
序章
生成AI(GenAI)は、AIを民主化し、あらゆる業界を変革し、すべての従業員を支援し、すべての顧客とエンゲージする可能性を秘めています。生成AIモデルを最大限に活用するには、組織のエンタープライズデータに対する深い理解が必要です。現在、GenAI モデルに自社の知識を与えるための最もポピュラーな手法は、プロンプト エンジニアリング、検索拡張生成(RAG)、チェーン、エージェントです。しかし、特定のドメインやアプリケーションに合わせて調整されていない汎用モデルを使用する場合、そうした手法には限界があります。生成結果を改善し、コストを削減するには、生成AIアプリケーション開発者はファインチューニングや事前トレーニングを通じてカスタムモデルを構築する必要があります。
ファインチューニングは、より小規模なカスタムデータでさらにトレーニングを行うことで、既存のAIモデルを特定のドメインやタスクに特化させます。手法には、指示追従やチャットのための教師ありファインチューニング、および継続的な事前学習が含まれます。事前学習では、完全にカスタマイズ可能なデータでモデルをゼロからトレーニングして、まったく新しいモデルを作成します。これらすべての手法により、開発者はドメインやアプリケーション向けの知的財産と差別化を構築し、より優れた、より正確なモデルを作成して、より小型で低コストのモデル アーキテクチャを使用できる可能性があります。
このカスタムモデル作成ガイドでは、次の内容について説明します。
- 動機: なぜ、いつカスタム生成AIモデルを構築すべきなのでしょうか?
- 原則: カスタムモデルを構築する際、戦略と実装の指針となるべき高レベルのプラクティスには、どのようなものがありますか?
- テクニック:カスタムモデルを構築するには?データ準備、トレーニング、評価に関して、知っておくべきテクニックと「落とし穴」は何ですか?
このガイドは、カスタムモデルの構築を計画している実務者を対象としています。生成AIと大規模言語モデル(LLM)について、プロンプトエンジニアリング、RAG、エージェント、ファインチューニングや事前学習などの用語を含め、理解していることを前提としています。入門資料として、生成AIとLLMについて詳しくご覧ください。
Databricks について
Databricks は、予測モデルの構築から最新の GenAI や LLM に至るまで、AI と機械学習のソリューションを構築、デプロイ、監視するための統合されたツールを提供します。Databricks データ インテリジェンス プラットフォーム上に構築された Databricks は、組織が自社のエンタープライズ データを、あらゆる GenAI モデルで AI ライフサイクルに安全かつコスト効率よく統合できるようにします。お客様は、Databricksによってファインチューニングまたは事前デプロイされたMeta Llama 3、DBRX、BGEなどのモデルや、OpenAI GPT-4、Anthropic Claude、AWS Bedrock、AWS SageMakerといった他のモデルプロバイダーのモデルをデプロイ、管理、クエリー、モニタリングできます。エンタープライズ データを使用してモデルをカスタマイズするために、Databricksは、プロンプト エンジニアリング、RAG、ファインチューニング、事前トレーニングに至るまで、あらゆるアーキテクチャ パターンを提供します。
Databricksは、他のどのAIプラットフォームにも匹敵しないGenAIのファインチューニングと事前トレーニングの機能を提供します。2024年6月時点で、Databricks のお客様は過去1年間で20万を超えるカスタムAIモデルを構築しました。さらに、Databricks には、顧客が直接利用できる事前トレーニング済みモデルがあります。2024年3月、Databricksは、スクラッチから事前学習された新しい最高性能のオープンソースLLMであるDBRXを、商用利用可能なライセンスの下でリリースしました。2024年6月、DatabricksとShutterstockは、最先端のテキストから画像を生成する新たな事前学習済みモデルであるShutterstock ImageAI, Powered by Databricksをリリースしました。
これらの高性能モデルの構築に使用したインフラストラクチャとテクノロジーは、顧客に提供しているものと同じです。Databricks のお客様導入事例で、あらゆる業界におけるデータと AI の成功事例をご覧ください。
モチベーション:カスタムLLMのファインチューニングや構築はなぜ行うのか?
既存のモデルに品質、コスト、レイテンシの面で深刻な制約がある場合、顧客は一般的にカスタム生成AIモデルの構築を開始します。詳細はユースケースごとに異なりますが、次のような例があります。
- 「プロダクト独自のクエリ言語を生成するモデルが必要です。」モデルAPIとフューショットプロンプティングを使ってできますが、非常に遅く、コストがかかります。
- 「私の RAG bot はうまく機能していますが、大規模で強力なモデル API を使用しているため、私の高 throughput のユースケースにはコストがかかりすぎます。」そこまで汎用的なモデルは必要ないので、小規模でターゲットを絞った、低コストのモデルをファインチューニングしたいです。
- 「X言語が得意なオープンソースモデルが見つからないので、Xの理解に特化したモデルを構築したいです。」
最も有名な GenAI モデルは、(ほぼ)すべてを行うことを目的とした汎用モデルです。これらのモデルは素晴らしいものですが、ほとんどのユースケースにとっては大規模で高価すぎ、独自のデータやアプリケーションに関する知識もありません。上記のどの例でも、カスタムの専用モデルを構築することで、品質が向上するか、コストとレイテンシが削減されました。カスタムモデルは知的財産となり、顧客の製品に競争優位性をもたらしました。
カスタムモデルを構築する動機として、あまり一般的ではないものの、より差し迫ったものとして、法的または規制上の懸念があります。これは、特に規制の厳しい業界で顕著です。モデル トレーニング用のコンテンツの不正使用に関する非難などのリスクを管理するため、モデルを完全に制御することを求める顧客もいます。フルカスタムモデルを事前学習することで、モデルがどのように作成されたかを正確に把握し、証明できます。
では、どうやってスタートするか?GenAIは複雑な研究分野ですが、GenAIモデルのカスタマイズは簡単に始めることができます。基本的なファインチ�ューニングから複雑な事前トレーニングまで自然な流れがあり、Databricks プラットフォームはこのワークフロー全体をサポートします。このパスに従って進めることで、将来、より複雑なタイプのモデルカスタマイズに活用できる専門知識とデータが蓄積されます。
原則:モデルのファインチューニングまたはカスタムモデル構築は、いつ、どのように行うべきか?
いつ、なぜ、どのようにカスタムモデルを構築すべきか?
