Structured vs. unstructured data
- Structured data is organized in predefined schemas - Stored in tables with fixed formats, structured data enables fast SQL queries, supports business intelligence tools, and serves traditional analytics like reporting and forecasting, but schema changes can be challenging.
- Unstructured represents 80-90% of enterprise data and requires advanced tools to extract insights from data lakes or lakehouse architectures.
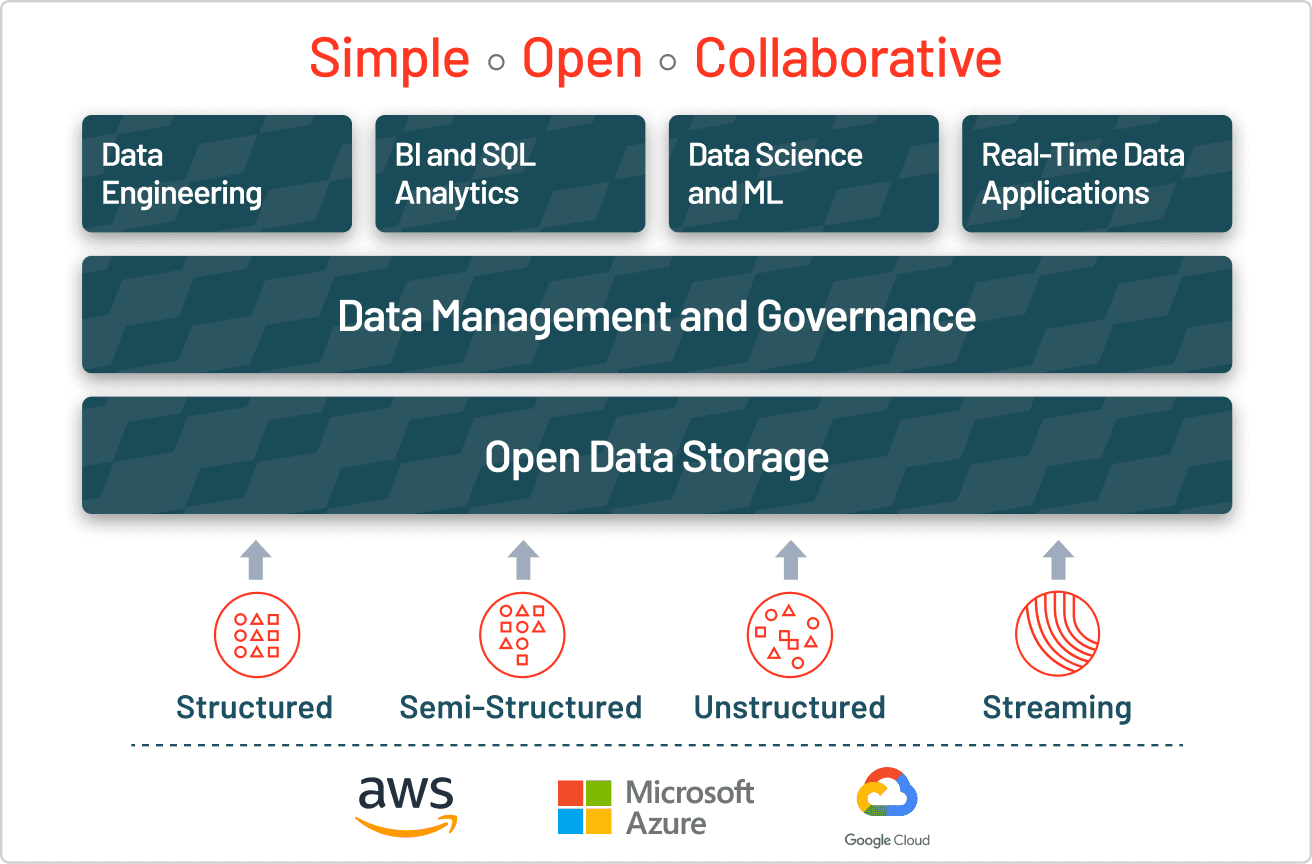
- Modern enterprises need hybrid approaches combining both data types - Lakehouse architectures unify structured and unstructured data management, offering the openness of data lakes with the reliability of data warehouses while providing unified governance across all data types.
Structured and unstructured data are both key assets to modern organizations, but they’re fundamentally different. Organizations must understand these differences and manage each type effectively to harness their full value. This guide examines practical implications, real-world use cases and strategic considerations for choosing the right type of data. It also covers tools for common business requirements, moving beyond generic comparisons to actionable decision-making frameworks.
