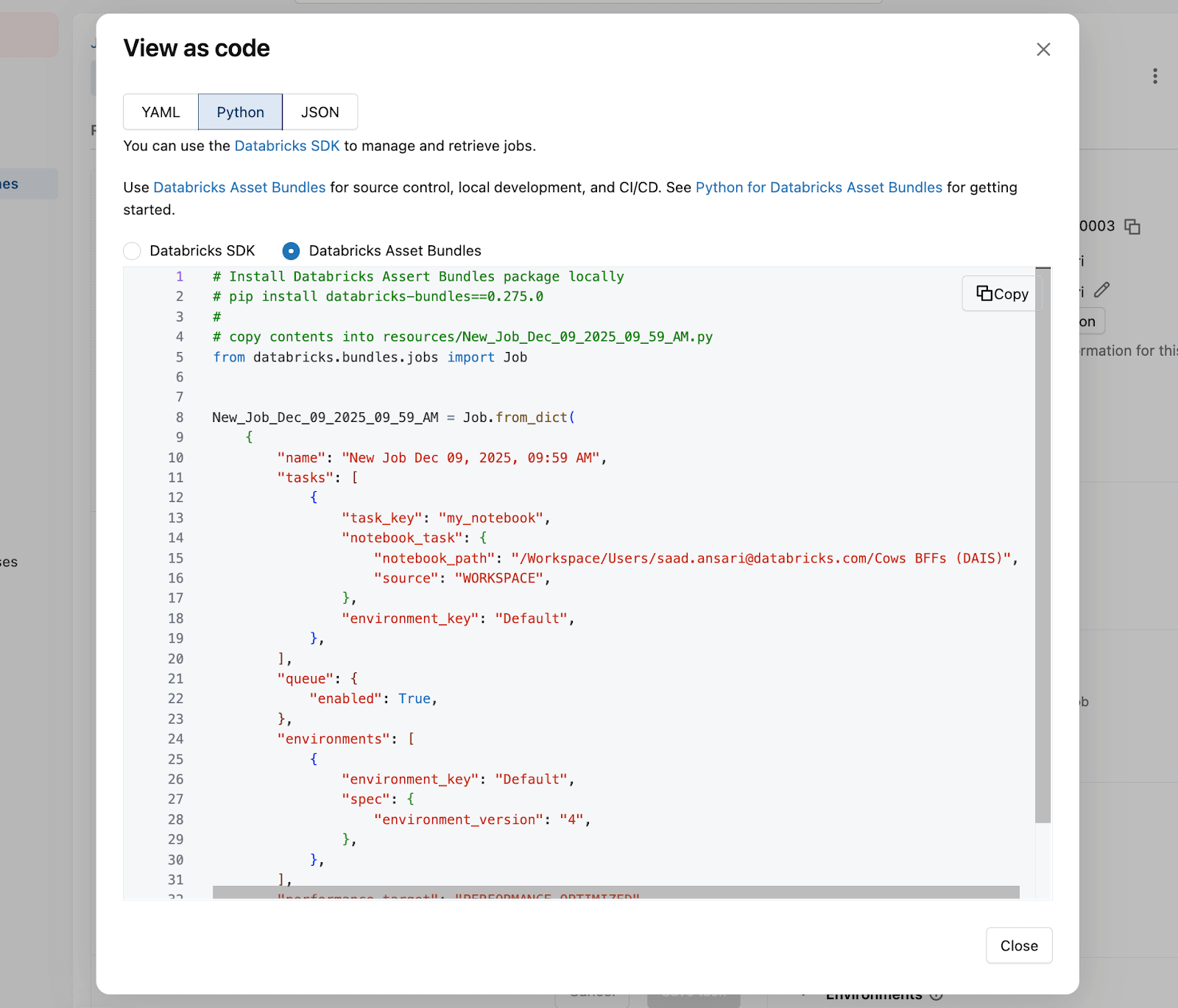
Your job, tasks, dependencies etc. all defined and deployed entirely in Python with Databricks Asset Bundles.