GenAI システムをカスタマイズする方法は、大きく分けて次の 2 つです。
- 複合 AI: 1 つ以上の既存のモデルを使用して、RAG、エージェント、その他の複合 AI システムをそれらのモデルを中心に構築できます
- カスタムモデル: 既存のモデルをカスタマイズ(ファインチューニング)するか、まったく新しいモデルを構築(事前トレーニング)することができます。
この 2 つのオプションは、ファインチューニングされた LLM を使用する RAG のように、組み合わせることもできます。このような組み合わせやGenAI開発のスピードは、GenAIアプリケーションの計画と構築を複雑にする可能性があります。アプローチをシンプルにするために、3つの指針を推奨します。
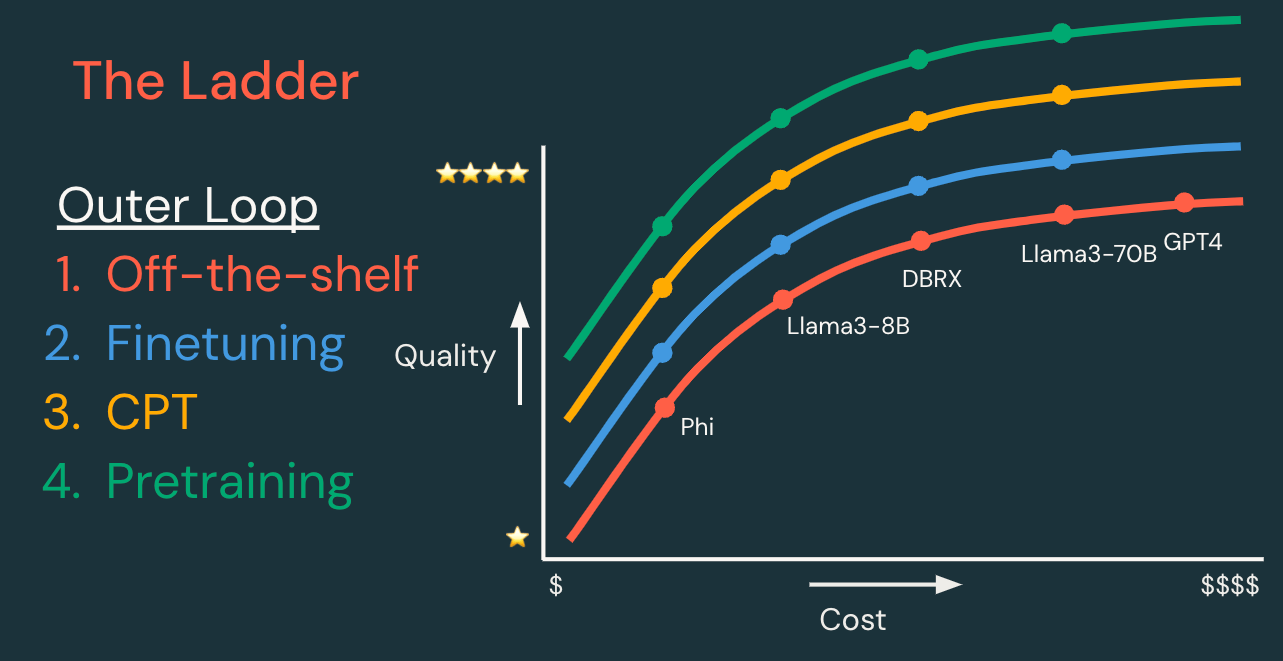
原則1:小さく始めて、徐々にステップアップしていく
GenAI アプリケーションを開発する際は、まずシンプルなものから始め、必要に応じて複雑さを加えていくこと�をお勧めします。これは、Databricks 基盤モデル APIs のような既存のモデルから始め、簡単なプロンプト エンジニアリングを行うことを意味するかもしれません。次に、品質、コスト、速度に関するメトリクスを改善するために、必要に応じて手法を追加します。
手法の「ラダー」は、以下に概説する内部開発ループと外部開発ループに分けることができます。
| 外部ループ: モデルカスタマイズラダー | ||||
| 各ステップは、より高品質であったり、低コストであったり、低レイテンシであったりするモデルを作成する可能性があります。 | データが必要 | 開発時間 | 開発コスト | |
| 既存のモデル | 既存のモデルまたはモデル API から始め、最初に内部ループでイテレーションを行います。 | なし、または RAG のデータ | 時間 | $ |
| 教師ありファインチューニング | 特定のタスクをより適切に処理できるよう、モデルをカスタマイズします。 「このようなクエリーを想定して、あのようなレスポンスを返します。」 | 数百~数万の例 | 日 | $$ |
| 継続事前学習 | モデルをカスタマイズして、ドメインへの理解を深める 「このニッチなアプリケーションドメインの言語を学びましょう。」 | 数百万から数十億のトークン | 週 | $$$ |
| 事前トレーニング | 新しいモデルを作成することで、完全な制御、カスタマイズ、所有が可能になります。 「ゼロからすべてを学ぶ!」 | 数十億から数兆のトークン | 月 | $$$$$$ |
| 内部ループ: 複合 AI 手法 | |
| 以下の各手法は、特定のモデルの生成品質を向上させる可能性があります。これらの手法は(おおまかな)複雑さの順に記載されていますが、組み合わせて使用できます。 | |
| プロンプトエンジニアリング | タスク固有のプロンプトを作成して、モデルの振る舞いをガイドします。 |
| フューショット プロンプティング | 推論時にモデルを学習させるため、プロンプトでデータを提供します。 |
| RAG | クエリー固有のデータを追加のコンテキストとしてモデルに提供します。 |
| エージェント | モデルに呼び出し可能なツール、または複雑な制御フローを提供します。 |
外部ループで 1 ステップ進むのに比べ、内部ループの手法を取り入れる方が比較的安価で高速です。したがって、外側のループを進めるたびに、内側のループにある手法の一部またはすべてを繰り返し試してみる価値があります。この「内部」対「外部」とい��う名称は、システム アーキテクチャから連想されるものとは逆で、複合 AI の「内部」ループがモデルの「外部」ループをラップする形になります。モデルのカスタマイズを「アウター」ループと呼ぶのは、インナー ループとアウター ループの相対的なコストによって規定されるように、ワークフローの観点からそれがまさにアウター ループであるためです。
原則2: データドリブンであること
プロジェクトに本格的に投資する前に、成功の評価基準を慎重に定義し、一般的な評価駆動開発プラクティスに従ってください。
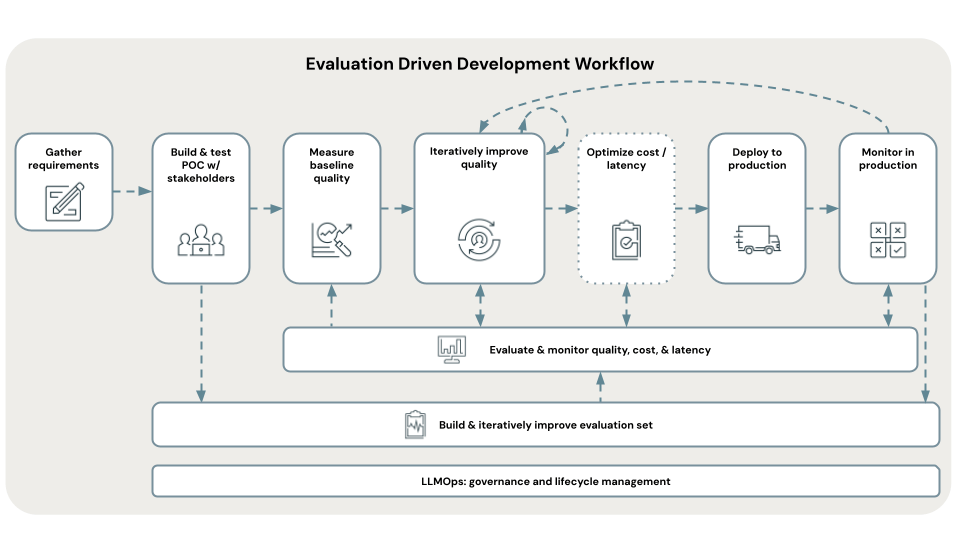
AI システムレベルでは、品質、コスト、レイテンシのメトリクスを考慮してください。
- 品質には、精度、ユーザー フィードバック、有害性など、いくつかのメトリクスが含まれるでしょう。
- コストは、本番運用環境のシステムにかかる場合、通常、モデルの推論とデータ サービングが中心となります
- レイテンシは、エンドツーエンドのレイテンシ、または、よりインタラクティブなアプリケーションにおける最初のトークンまでの時間を意味する場合があります。
成功と判断するには、こ�れらのメトリクスはどの数値を達成する必要がありますか?優れたユーザー エクスペリエンス、プラスの投資収益率、またはその他のビジネス要件を確保するために、これらのメトリクスにはどのような厳しい制約がありますか?詳細については、当社のチーフ AI サイエンティストによるこちらの講演をご覧ください。
プロジェクトレベルとビジネスレベルで、投資収益率を分析します。
- コスト(投資)は 2 つのフェーズに分けられます:
- 開発費用には、データ準備、モデル トレーニング、システム開発のためのコンピュート費用と人件費が含まれる場合があります。
- 継続的な費用には、モデルとデータのサービングやメンテナンス工数などが含まれる場合があります
- ビジネスインパクト(リターン)
- 収益」やその他のビジネス上の目標と主要な結果(OKR)は、人的な時間の節約(生成AIサポートボットの場合)から直接的な収益(生成AI搭載製品の場合)まで多岐にわたります。
- 新しいモデルやデータなどのIPの創出は、測定するのが最も難しい影響かもしれませんが、長期的には最大のものとなります�。誰もが同じモデル プロバイダー APIs を使用できますが、お客様独自のモデルとデータを使用できるのはお客様だけです。
データドリブンな目標が、モデルのカスタマイズに関する選択の指針となります(原則 1)。例えば、高価なモデル API を使用して品質メトリクスは満たしたものの、コスト制約を超過してしまった場合は、品質を維持しながらコストを削減するために、特定のタスクに特化した、より小型で効率的なモデルのファインチューニングに移行することが考えられます。ファインチューニングには追加の開発コストがかかりますが、継続的なコストを削減し、長期的には全体的なコストを抑えます。
原則3:実践的であること
GenAI モデルとシステムの評価は困難です。ファインチューニングと事前学習の手法は、活発に研究されている分野です。学術界と産業界の盛り上がり(そしてLLM)は、到底読み切れないほどのコンテンツを生み出しています。このような混乱の原因があると、いつどの手法を使用すべきかが分かりにくくなります。(「LoRAは必要ですか?カリキュラム学習とは?「どのモデルアーキテクチャが最適ですか?」)
