Announcing table update triggers in Lakeflow Jobs
Reduce costs by triggering jobs to run only when a table updates
- Introducing table update triggers: automatically trigger jobs whenever specified tables are updated
- Empower decentralized data teams by enabling users to orchestrate event-driven pipelines independent of upstream schedules
- Improve efficiency by triggering jobs right when data arrives, reducing latency and lowering costs
Databricks is excited to announce that table update triggers are now generally available in Lakeflow Jobs. Many data teams still rely on cron jobs to approximate when data is available, but that guesswork can lead to wasted compute and delayed insights. With table update triggers, your jobs run automatically as soon as specified tables are updated, enabling a more responsive and efficient way to orchestrate pipelines.
Trigger jobs instantly when data changes
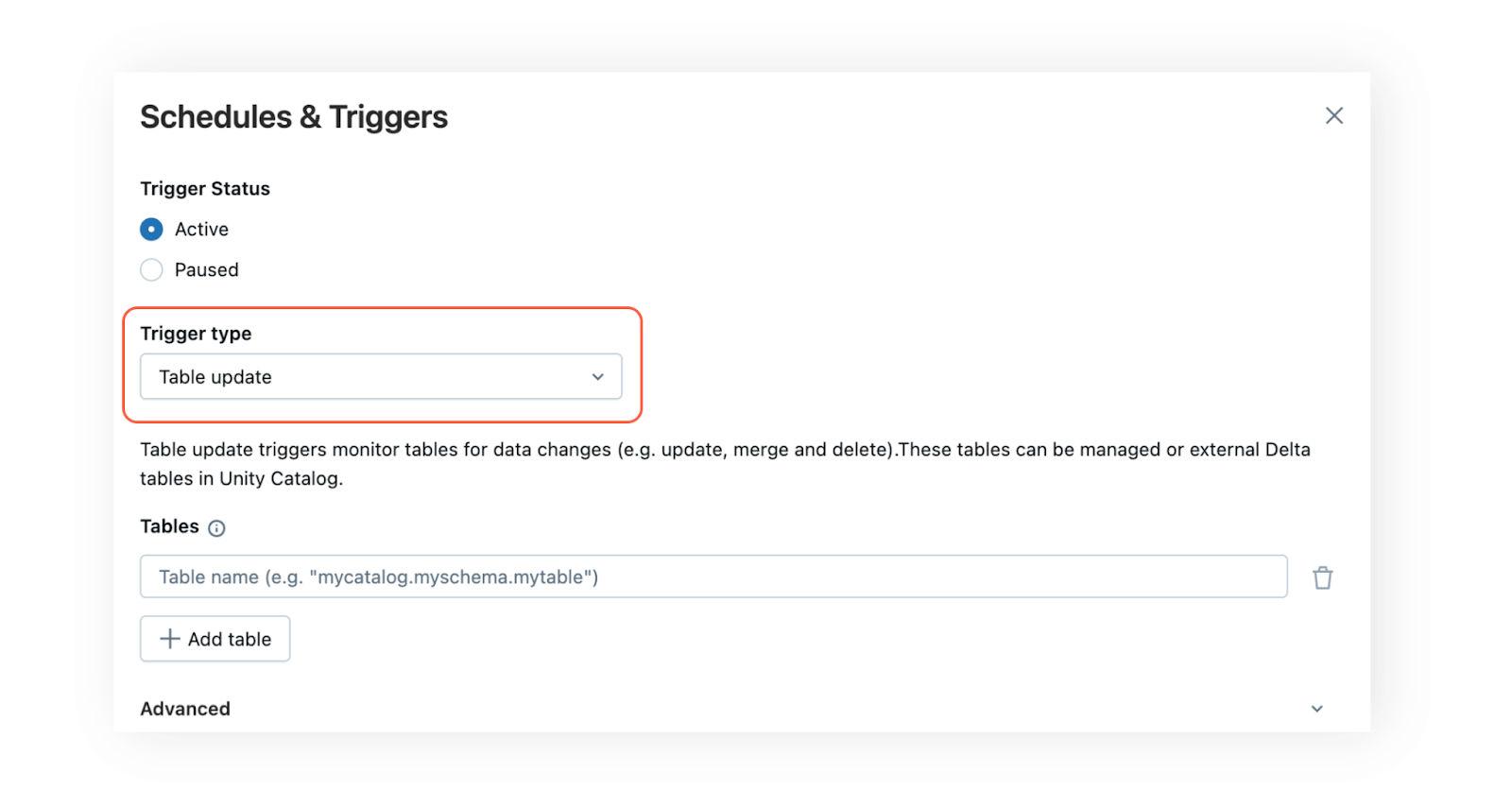
Table update triggers let you trigger jobs based on table updates. Your job starts as soon as data is added or updated. To configure a table update trigger in Lakeflow Jobs, just add one or more tables known to Unity Catalog using the “Table update” trigger type in the Schedules & Triggers menu. A new run will start once the specified tables have been updated. If multiple tables are chosen, you can determine whether the job should run after a single table is updated or only once all selected tables are updated.
