Agent Bricks Knowledge Assistant Is Now Generally Available: Turning Enterprise Knowledge into Answers
Build an agent grounded in your docs in just minutes
- Deploy a trusted knowledge agent in minutes: Knowledge Assistant is now GA, making it easy to turn your documents into accurate, cited answers with a fully managed AI agent.
- Built for real enterprise data: Instructed Retrieval delivers higher-quality answers than traditional RAG by intelligently querying and prioritizing diverse knowledge sources.
- Production-ready and continuously improving: Automatic research upgrades, and a scalable inference API keep your agent accurate without re-building or re-deploying.
Some of your company’s most valuable data is still hard to access. Documents, slides, PDFs, and internal systems hold critical information, yet teams spend too much time searching, cross-checking, and piecing together context instead of making decisions.
Traditional approaches like Retrieval Augmented Generation (RAG) involved complex parsing, chunking, and embedding of unstructured data and constant updates and customization to maintain while delivering mediocre results. This made it impossible to scale out to many teams and systems, leaving your data locked away.
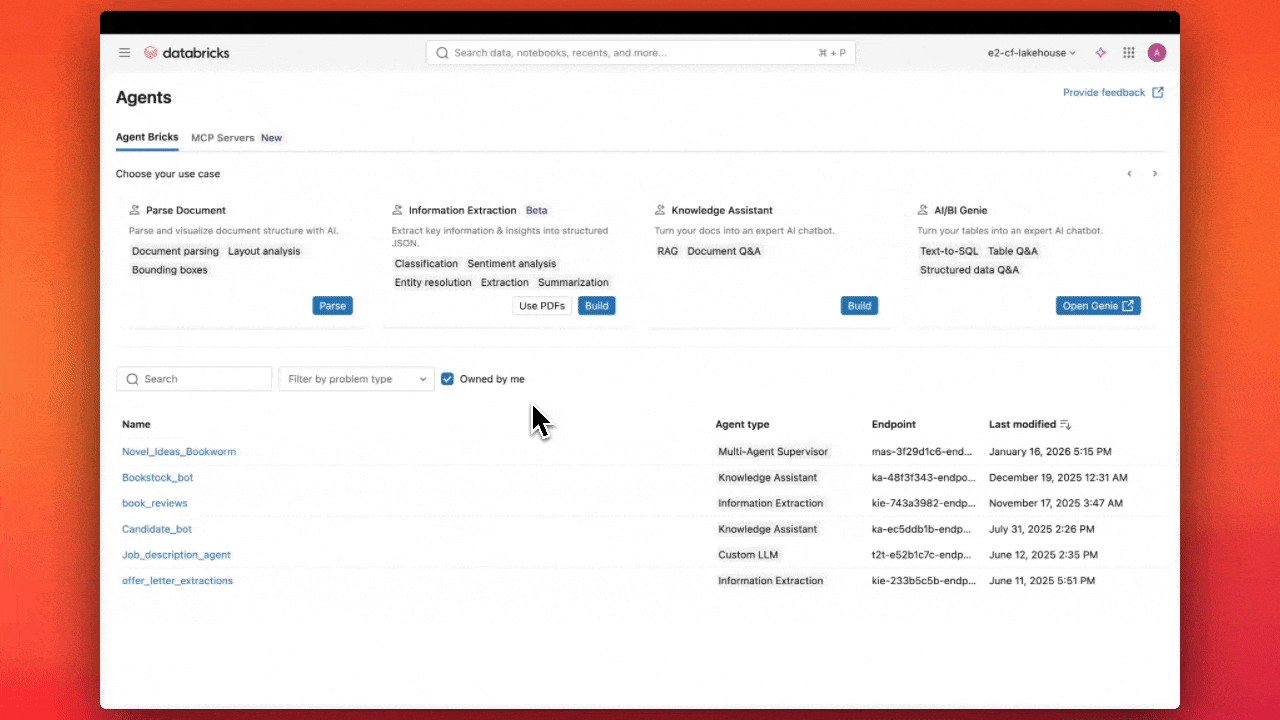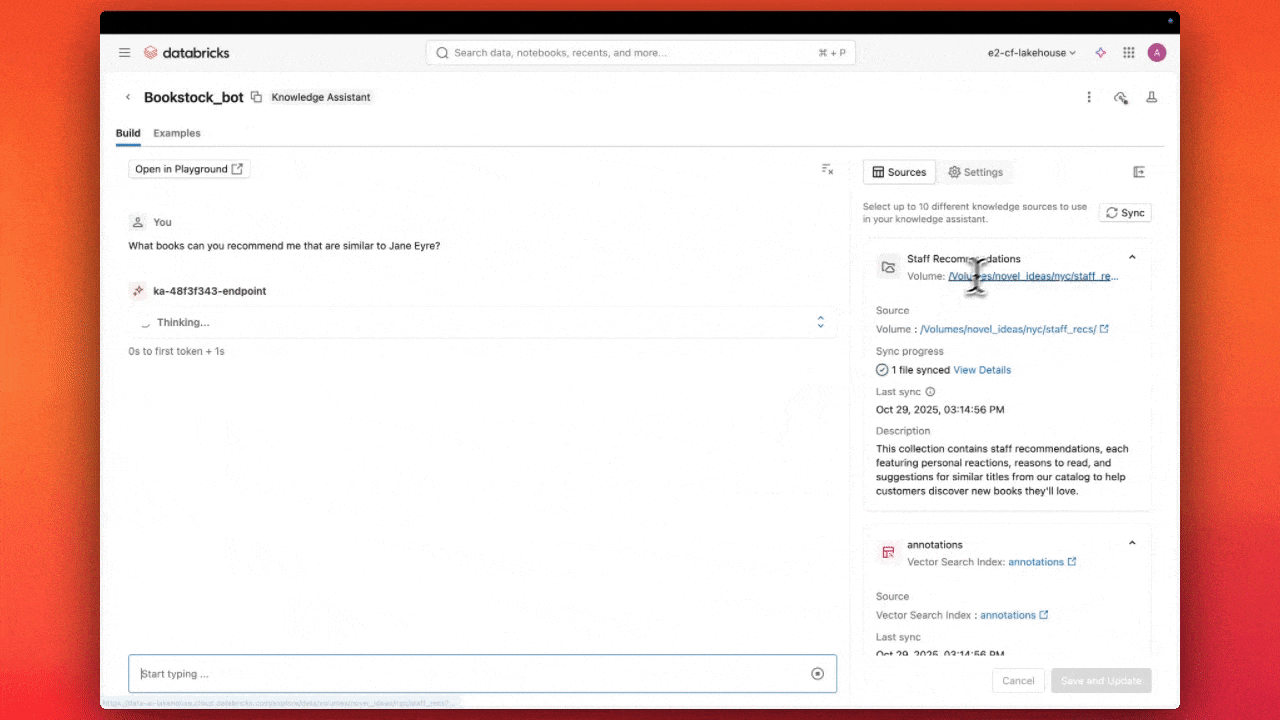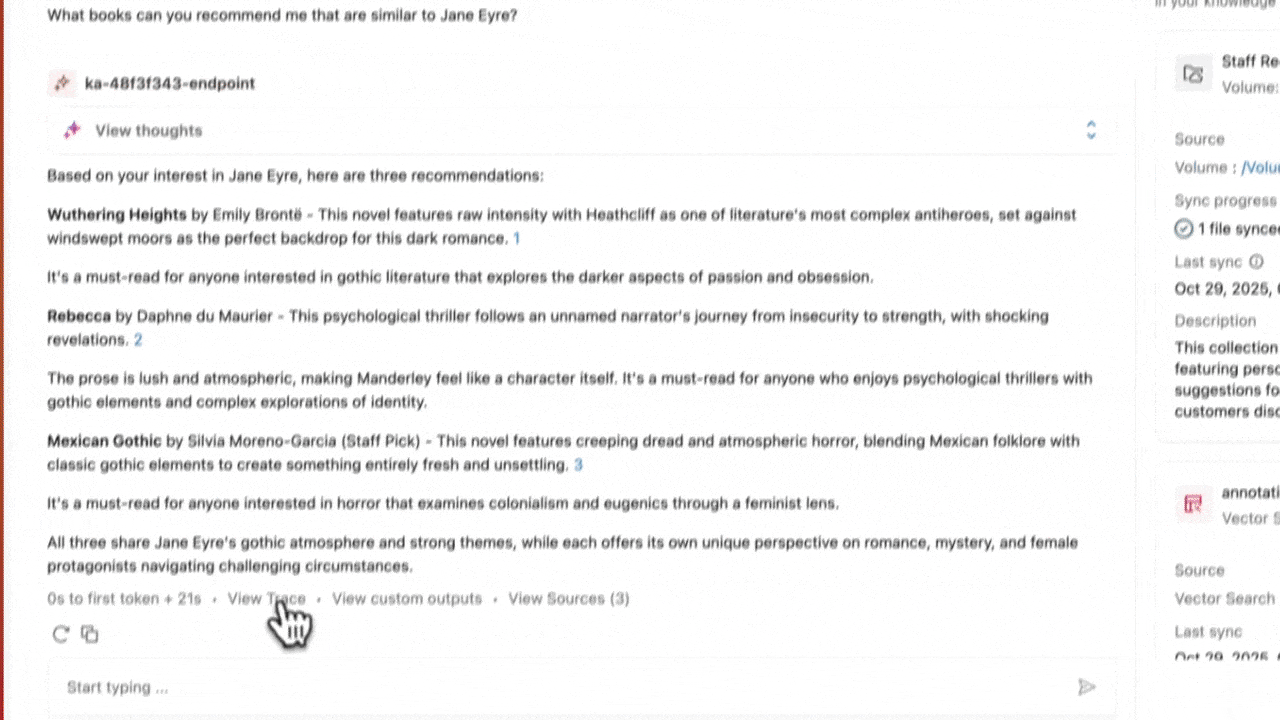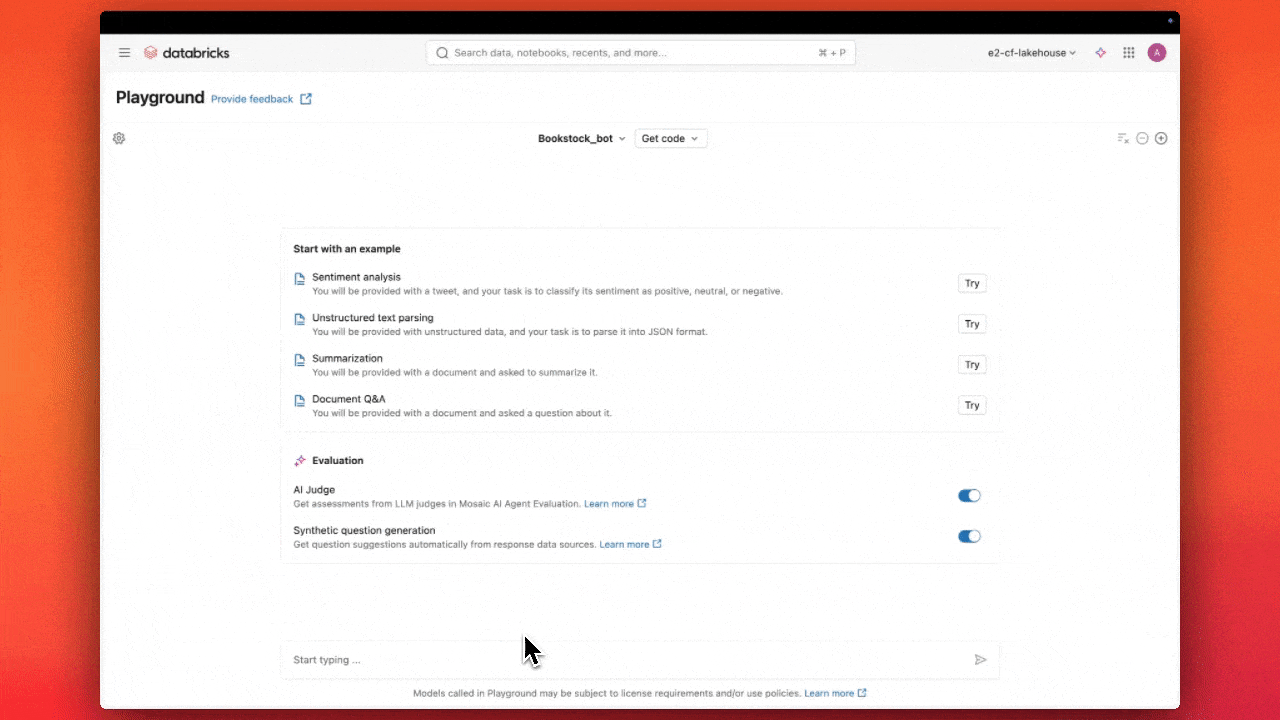