生成AIを初めて使う人の多くは、生成AIに大量のデータを与えると、素晴らしいことを学習すると耳にしたことがあるでしょう。これらの期待を調整しましょう。データの量だけでなく、データの品質、トレーニング手法、評価も重要です。
Databricks のお客様は、GenAI カスタマイズを高度化していく過程で、Databricks に組み込まれたガイダンスを部分的に頼りにすることができます。このガイダンスは、汎用モデル向けのシンプルな APIs から、RAG とエージェントのための Agent Bricks Custom Agents、ファインチューニングのための UI と API、さらには事前トレーニングのためのガイド付き API まで多岐にわたります。
しかし、カスタマイズをさらに進めるほど、検討すべき手法や下すべき決定も多くなります。現実的でいることをおすすめします。研究でうまくいった手法が、実際の応用では機能しない場合があります。あるタスクで優れたモデルも、別のタスクでは劣る場合があります。最適な手法は、時間とともに変わっていきます。この複雑さに対応するには、原則1と2、つまり「目指すべき指針を定義し、データとメトリクスに基づいてそれに従う」ことを念頭に置いてください。
当社との提携もおすすめです。お客様の担当 Databricks チームに加えて、当社のプロフェッショナルサービスチームが、初期の概念実証から本格的な事前学習のランまでご支援します。当社の Databricks AI Research チームは、多くのお客様と事前学習の実行で提携し、最先端の知見やアドバイスを提供しています。
カスタムLLMを構築するための技術
モデルカスタマイズのアウターループをさらに進めたい場合、原則 1で紹介されている手法には、どのように取り組めばよいでしょうか。このセクションでは、評価について説明し、次に主要なカスタマイズ手法を掘り下げます。
注:このガイドでは、固定モデルのイテレーションにおけるインナーループには焦点を当てていません。これらの手法に関する詳しい背景については、「生成AIの基礎」および「Databricksによる生成AIエンジニアリング」の各コースをご覧ください。
このセクションでは、原則 1 の外側のループで先に概説したカスタマイズ手法について詳しく解説します。ここに一覧を示しますが、どの手法を選択するかは主に利用可能なデータによって決まります(原則2)。
| 外部ループ: モデルカスタマイズラダー | ||
| データ型が必要です | データサイズのガイダンス | |
| 既存のモデル | 該当なし | なし、または RAG のデータ |
| 教師ありファインチューニング | クエリーレスポンス データ(あるいは「ラベル付き」データ) | 少なくとも数百~数万件の例 |
| 継続事前学習 | 次のトークン予測用の「生」のテキスト | 数百万から数十億のトークン、または元のトレーニング セットの 1% 以上 |
| 事前トレーニング | 次のトークン予測用の「生」のテキスト | 数十億から数兆のトークン |
次のセクションでは、すべての手法に共通するガイダンスから始め、各手法についてより詳しく解説します。
データ
データはユースケースに適合している必要があります。特定の応答をするようにモデルをファインチューニングする場合、トレーニング データが“良い”応答を示す必要があります。特定のドメインを理解するために継続的事前学習を行う場合、データはそのドメインを表している必要があります。
法的およびライセンスに関する問題には、最初から対処します。公開データを使用する場合、特に事前学習では、法的な問題を回避するために適切にキュレーションされている公開データセットもあれば、そうでないデータセッ��トもあることに注意してください。独自の企業データを使用する場合は、その来歴、特にデータが顧客から提供されたものか、制限付きライセンスを持つ生成AIモデルから得られたものかを必ず確認してください。
データを早期かつ頻繁に収集します。現在お使いのアプリケーションから得られるクエリー、レスポンス、ユーザー フィードバックは、将来の GenAI モデルのチューニングとトレーニングの入力として利用できますが、慎重に取り扱う必要があります。多くのプロプライエタリ モデルやオープンソース モデルには使用制限があるため、生成された回答の来歴を注意深く追跡してください。将来の柔軟性を確保するために、互換性のないライセンスを持つモデルとデータの混在は避け、オープンライセンスを優先してください。
合成データは慎重に使用してください。合成データは有用ですが、ほとんどの場合、実際の企業データの方がより価値があります。「実際」のデータは、LLMに合成データの生成方法を教えるために使用できます。これについては、このガイドの後半で学びます。合成データは、まだ活発な研究分野です。
モデル
ベースモデルとインストラクト/チャットモデルの違いにご注意ください。ほとんどの主要なLLMリリースには、ベースモデル(事前学習済みだがファインチューニングはされていない)と、指示追従型またはチャットのバリアント(ファインチューニング済み)の両方が含まれます。どのタイプを使用するかについての推奨事�項は、以降のセクションをご覧ください。
Databricks の機能によって提案されたモデルを使用します。Databricks AI Research は、最先端のモデルアーキテクチャを研究し、GenAIモデルに関するトップクラスの推奨事項をいくつか共有しています。また、Databricks Model トレーニング やその他の機能では、これらのトップモデルを優先的に扱っています。
必要に応じて、より詳細なカスタムコードを記述することも可能です。If default models or training methods don’t fit your needs, then you can always “drop down the stack” and use more customized code. defaultのモデルやトレーニング方法がニーズに合わない場合は、いつでもスタックの階層を下げて、よりカスタマイズされたコードを使用できます。Databricks GPU アクセラレーテッド クラスター (汎用コンピュート) と Databricks モデル トレーニング (特化したディープラーニング コンピュート) は、GenAI やその他のディープラーニング モデル用の任意のトレーニング コードを両方ともサポートしています。
お客様のユースケースで有望なモデルを特定しましょうチューニングの前に、汎用モデルがお使いのアプリケーションで有望であるかを確認してください。「見込み」は、AI Playground を使用したアドホックな手動テスト、またはベンチマーク データセットかカスタム評価データセットを使用した、より厳格なテストによって測定できます。テストには、小規模なトレーニングが必要になる場合があります。100件という少数のサンプルでファインチューニングすると、モデルの性能は向上しますか?事前学習では、特定のデータセットで学習を続けることでモデルは改善しますか?