4. Governance Built In, Not Bolted On
Apache Airflow relies on external systems for identity, permissions, secrets, logging, and lineage. To get a complete picture, teams stitch together IAM roles, Kubernetes RBAC, database logs, and third-party observability tools.
Because Lakeflow Jobs uses Databricks’ Unity Catalog as its governance layer, permissions, identity, lineage, and audit are all inherited automatically. Every run is logged in System Tables, lineage is captured without plugins, and workspace-wide policies apply consistently across SQL, ML, notebooks, dashboards, data pipelines, and jobs.
Governance is not a plugin. It is the foundation. Because lineage and audit come built-in, teams can answer questions that are nearly impossible in Apache Airflow without stitching systems together. For example, you can query system tables to find jobs that write tables with no downstream consumers, a simple way to eliminate data pipelines that burn compute without producing business value
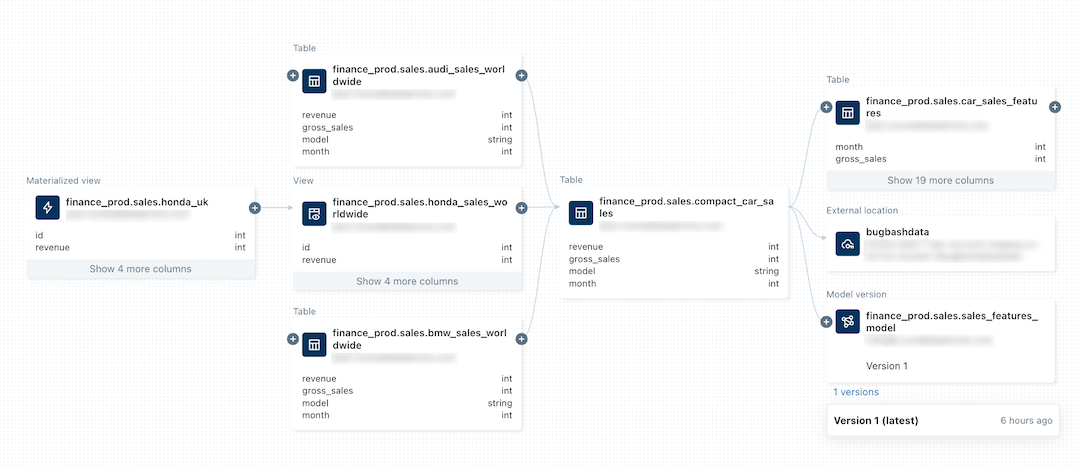
Visualize Data Lineage with Lakeflow and Unity Catalog
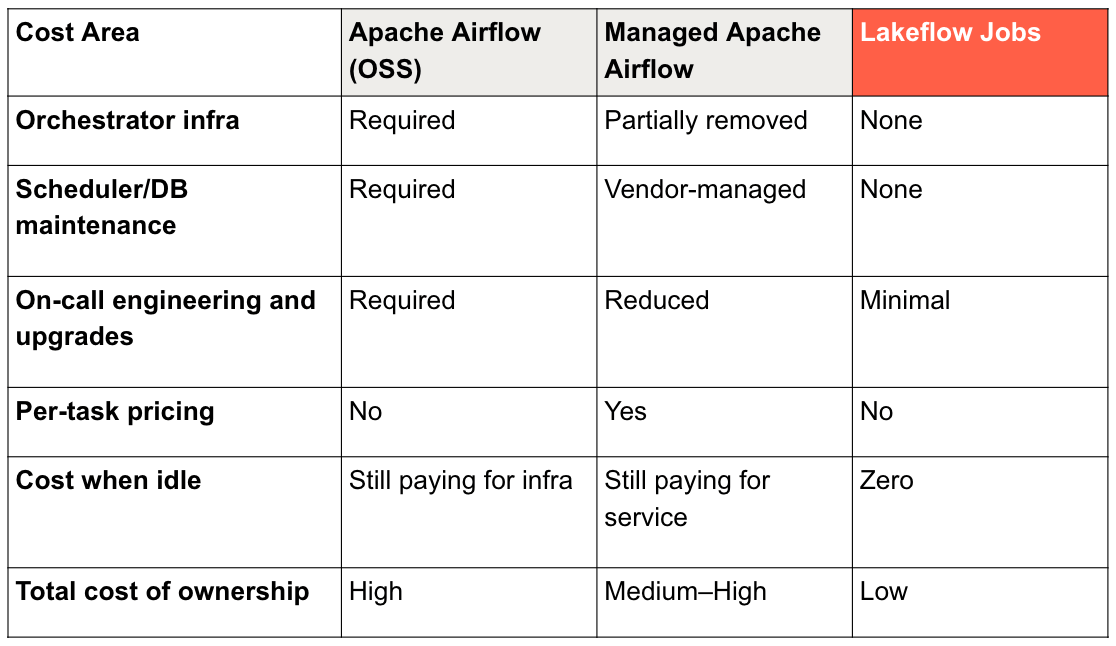
5. Zero Orchestration Costs, Only Pay for Compute
Apache Airflow is open source, but the cost of running it is not free:
- scheduler nodes
- worker clusters
- metadata databases
- monitoring stacks
- operator maintenance
- engineers on-call
Managed Apache Airflow reduces some of this but adds subscription fees and per-task pricing.