Knowledge Assistant changes this. Now Generally Available and expanded to 10 new regions, you can turn your documents into accurate, grounded answers in just minutes. As part of the Agent Bricks platform, it provides a fully managed experience across the entire agent lifecycle, from ingestion and continuous updates to retrieval and inference, with a scalable endpoint you can integrate anywhere. Knowledge Assistant is powered by Databricks AI research and achieves up to 70% higher answer quality than simplistic RAG approaches, without the operational overhead.
A new approach to retrieval for real enterprise data
Most retrieval systems were designed for a simpler world: a single index, a uniform schema, and similarity search as the primary signal. Enterprise knowledge doesn’t look like that. It spans many systems, each with different structures, metadata conventions, and expectations around freshness and authority. Treating all of that as a single uniform data source limits both quality and control.
Knowledge Assistant is built on a fundamentally different architecture, developed by the Databricks AI research team, called Instructed Retriever. Rather than relying on similarity search alone, the assistant understands how each knowledge source is organized and how it should be queried. When a user asks a question, Knowledge Assistant translates that request into precise, source-aware queries — incorporating guidance like prioritizing recent content, emphasizing specific metadata, or favoring authoritative sources.
This approach allows the assistant to synthesize information across disparate systems while remaining grounded in the structure of each one. This means you get page-level citations on every response, reducing hallucinations and allowing your users to get back to the source quickly.
Because this architecture is delivered as a fully managed service, teams benefit from ongoing research improvements automatically, rather than freezing retrieval quality at the moment an agent is deployed. We are constantly assessing new models, techniques, and research, running it against our extensive evaluation suite, and then automatically incorporating it in a seamless way into your agent.
Bridging the gap between subject matter experts and developers
Most enterprise AI systems rely on static prompts, labels, or coarse feedback signals that fix individual answers but fail to generalize. Knowledge Assistant is built differently, using Agent Learning from Human Feedback (ALHF) to turn expert guidance into durable, repeatable improvements in agent behavior.
Unlike one-off corrections, ALHF generalizes expert feedback across interactions. Your experts just need to provide questions and guidelines for the answer, and Knowledge Assistant will do the rest. Every response is captured in an end-to-end trace and logged as structured, governed data. With native MLflow integration, teams can evaluate changes and track quality improvements with the same rigor used for production ML systems.
“Agent Bricks turned our code into conversations, an always-available AI teammate that helps us move faster, work smarter, and stay focused on delivering frictionless revenue management.” —Ben Bartholic, Principal Data Engineer, FinThrive
Build your Knowledge Assistant agent today
Getting started is simple. Upload your documents and Knowledge Assistant handles the rest. Use Knowledge Assistant to create agents that understand market research, support documentation, or policies and procedures to unlock your enterprise knowledge and accelerate productivity.
- Start Building: Follow our documentation to deploy your first Knowledge Assistant today.
- Deep Dive into the Tech: Read our research blog to learn more about the science behind the Instructed Retriever.
- Level Up Your Skills: Learn AI agent fundamentals in a free skill builder course.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.