制約を覚えておいてください。推論時のコストとレイテンシの制約に基づいて、モデルサイズを選択してください。また、カスタムモデルの構築はアウターループにすぎず、よりシンプルなリクエストを小さなモデルにルーティングするなど、インナーループでコストとレイテンシを最適化することもできる点を覚えておいてください。
ヒント: これらの手法は一連の流れになっているため、簡単な手法での作業も無駄にはなりません。例えば、モデルを事前学習した後は、通常、教師ありファインチューニングを行います。
評価
原則 2 では、 メトリクス を用いてデータドリブンであることが推奨されています。カスタムモデルの構築について詳しく説明する前に、作業の指針となる評価と品質に関するメトリクスについて説明します。
ソフトウェア エンジニアリングと同様に、テスト ピラミッドに従うことをお勧めします。
| ソフトウェアテストのアナロジー | 速度/コストと忠実度の比較 | 例 |
| 単体テスト | 高速で安価な代理指標 | 正解・不正解のあるテスト |
| 統合テスト | 中程度の速度/コストのテスト | ベンチマークデータセットにおけるLLM-as-a-judgeメトリクス |
| エンドツーエンドテスト | 低速ながらも現実的なテスト | 人間によるフィードバック |
上記のテストピラミッドの例は汎用的に記述されており、モデルのテスト(原則1からのアウターループ)と複合AIシステム(インナーループ)のテストという問題を回避しています。カスタムモデルを構築する際は、モデル自体とそれを使用する AI システムの両方をテストする必要があります。たとえば、「LLM-as-a-judge メトリクス」は、モデルの指示追従能力のテストや、RAG システムの検索メトリクスおよび質問応答メトリクスのテストに使用できます。
特定対汎用のモデルとタスク
特定のタスクに合わせてモデルをファインチューニングする場合のテストピラミッドは、汎用モデルを事前学習する場合と比べて大きく異なります。データとメトリクスに基づいたということは、モデルの下流のユースケースに合わせてテスト ピラミッドを調整するということです。
特定のタスクに合わせてモデルをファインチューニングする場合は、小さく始めることを忘れないでください(原則1)。たとえば、次のようなことができます。
- 評価用の�「ゴールデン」クエリー応答データセットを作成します。想定されるクエリーとトピック全体でバランスが取れるようにしてください。
- LLM-as-a-judge メトリクスを使用して、評価をスケールアップできます。特定のタスクに合わせて、メトリクスを選択またはカスタマイズできます。
- 最終テストとして、人間またはユーザーによる評価を使用してください
継続的な事前トレーニングまたは完全な事前トレーニングを開始すると、評価がより複雑になる可能性があります。テストピラミッドを計画する際は、重要な領域に集中できるように、モデルに必要だと考えられるさまざまなスキルセットに沿って評価を分解してください。次のことが考えられます:
- 一般知識、論理、読解力などのスキル
- 金融、法律、医療などの分野
- 言語、自然言語やプログラミング言語など
- その他の側面、コンテキスト長から組み込みのガードレールまで
ヒント:
- ユースケースに合わせて評価を調整してください。たとえば、モデルを修正してより長いコンテキスト長を扱えるようにする場合、継続的な事前学習のパープレキシティ指標だけでは十分ではないことを覚えておいてください。評価データセットには、ロングコンテキスト タスクも含める必要がありま�す。
- 学習と忘却の両方をテストします。継続事前学習で特定の言語(例: マレー語)に対するモデルの理解度を向上させる場合、お使いのユースケースでそのモデルが既存の言語(例: 英語)の理解度を維持する必要があるかどうかを検討してください。その場合は、評価でマレー語と英語の両方をテストする必要があります。
- 顧客が実際に使うものをテストしましょう。新しい(ベース)モデルを事前学習する場合、顧客が実際に使用するモデルのバージョンを作成するために、指示ファインチューニングを行うことになるでしょう。最終(エンドツーエンド)評価は、ベースモデルではなく、ファインチューニングされたモデルで行うべきです。
DBRX構築の事例
2024年5月、Databricks は DBRX をリリースしました。これは、当時最先端のオープンソース LLM です。その評価スイートは、テストピラミッドの良い例です。以下にその概要を示します。
| ソフトウェアテストのアナロジー | DBRX構築時のメトリクスの例 | |
| 単体テスト | モザイク評価ガントレット | 言語理解、読解力、記号的問題解決、世界知識、常識、プログラミングという6つの中核的��能力に分類される、39の公開ベンチマーク |
| 統合テスト | MT-Bench | マルチターン会話と指示追従のベンチマークデータ |
| IFEval | 指示追従ベンチマーク データ | |
| アリーナ ハード | Chatbot Arena ベースの、人間の選好ベンチマークデータ用ジェネレータ | |
| エンドツーエンドテスト | 社内および顧客からのフィードバックと A/B テスト | 社内外のユーザーによる反復テストで、A/B テストのメトリクスと人間によるアノテーションの両方を収集します |
| レッドチーミング | 専門家によるテストで、望ましくない(攻撃的、偏見のある、その他安全でない)出力を生成 |
評価メトリクスに関する背景情報の詳細については、こちらのGenerative AI Engineeringコースがおすすめです。ツールとしては、自動(LLM-as-a-judge)メトリクス、評価データセット、人による評価アプリをサポートするDatabricks MLflowをおすすめします。エージェント評価では、オープンソースのLLM評価用のMLflow APIsを使用します。事前学習に関するより高度な評価については、お客�様と協力してカスタム評価プランを策定いたします。
教師ありファインチューニング
ほとんどの実務者がモデルのカスタマイズに用いる最初のテクニックは、教師ありファインチューニング(SFT)です。これは、特定のタスクや動作に合わせてモデルを最適化するために、ラベル付きデータでモデルをトレーニングする手法です。
ユースケースの例:
- 名前付きエンティティ認識: ドメイン固有のエンティティを認識するようにモデルをファインチューニングします
- チャット補完と質問応答: 特定のトーンで応答するようにモデルをファインチューニングします
- 出力形式: 特定の構造化された出力で応答するようにモデルをファインチューニングします
- 指示への追従: 汎用モデルの事前学習後、単に補完テキストを生成するのではなく、指示やクエリーに応答するようにモデルを学習させるために、インストラクション・ファインチューニングを行うのが一般的です。
用語: 「ファインチューニング」は「教師ありファインチューニング」を意味するものとしてよく使われますが、技術的には既存のモデルのあらゆる適応を指します。継続的な事前学習と人間からのフィードバックによる強化学習(RLHF)も、ファインチューニングの一種です。