To handle scenarios where tables receive frequent updates or bursts of data, you can leverage the same advanced timing configurations available for file arrival triggers: minimum time between triggers and wait after last change.
- Minimum time between triggers is useful when a table updates frequently and you want to avoid launching jobs too often. For example, if a data ingestion pipeline updates a table a few times every hour, setting a 60-minute buffer prevents the job from running more than once within that window.
- Wait after last change helps ensure all data has landed before the job starts. For instance, if an upstream system writes several batches to a table over a few minutes, setting a short “wait after last change” (e.g., 5 minutes) ensures the job only runs once writing is complete.
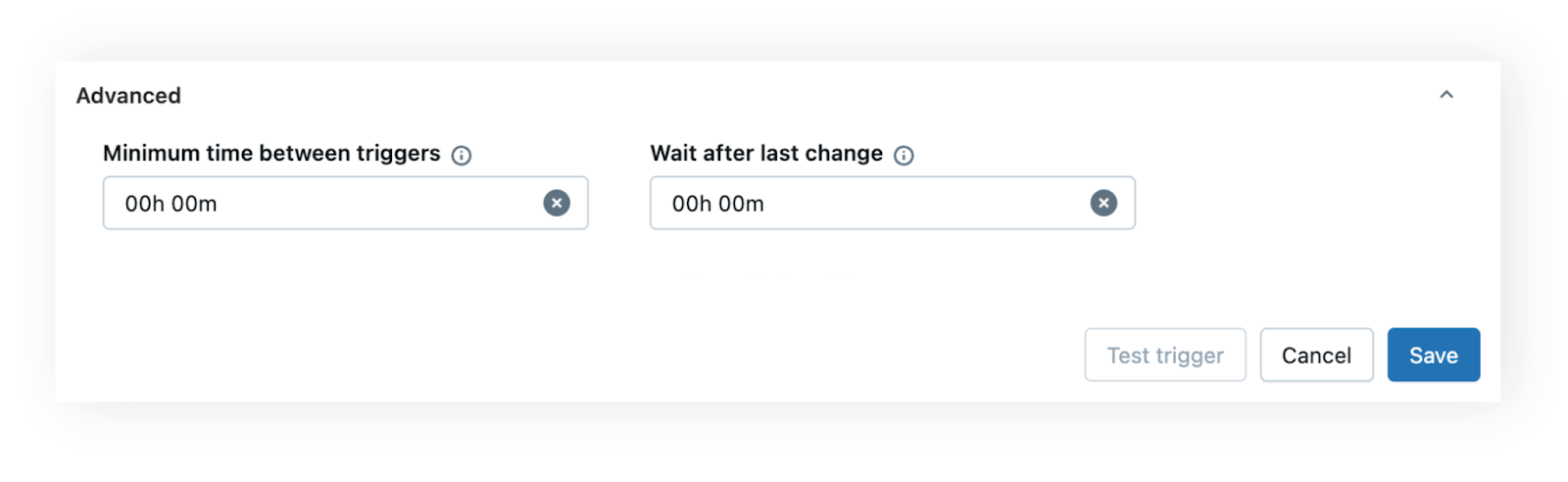
These settings give you control and flexibility, so your jobs are both timely and resource-efficient.
Reduce costs and latency by eliminating guesswork
By replacing cron schedules with real-time triggers, you reduce wasted compute and avoid delays caused by stale data. If data arrives early, the job runs immediately. If it’s delayed, you avoid wasting compute on stale data.
This is especially impactful at scale, when teams operate across time zones or manage high-volume data pipelines. Instead of overprovisioning compute or risking data staleness, you stay aligned and responsive by reacting to real-time changes in your data.
Power decentralized, event-driven pipelines
In large organizations, you might not always know where upstream data comes from or how it’s produced. With table update triggers, you can build reactive pipelines that operate independently without tight coupling to upstream schedules. For example, instead of scheduling a dashboard refresh at 8 a.m. every day, you can refresh it as soon as new data lands, ensuring your users always see the freshest insights. This is especially powerful in Data Mesh environments, where autonomy and self-service are key.
Table update triggers benefit from built-in observability in Lakeflow Jobs. Table metadata (e.g., commit timestamp or version) is exposed to downstream tasks via parameters, ensuring every task uses the same consistent snapshot of data. Since table update triggers rely on upstream table changes, understanding data dependencies is crucial. Unity Catalog’s automated lineage provides visibility, showing which jobs read from which tables. This is essential for making table update triggers reliable at scale, helping teams understand dependencies and avoid unintended downstream impact.
Table update triggers are the latest in a growing set of orchestration capabilities in Lakeflow Jobs. Combined with control flow, file arrival triggers, and unified observability, they offer a flexible, scalable, and modern foundation for more efficient pipelines.
Getting Started
Table update triggers are now available to all Databricks customers using Unity Catalog. To get started:
- Get detailed information about triggers in Lakeflow Jobs
- Learn more about Lakeflow Jobs
- Create your first job with our Quickstart Guide
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.