Lakeflow Jobs has no orchestration surcharge You pay only for compute used by your tasks. When your data engineering workflows are idle, you pay nothing.
Migrating from Apache Airflow to Lakeflow Jobs: Keep What You Know, Lose What You Hate
Moving from Apache Airflow to Databricks Lakeflow Jobs is straightforward. Most Apache Airflow DAGs are:
- Python
- calling SQL
- calling Spark
- calling APIs
You can keep all of that.
Lakeflow supports:
- Python, SQL, notebook tasks
- Parameters
- data-aware triggers
- conditional logic
- Foreach loops
- modules and libraries
- external calls via serverless API/script tasks
Lakeflow Jobs lets you keep your Python and SQL the way they are today, while eliminating the Apache Airflow-specific machinery around them. You define tasks in Bundles, deploy once, and the platform handles compute, scheduling, and upgrades.
Real-world migration example: YipitData
YipitData, a data company serving investment funds and enterprises, relied heavily on Apache Airflow for custom workflows. As their pipelines grew, so did the operational cost and onboarding complexity. Every new analyst had to learn Apache Airflow internals before building anything productive.
By moving to Lakeflow Jobs, the team simplified orchestration and unified their environment. They reported a 60 percent reduction in database costs and 90 percent faster processing. Analysts could create and monitor workflows directly, and data engineers no longer had to maintain Apache Airflow infrastructure. Learn
“Learning Apache Airflow required a significant time commitment. With Databricks, we build and deploy data workflows in one place.” —YipitData Engineering Lead
Learn more about YipitData’s migration story
The Future of Orchestration Is Platform-Native
The future of orchestration isn’t a bigger scheduler. It’s a data platform that understands your assets, your lineage, your governance rules, and your events.
Lakeflow Jobs works because it treats orchestration as part of the platform, not a system you operate on the side. If you’re building pipelines on a modern data stack, the simplest next step is to migrate one workflow and experience what platform-native orchestration feels like.
Apache Airflow vs Lakeflow Jobs - Summary
Apache Airflow | Lakeflow Jobs | |
Orchestration Management | Heavy, Operationally Complex | Little to no infrastructure management |
Version Management | Manual, high-risk upgrades | Automatic upgrades with no downtime or version pinning |
Orchestration Type | Schedule-first and DAG-centric | Data-first, event-driven, modern |
Security and governance | External | Natively integrated with Unity Catalog |
Pricing | Free with subscription fees and per-task pricing | No orchestration surcharge, you only pay for what you use |
Try migrating one of your existing data engineering workflows. No servers to configure. No scheduler to restart. Just reliable orchestration that runs where your data already lives.
- Learn more about Lakeflow Jobs orchestration
- Try Lakeflow Jobs with Databricks’ Free Edition
- Create your first job with our Quickstart Guide
Apache Airflow is a trademark of the Apache Software Foundation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.