ファインチューニングは、断然最も高速で安価なモデルのカスタマイズ方法です。たとえば、2023年5月にリリースされたMPT-7Bモデルでは、指示ファインチューニングで960万トークンを処理するのに46ドルかかったのに対し、事前学習で1兆トークンを処理するには250,800ドルかかりました。
データ
データを準備する際には、内容とフォーマットが鍵となります。ファインチューニングの大部分は、モデルにどのような入力を想定し、どのような出力を期待するかを教えることです。ユーザーのクエリーは、形式、トーン、トピックの範囲などの点で、どのようなものになるとお考えですか?トレーニング データは、これらの期待を反映している必要があります。
データサイズはよくある質問のトピックであり、最終的にはユースケースによって決まります。場合によっては、数百から数千例といったごく少数のデータセットでファインチューニングを行っても良い結果が得られますが、アプリケーションによっては数万から数十万の例が必要となります。まず小規模で始めて計画を検証し、その後、必要に応じてトレーニング データセットを拡充しながら、繰り返しスケールアップしていきましょう。
合成データはSFTで役立つことがあり、最も一般的には、少なすぎる「実」データを拡張するために使用されます。LLMは、プロンプトに応じて、実データの例に類似した合成SFTデータを生成できます。
Databricks Model Training 用のデータ準備に関するドキュメントも参照してください。
モデル
このガイドの��前半では、デフォルトで Databricks Model Training がサポートするモデルを使用し、ご自身のユースケースでそのモデルが有望かどうかをテストすることをお勧めしました。この良い例はMPTからもたらされました。MPTは日本語を想定してトレーニングされたわけではありませんが、日本語のプロンプトとレスポンスの例を100件使用して簡単なファインチューニングテストを行った結果、ある顧客にとって驚くほど効果的なモデルが生まれました。その簡単なテストによってアプローチの有効性が検証され、より大規模なファインチューニングへの道が開かれました。
モデルサイズを選択する際は、大きめのモデルから始めることを検討してください。小規模なデータセットでチューニングする場合、小規模なモデルよりも大規模なモデルの方が、良い結果が得られる可能性が高くなります。大規模モデルから始めることで、データとユースケースの可能性を知ることができ、また、SFT は比較的低コストです。可能性が見えたら、より小さいモデルとより多くのデータでテストできます。
SFTは、ベースモデルまたは instruct/chat バリアントのモデルで実行できます。By default, 特にデータセットが小さい場合は、instruct/chat バリアントを使用することをおすすめします。継続的な事前学習を実行してカスタムベースモデルを作成した場合、そのカスタムベースモデルで SFT を実行できます。
Databricks モデルトレーニング
Databricks モデルトレーニングは、 教師ありファインチューニングタスク 用のシンプルなインターフェース ( UI と API) を提供します。このガイドですでに紹介したデータとモデルに関するヒントに加えて、次の点を考慮してください。
- タスク: SFT タスクは、想定されるクエリー形式に応じて、さまざまな方法で指定できます。なお、指示タスクの場合でも、一般的な標準に合わせるため、defaultではチャット補完フォーマットの使用を推奨します。
- 設定: イテレーションを重ねる中で、最初に最適化すべきハイパーパラメータは学習率です。従来の機械学習(ML)アルゴリズムで学習率を調整するのと同様に、まずレートのグリッドを試し、次に最も良かった初期レートを中心として、より細かい粒度の学習率のグリッドに絞り込みます。また、学習の進捗プロットに基づいて、トレーニング期間(エポック数または�トークン数)の調整もご検討ください。ファインチューニング タスクは、少ないエポック数で済む場合もあれば、50 エポック以上で効果が出る場合もあります。
- 評価: 評価データセットを指定すると、Databricks Model Training で初期評価 (「ユニットテスト」) が計算されます。50 組のクエリーとレスポンスのペアというごく小さなデータセットでもシグナルを得られますが、より大規模で多様なデータセットの方が優れています。特に、トレーニング時の評価損失(または精度)がエンドユーザーの評価とうまく相関しない可能性があるため、より徹底的な評価にはDatabricks MLflowを使用してください。
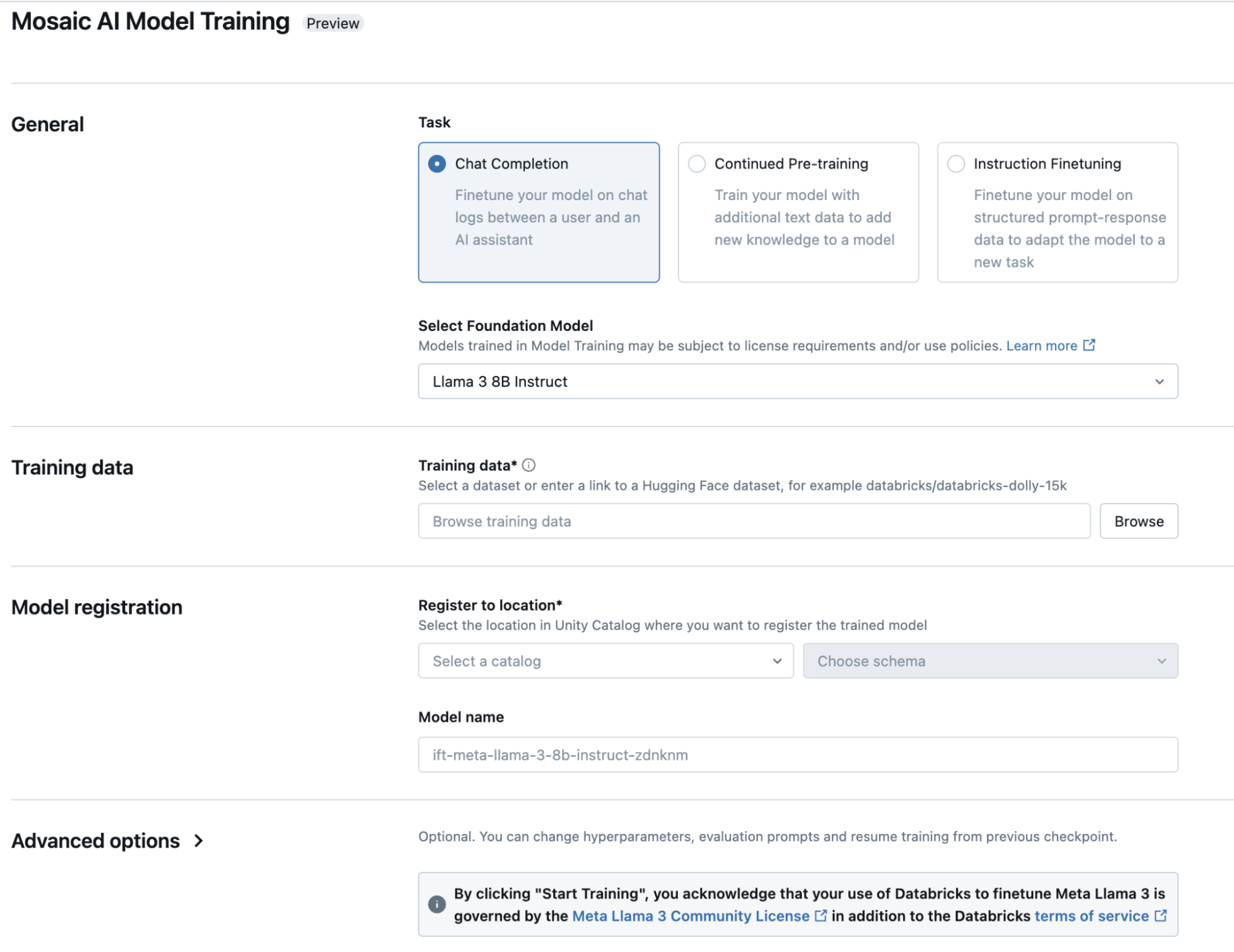
教師ありファインチューニングの詳細
defaultでは、シンプルで効率的なワークフローのために Databricks モデルトレーニングをおすすめします。ただし、サポートされていないモデルアーキテクチャを使用する必要がある場合や、よりカスタマイズされたチューニング方法が必要な場合は、DatabricksのGPUアクセラレーション付きクラスター(汎用コンピュート)およびDatabricks Model Trainingで完全にカスタムのコードを実行できます。
このガイドでは、低ランク適応(LoRA)など、ファインチューニングと推論をより効率的にするための一連の手法である、パラメータ効率の良いファインチューニング(PEFT)については詳しく説明しません。これらの手法の説明と例については、こちらのブログ、こちらのブログ、またはHugging Face PEFTをご覧ください。
継続事前学習
教師ありファインチューニング(SFT)は、モデルに新しいドメインを理解させるためのものではありません。新しい言語、ニッチな業界、その他の特定の分野を理解できるようにモデルをカスタマイズするには、実務者は継続的な事前学習(CPT)を利用できます。CPTは事前学習と似ていますが、既存の事前学習済みモデルを使って新しいデータでの事前学習を継続する点が異なります。CPTで新しいドメインに適応させた後、モデルは一般的に教師ありファインチューニングによって特定のタスクに適応されます。
ユースケースの例:
- 言語: 汎用モデルは、トレーニング データで多くの自然言語に触れていることが多いですが、主要な言語以外には弱い場合があります。CPTは、特定の言語に対するモデルの理解度を向上させることができます。
- プログラミング: 汎用モデルは、トレーニングデータで少なくとも数種類のプログラミング言語を学習していることがよくありますが、主にコーディング用に設計されているわけではなかったり、特定のプログラミング言語を十分に理解できなかったりする場合があります。CPTは、モデルに特定のプログラミング言語でコーディングする方法を学習させることができます。
- 専門分野: 汎用モデルは、分子生物学、環境法、金融規制といった特定のトピック分野に関する深い知識を持っていない場合があります。CPTは、特定のドメインに関するモデルの知識と理解を向上させることができます。
RAG Q&Aボットの指示追従モデルを改善するには、教師ありファインチューニング(SFT)と継続事前学習(CPT)のどちらを使用すべきですか?