Structured data: characteristics and applications
Structured data core traits
Structured data is information organized within a predefined relational data model, meaning the data is arranged in tables with fixed schemas. This model specifies the structure (rows and columns), data types and relationships between tables before any data is stored to enable efficient searching and analysis. Common examples of structured data include financial transactions, Excel files, customer relationship management (CRM) records, inventory levels, sales orders, reservation systems and sensor readings.
Structured data is typically housed in data warehouses. These are optimized for fast, reliable querying through Structured Query Language (SQL), used for structured data workloads.
The standardized format also makes structured data highly accessible. Business users can easily explore, analyze and report on it using familiar business intelligence (BI) and analytics tools to generate insights without needing advanced technical expertise.
Structured data business value and analysis
Structured data delivers significant business value because its consistent, filterable format supports data analysis with minimal preprocessing, enabling organizations to run calculations, build models and compare trends efficiently. Structured data serves as the backbone of enterprise analytics, offering fast querying, high data integrity and dependable outputs that organizations can trust for day-to-day and strategic planning. This includes traditional BI such as routine reporting, forecasting, KPI monitoring and interactive dashboards that help organizations track performance and make decisions for optimizing operations.
Structured data is also highly effective for machine learning (ML) models and automated systems generating advanced information such as AI-generated summaries and customer sentiment evaluation.
Structured data storage and scalability considerations
A major advantage of structured datasets is high storage efficiency via columnar compression. Because values in the same column tend to be similar, columnar databases enable efficient compression and reading of data, resulting in significant storage savings and faster analytics.
However, schema changes within structured data can be challenging. Because database ecosystems are highly connected, with many dependencies, changes such as adding, modifying or removing fields can cause data loss, application downtime and cascading failures elsewhere in the system if not managed properly. Organizations must carefully plan migrations to avoid disruption.
Unstructured data: traits, challenges and opportunities
Unstructured data characteristics and sources
Unstructured data is information in its native format. Unlike structured data that is organized into rows and columns, unstructured data lacks predefined structure, which makes it more difficult to search and analyze.
Data in its unstructured form can be machine-generated—such as GPS data, log files and other telemetry information—or human-generated. Examples of human-generated unstructured data include social media posts, audio files, video files, emails, multimedia files and text documents.
Unstructured data represents 80% to 90% of enterprise data growth. This type of data can offer valuable insights in areas such as market trends, customer sentiment and operational issues, but extracting those insights can be challenging compared to working with structured data.
Unstructured data analysis challenges and solutions
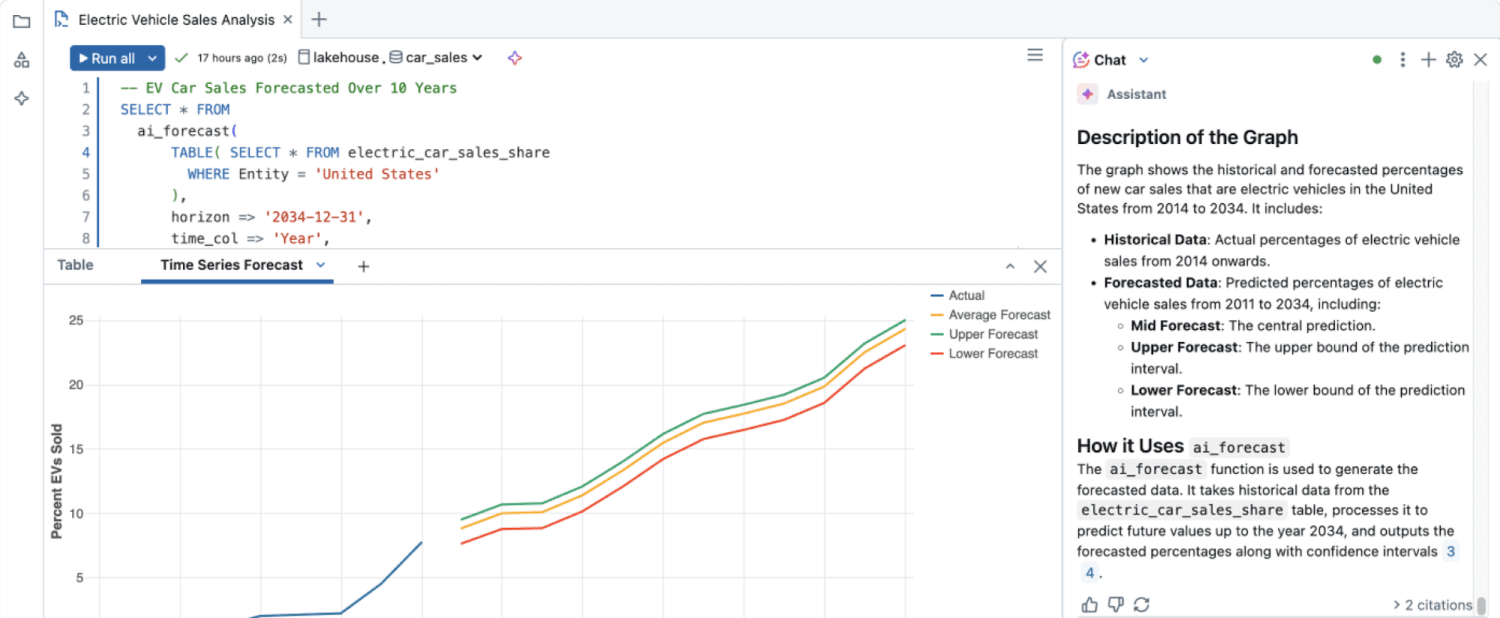
Unstructured data insights largely went unmined until the creation of advanced data analysis such as ML algorithms, natural language processing (NLP) and sentiment analysis that can automatically extract meaning from large volumes of unstructured data.