どちらの手法も適用できますが、どのようなトレーニング データがあるか、またモデルの何を改善したいかによります。モデルが特定の方法で応答するように学習させたい場合は、トレーニング用のクエリ応答データがあれば SFT を使用します。モデルがドメインや言語を理解できない場合、トレーニング用のテキストデータが大量にあれば、CPT を使用してください。CPTの後は、モデルにクエリへの応答方法��を再学習させるため、SFTを実行する必要がある可能性が高い点に留意してください。
SFT や CPT を使用して、モデルに新しい知識や事実を教えることはできますか?
はい、どちらの手法でもある程度の知識を伝えることはできますが、CPT の方がより適しています。いずれにせよ、ソースデータで回答をグラウンディングし、AI システムを堅牢なものにするには、RAG が必要になるかもしれません。
データ
CPT に必要なデータを検討する際には、原則 2(「データドリブン」)を覚えておいてください。元のモデルについて、何を改善したいですか?データは、モデルに組み込みたいドメイン、言語、知識などを表している必要があります。特定のユースケースでは、これは、そのユースケースに関連する貴社独自のエンタープライズ データ(社内のナレッジベース ドキュメント、過去 20 年間の関連研究論文など)で CPT を実行することになるでしょう。より汎用的なモデルの場合、データに関するガイダンスは 事前学習 の場合と似てきます。ユースケースで重要となるさまざまなスキルセットを表現するために、複数のデータセットを選択することがあります。
ヒント: 忘却・学習。CPTをテストする際は、過去の知識の忘却と新しい知識の学習の間にトレードオフがあることを念頭に置いてください。目標は、CPT トレーニング データを模倣するようにモデルの挙動をシフトさせることですが、それによって元の事前学習データの特徴が失われる可能性があります。したがって、CPT トレーニングデータと評価スイートの両方が、対象とするドメインをカバーするようにしてください。
データ形式については、データは「生」テキストになります。つまり、事前学習と同様に、CPT を実行して次のトークンの予測を行います。
データサイズについては、CPTは少数のトークンでモデルを微調整することも、多数のトークンでモデルを大幅に変更することもできます。「少ない」と「多い」はモデルサイズによって異なりますが、現代の中規模LLMの場合、数十億トークンが妥当な推定値です。経験則として、CPT には元のトレーニング セットのサイズの少なくとも約 1% が必要です。
CPT用の生データとSFT用のプロンプト応答データの両方が必要ですか?
CPT に続いて SFT を実行している場合は、はい。ただし、CPTのデータはあってもSFTのデータが少ない場合は、他のSFTデータセットや合成データを使用し、クエリーとレスポンスのデータで小規模なSFTデータセットを拡張できます。
合成データは CPT、特に、大規模で強力なモデルを使用してデータを生成し、より小さなモデルのトレーニングする蒸留において有用です。蒸留は、モデルの小型化、高速化、低コスト化に役立つだけでなく、ユースケースに特化した非合成データを補うこともできます。
Databricks Model トレーニングのデータトレーニングに関するドキュメントも参照してくださ��い。
モデル
SFTの場合と同様に、defaultではDatabricks Model Trainingでサポートされているモデルを使用し、お客様のユースケースに対してモデルが有望かどうかをテストすることをお勧めします。
ベースモデルと指示/チャット バリアントのどちらをチューニングするか、また CPT の後に SFT を実行するかに関する当社の推奨事項は、相互に絡み合っています。最も一般的で、defaultで推奨される方法は、ベースモデルで CPT を実行し、その後にインストラクションまたはチャットのファインチューニングのために SFT を実行することです。ただし、ニュアンスがあります:
- ベース vs 指示/チャット バリアント: CPT はベースモデルで実行するのが最も一般的です。インストラクト バリアントまたはチャット バリアントで、大規模なデータセットを使用して CPT を実行すると、モデルの指示追従能力や対話能力が一部失われる可能性があります。
- CPT 後の SFT: 大量のデータで CPT を実行した場合、その後で SFT を実行することになるでしょう。しかし、少量のデータを使用して指示追従モデルまたはチャットモデルで CPT を実行する場合、その後の SFT は不要になる可能性があります。一部の顧客はこれを行い、その結果として得られたモデルをアプリケーションで直接使用しています。
Databricks モデルトレーニング
Databricks Model Trainingは、CPT向けのシンプルなインターフェース(UIとAPI)を提供します。このガイドで先に述べたSFTのヒントは、CPTにもほとんど当てはまります。モデル トレーニング機能では、CPT と SFT の両方を便利に実行できます。
CPT は SFT よりもモデルを根本的に変更する可能性があるため、前回の 評価 のディスカッションで言及したテストピラミッドには、より堅牢で汎用的なテストが必要になります。CPTをスケールアップするにつれて、テストピラミッドは事前学習のテストスイートのようになっていくかもしれません。
CPT の詳細
CPT ワークロードがよりカスタマイズされ、大規模になるにつれて、以下で説明する事前トレーニング スタックを検討することもできます。
CPTは、事前学習用のデータをテストするのに役立ちます。CPT データが新しいドメイン(新しいコーディング言語など)を対象としている場合、CPT での成功は、そのデータが事前トレーニング データセットの一部として役立つ可能性があることを示しています。
事前トレーニング
お使いの GenAI アプリケーションが継続事前トレーニングの段階まで進み、アプリケーションを改善するために必要な次のステップが、完全なカスタムモデルの事前トレーニングであるとお考えだとします。このセクションでは、プロセスとベストプラクティスの概要を説明しますが、実際には、お客様の Databricks チームと一緒に事前トレーニング プロセスを進めてください。
いきなりプレトレーニングから始めるべきですか?
いいえ。たとえ規制上またはその他の制約により、完全に所有する新しいモデルを作成する必要がある場合でも、まずはより低いレベルのカスタマイズでプロトタイプを作成することをおすすめします。これにより、より高コストで複雑な事前学習のリスクを軽減できます。
事前学習のステップは何ですか?
実際、事前学習は反復的、適応的なプロセスですが、事前学習における高レベルの一般的なステップには、次のようなものがあります。
- まず、ファインチューニングと継続事前学習から順に取り組んでください。入念に確認してください!
- データセットを準備する。これはステップ1で行われ、CPTが特定のデータセットの有用性をテストするのを支援します。
- テキスト補完ができるベースモデルを事前学習します。これには、トレーニングのモニタリング、ラン中の微調整、カリキュラム学習のような適応的手法によるデータミックスの調整などが含まれます。
- 指示またはチャットのファインチューニングを実行して、指示/チャット バリアントを作成します。
- 人間のフィードバックによる強化学習(RLHF)などの手法を使用して、モデルをさらに微調整することも可能です。
- 上記の各ステップを通して、随時モデルを評価してください。
完全な事前学習は比較的高コストであるため、この簡単な手続きの概要では、デューデリジェンスと評価を重視しています。事前学習にインストラクション ファインチューニングの 5452 倍ものコストがかかった、先に挙げた MPT-7B モデルの例を思い出してください。
データ
データの選択と処理は、事前トレーニングのランの成功を大きく左右します。
何のデータですか?
データミックスは、ターゲット アプリケーションを代表するように慎重に選択する必要があります。
- モデルに持たせたいスキルセットに応じて評価を細分化する必要があるように、事前学習に持ち込む各データセットがモデルに何を学習させるかを考慮してください。継続的な事前トレーニングを使用して、これらのデータセットの影響を事前にテストできます。
- トップパフォーマンスのモデルで、そのデータミックスの詳細を公開しているものはほとんどありません。古いモデルの中には、リストを公開しているものもあります(例: MPT、LLaMA、OLMo)。こちらのデータミックスのディスカッションもご覧ください。
- 公開データセットと独自データセットを組み合わせることになるでしょう。適切に精査された公開データセットは、言語能力や一般的な知識、特定のスキルセットを学習させるなど、トレーニングのニーズの一部を満たすことができます。独自のデータセットは、モデルに他にはない競争優位性をもたらします。
データの量と質はどちらも重要ですが、それぞれ重要になるタイミングは異なります。より緩い品質管理で「すべてのデータ」について事前学習を開始することは一般的です。当初は、トークンの数が多いほど、基本的な言語能力をより多く学習することになります。ただし、後の事前学習では、データミックスをより小規模で高品質なセットに変更するのが一般的です。「高品質」に学術的な定義はありませんが、直感的には常識的な手法を用いてキュレートされたことを意味します。データ準備の詳細については、以下を参照してください。
データ量は?
- データサイズは、モデルサイズとアーキテクチャを考慮して選択する必要があります。
- 「Chinchilla」の経験則は最も有名な法則で、トークン数 = 20 * パラメータ数となります。推論コストを削減するには、このLLaMA の論文の結果にあるように、より多くのデータでより小さいモデルをトレーニングして、同等の生成品質を達成することをおすすめします。
- 混合エキスパート(MoE)アーキテクチャは、特定のモデルサイズに対して必要なデータが少ないことが多いため、この計算を変えることができます。MoE の場合、この計算には総パラメータ数ではなくアクティブなパラメータ数を使用してください。
- タスクには難しいものもあることを覚えておいてください。たとえば、7Bパラメータモデルは、HumanEvalコーディングベンチマークに取り組むために、一般的に少なくとも2兆トークンのトレーニングデータを必要とします。
データはどのように準備すればよいですか?
- download and parsing: 一般的に、データはご自身で取得する必要があります。インターネット規模のデータを事前にダウンロードした状態で提供しているプロバイダはほとんどなく、規制要件は顧客ごとに異なる場合があります。
- クリーニング: 事前学習では大量の低品質なデータを活用できますが、データ品質を向上させる価値はあります。例えば、この RefinedWeb の論文では、Common Crawl の約 11% が有用であると推定しています。事前学習のためのデータ クリーニングは、大きく厄介なトピックであり、多くの研究が活発に行われています。一般的なステップに関する優れた概説については、この論文をご覧ください。次のようなステップがあります。
- 言語フィルタリングで、関心のある主な言語にテキストを絞り込みます
- ヒューリスティック フィルタリングで、ボイラープレート テキスト、短すぎる、または長すぎるドキュメント、非自然言語のテキストなどを除去
- 品質フィルタリングで、人間が作成またはレビューした可能性が高いテキストを識別
- ドメイン フィルタリングで関心のあるドメインに関するテキストを識別
- データセット内またはデータセット間のコンテンツの重複排除
- 送信元またはテキストに基づく有害で露骨なコンテンツのフィルタリング
- これらの手法にはすべて注意点があることにご注意ください。それぞれについて、フィルターの厳格さは、適合率と再現率のトレードオフを考慮して調整する必要があります。このフィルターが不適切に作用することもあります。重複はテキストの正当性や重要性が高いことを示している場合があるほか、有害なコンテンツに触れたことのないモデルは有害性を認識できず、有害なユーザー入力を安易に繰り返してしまう可能性があるためです。
- 前述のとおり、初期の事前学習では、より緩やかな品質管理でより多くのデータを使用することがあります。一方、後期の事前学習では、より入念にクリーニングされたデータのサブセットに重点が置かれる場合があります。
- 事前計算: データを事前トークン化して連結し、事前トレーニング用に形式を最適化することで、効率を向上させることができます。
データ処理は、Databricks が元来得意としてきた分野です。以下をご活用ください:
- ジョブとオーケストレーションを定義するワークフロー、およびApache Spark™とDelta の最適化によるスケールアウト処理
- データ ストレージ フォーマットとして Delta Lake を使用
- Unity Catalogによるデータマネジメント
- ノートブック、IDE 統合、Databricks SQL を使った開発とデータ探索
- データ パイプラインとソースを長期的にモニタリングするためのLakehouse Monitoring
モデル
研究者は新しいモデルアーキテクチャを画期的な進歩だと宣伝しますが、2017年に発表された Transformer アーキテクチャがいまだに主流であり続けているのには理由があります。非常にうまく機能するからです。同様に、一般的には、次のような実績のあるアーキテクチャを採用することをおすすめします。
- 研究段階の検証が不十分な手法ではなく、クアドラティック アテンションや FlashAttention-2 などの標準的なアテンション メカニズムを使用してください
- より効率的なトレーニングと推論、および低精度演算のために、エキスパート混合(MoE)アーキテクチャの導入をご検討ください。
- 次のトークン予測を使用してトランスフォーマーをトレーニングします
Databricksは任意のアーキテクチャでの事前トレーニングをサポートしていますが、 Mosaic LLM Foundry や Mosaic Diffusion などのツールのマネージドで最適化されたバージョンを提供する Databricks Model Training を通じて、推奨される主要なアーキテクチャ向けにより簡単な事前トレーニングセットアップを提供しています。このツールは、標準的で十分にテストされたdefaultを提供することで、選択を簡素化できます。たとえば、2024年7月現在、LLM Foundry は標準的なアテンションメカニズムとして FlashAttention-2 を推奨しており、DBRX などの MoEs アーキテクチャをサポートしています。お客様の特定のアプリケーションに合わせて、アーキテクチャの詳細についてアドバイスいたします。