Typically, organizations need data scientists to manage, process and extract meaningful patterns from unstructured data using advanced techniques. Data lakes are commonly used to consolidate unstructured data in its native, raw format, providing flexible storage for large volumes. Data lakes allow raw data to be transformed into structured data that is ready for SQL analytics, data science and machine learning with low latency. Data lakes can also retain raw data indefinitely at low cost for future use in ML and analytics.
However, data lakes can easily degenerate into "data swamps" with reliability, performance and governance issues.Traditional data lakes on their own aren’t sufficient to meet the needs of businesses looking to innovate, which is why businesses often operate in complex architectures, with data siloed away in different storage systems across the enterprise.
Lakehouse storage unifies structured and unstructured data handling to address the challenges posed by data lakes. Lakehouses implement data warehouse-like structures and management features directly on the low-cost data storage of a data lake, combining the openness of data lakes with the management and reliability features of data warehouses. This structure ensures that enterprises can leverage various types of data for data science, ML and business analytics projects.
Unlocking business value from unstructured data
Unstructured data holds rich information that traditional analytical techniques can’t easily interpret. Machine learning capabilities enable unstructured content to be processed at scale, identifying patterns, themes, sentiments and anomalies that would otherwise remain hidden. Using techniques such as NLP and computer vision, organizations can transform qualitative data into actionable insights used to inform decisions.
For example, to improve customer service, organizations can use AI to analyze a variety of sources including product reviews, call center transcripts, social media mentions and chatbot conversations. The patterns identified can be used to reveal opportunities to solve problems, boost efficiency and spark innovation to enhance the customer experience.
Key differences of structured vs. unstructured data and decision framework
Understanding the differences between structured and unstructured data is essential for designing effective data architectures and choosing appropriate analytical methods. Each type brings unique strengths and challenges that must be factored into an organization’s data strategy.
Critical comparison dimensions
- Data format: Structured data is organized in a fixed, predefined format. Each record uses the same set of fields and data types so everything stays consistent. Unstructured data is stored in its raw, native form without a uniform structure, making it more flexible but harder to organize and analyze.
- Analysis tools: Structured data can easily be queried using SQL and integrated into standard business intelligence tools. Unstructured data requires more advanced analytics methods, including ML, NLP and computer vision. These are typically managed by data scientists or specialized analysts.
- Storage: Structured data fits naturally into data warehouses, which are optimized for relational queries and performance. Unstructured data is better suited to data lakes, which allow organizations to store raw data at scale, or hybrid lakehouse architectures.
- Processing time: Because structured data is already organized, it can often be analyzed immediately with minimal preparation. Unstructured data generally needs significant preprocessing—such as cleaning, tokenization, labeling and feature extraction—before meaningful insights can be generated.
- User accessibility: Structured data is accessible to a broad range of users, including business analysts and decision-makers who can explore it through dashboards and reporting tools. Unstructured data usually requires the expertise of data scientists or engineers to convert it into usable formats and capture actionable insights.
Semi-structured data and modern approaches
The hybrid middle ground
Structured and unstructured data aren’t the only formats organizations need to manage. Semi-structured data bridges the gap between the two, using metadata tags to add some organization while still allowing flexible, evolving fields. Common examples include JSON, XML and CSV files. Organizations often use NoSQL databases and modern file systems to manage this type of data because they support flexible schemas and adapt more easily to changing data formats.
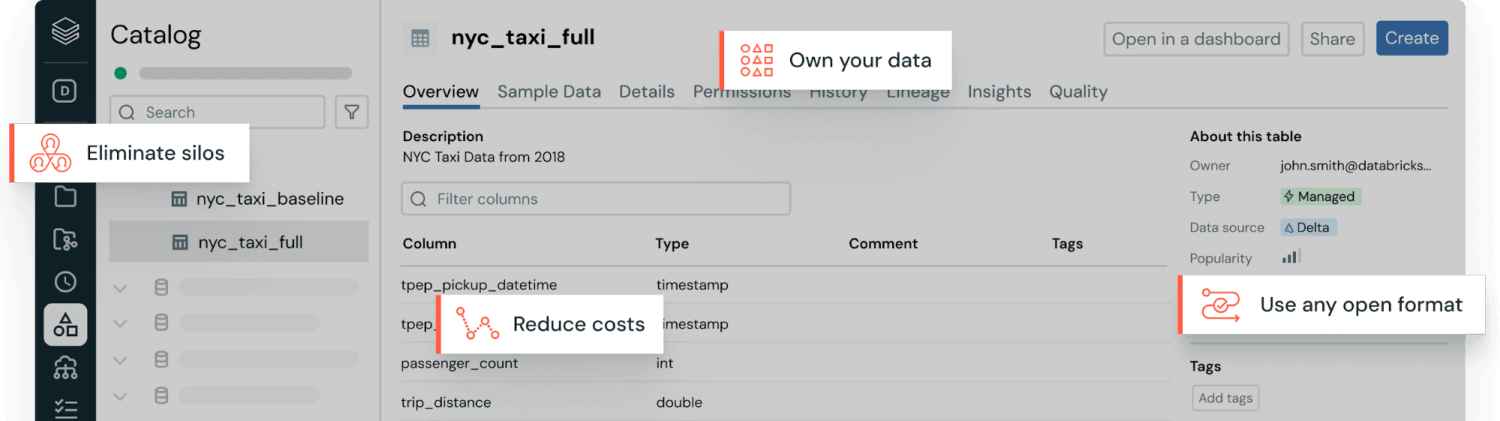
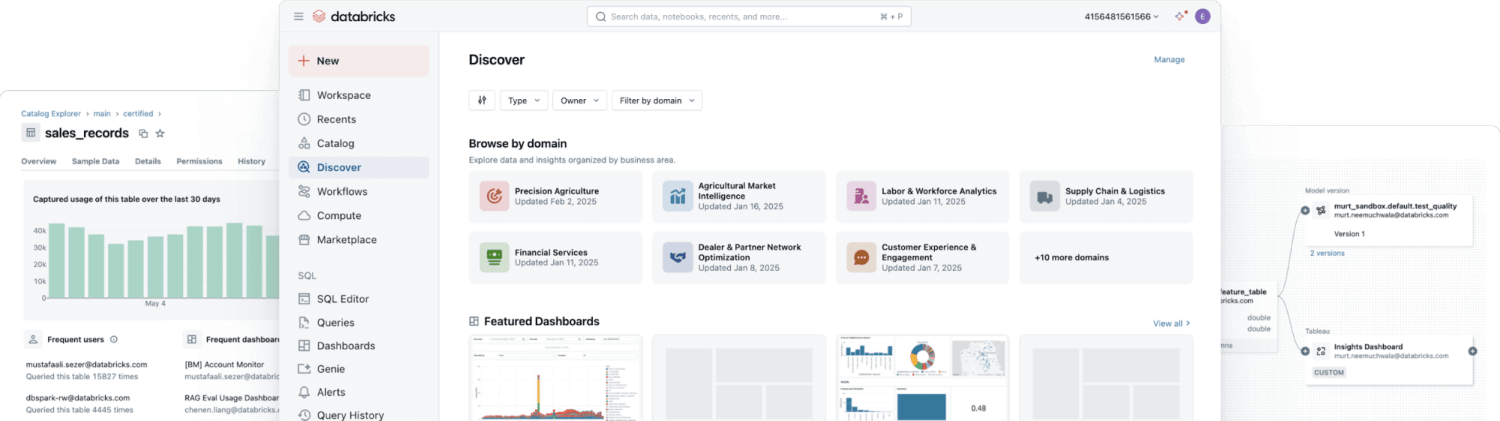
Most enterprises need all types of data, so they’re adopting hybrid storage strategies that blend the strengths of different data approaches. Modern lakehouse architecture removes the need to choose between data lakes and data warehouses by combining their capabilities into a single platform. Databricks’ Unity Catalog offers unified and open governance for all structured data, unstructured data, business metrics and AI models in any cloud. This enables organizations to govern, discover, monitor and share data all in one place, streamlining compliance and driving faster insights.
Conclusion
Data strategy isn’t a one-size-fits-all exercise. Understanding how structured, unstructured and semi-structured data differs is essential for building effective data management. Organizations need the expertise to match data types to their specific analytical needs and business requirements. By aligning data choices with their unique use cases, businesses can unlock deeper insights, improve decision-making and maximize the impact of their data investments.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.