モデルサイズに関しては、小さなものから始めることを覚えておいてください (原則 1)。7B パラメータモデルのトレーニングは、70B モデルに比べてコストが約 10 分の 1 であり、スケールアップする際のモデリングの選択に役立ちます。また、ユースケースのレイテンシとコストの制約を、モデルサイズの上限として考慮してください。
トレーニングスタックとインフラストラクチャ
データとモデリングの準備が整い、事前学習を開始できるようになりました。こ��れは、GenAI を使用する上で最もコストのかかるステップとなる可能性があるため、これまでのステップでは入念な準備が必要でした。このステップでは、事前学習をスムーズに実行するために、堅牢なツールと専門家による助言を活用することがきわめて重要です。
事前トレーニングには多くの課題があります。Databricks プラットフォームでは、これらの多くの課題が自動的に処理されます。
| 課題 | Databricks |
| データの読み込み: 数兆個のトークンを読み込む必要がある場合があります。 | Databricksは、高速なStartupと復旧時間を提供します。 |
| スケーリングと最適化: GPU を数十台から数千台にスケールする必要がある場合があります。トレーニングのパフォーマンスを最適化するための手法は数多くあります。 | Databricksは、データ並列処理とFSDPによるシームレスなスケールアウト、そして構成可能な最適化のライブラリを提供します。最高水準のモデルFLOPS利用率(MFU)を達成しています。 |
| 障害復旧: ほとんどのクラウドでは、1000 GPU 日あたり約 1 回のインフラストラクチャ障害が見込まれます。事前学習ジョブでは、損失スパイクまたは発散が発生することがあります。 | Databricks は障害を自動的に検出し、高速で再起動します。トレーニング スタックは、損失スパイクも低減します。 |
| 決定性: 分散データ読み込みとトレーニングでは決定性の確保が困難になります�が、リカバリーや再現性の観点からは重要です。 | Databricksのデータローディングとトレーニングアルゴリズムは、事前学習をはるかに再現しやすくします。 |
Databricks Training スタックは、ハードウェアからワークロード管理まで及びます。次の表に、最初に学習すべき重要な項目を示します。
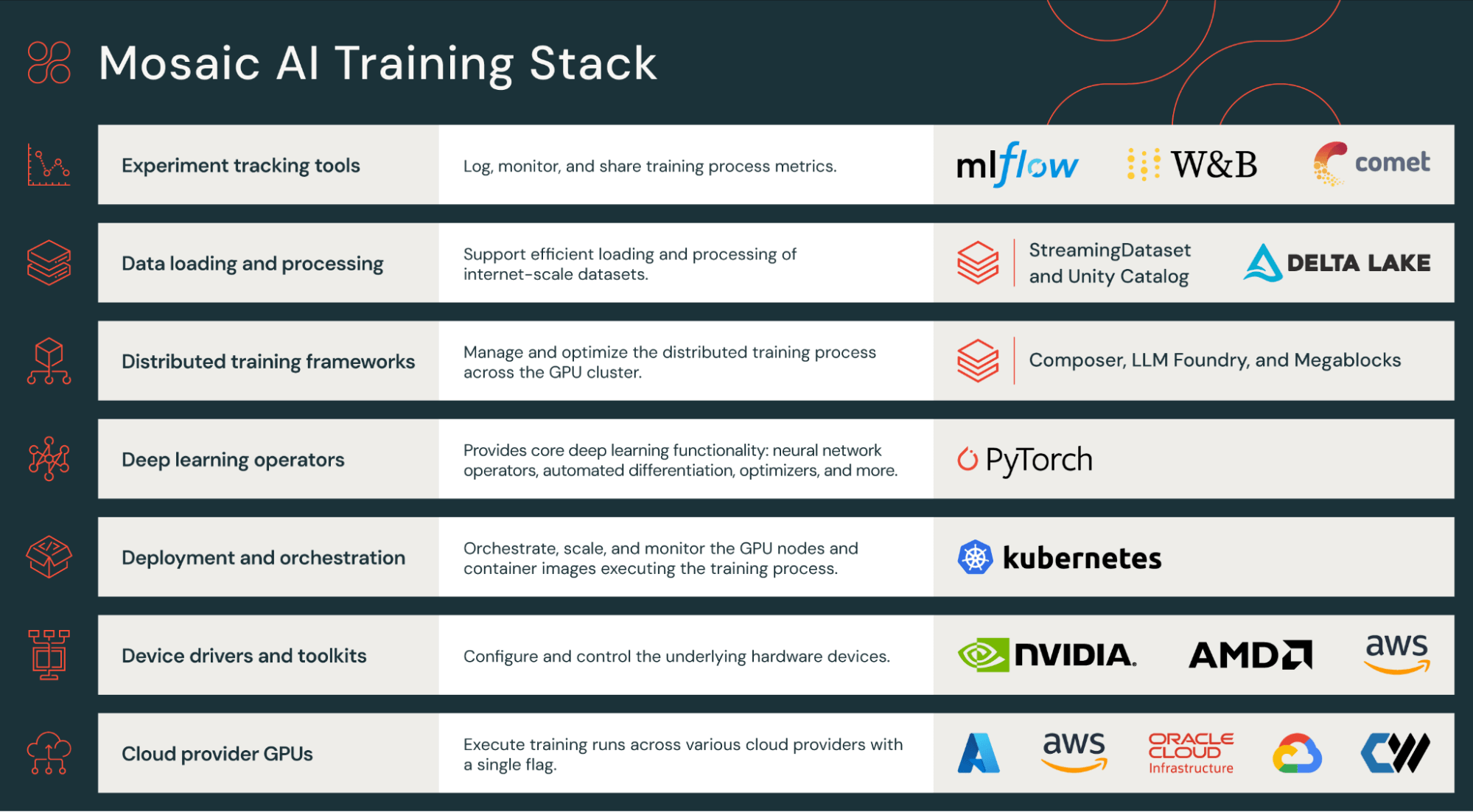
| ステージ | Databricks コンポーネント | 詳細 |
| データの読み込み | ストリーミングデータセット | 高速な起動と再起動を含め、クラウド ストレージからトレーニング データを高速かつ再現可能にストリーミングします。 |
| トレーニング | コンポーザー | 効率的な分散トレーニングのための、構成可能なベストプラクティスとテクニックを提供します。 |
| ワークフロー設定 | LLMファウンドリ | データ準備、トレーニング、ファインチューニング、評価を含むワークフローを簡単に定義できます。Databricksは、一般的な�アーキテクチャのプレトレーニングを開始するための標準構成を提供しています。 |
| 実験の追跡 | MLflow | 事前学習のラン中に、評価およびその他のメトリクスを追跡します。Databricks は Weights & Biases もサポートしています。 |
お使いのユースケースが、LLM Foundryによって構成の「レシピ」として示されている確立された手順に従う場合、ワークフローは非常に構成主導になる可能性があります。あるいは、よりカスタムなアーキテクチャやコードが必要な場合は、MCLIのようなスタックの低レベルな部分に焦点を当て、Databricksインフラストラクチャをより直接的に扱うこともできます。
計算と費用
モデルを事前学習する前に、コストを見積もることが重要です。事前学習のコンピュートコストは、データとモデルのサイズに基づいて GPU 時間を見積もることに帰着するため、多くの場合、簡単に見積もることができます。Databricks チームは正確な見積もりを提示できますが、どのプロバイダについても、2 つの重要な計算について必ず理解しておいてください。
FLOPS = 6 x パラメータ x トークン
この経験則は、コンピュート(およびコスト)がモデルサイズとデータサイズに比例して増加することを示しています。なお、MoE のようなスパース アーキテクチャでは、「パラメータ」は「アクティブ パラメータ」を意味します。
モデル FLOPS 使用率(MFU)= 実際の平均 GPU 使用率
実際の MFU が 100% になる��ことはなく、多くの場合、それをはるかに下回ります。モデルやデータタイプによって、達成できるMFUは異なります。Databricks スタックは、最高性能の MFU を達成するよう最適化されています。
エポックについてはどうですか?
N エポックのトレーニングは、1 エポックの N 倍のコストがかかります。ただし、事前学習では1エポックのみを使用するのが一般的ですが、トレーニングで一部の重要な高品質データを繰り返すこともあります。これは、従来のディープラーニングで使用される多くのエポックとは異なります。背景について詳しくは、こちらの論文をご覧ください。
事前学習のコンピュートコストの他に、次の項目も見込んでください。
- データの購入、キュレーション、ラベリングなどのデータコスト
- 推論コスト
事前学習中
事前学習を開始すれば、Databricks 上ではそのままでも問題なく機能することが多いですが、トレーニングを監視し、デバッグや学習の改善方法を把握しておくことは依然として重要です。Databricks チームが、問題の監視とデバッグをサポートします。
モニタリングには、主に 2 つの領域があります:
- インフラストラクチャ:Databricks Training は、ほとんどのインフラス�トラクチャの問題に対応します。例えば、GPU、ネットワーキング、またはその他のインフラストラクチャで障害が発生した場合、自動的にチェックポイントが作成され、トレーニングが再開されます。ただし、特に非標準の構成を使用する場合は、使用率を監視することが重要です。
- 学習の進捗: データや設定の問題を確認するため、トレーニング データと評価データでの損失やその他のメトリクスをモニタリングする必要があります。注意すべき最も一般的な兆候は、損失スパイクと発散です。Databricks Training では、ライブモニタリングと事後レビューのために、defaultでMLflow Experiments へのロギングを推奨します。
デバッグで最も頻繁に必要となる調整:
- 設定: 設定が不適切だと、こうした問題はトレーニングの初期段階で現れることが多くあります。学習率は、調整が必要な最も一般的な設定です。
- データ: 例えば、よくあるトレーニングの問題の 1 つに、不適切にシャッフルされたデータセットによる損失スパイクの発生があります。Databricks TrainingはMosaic Streamingライブラリによってシャッフルを簡単にしますが、シャッフルにはコストがかかるため、Streamingは品質とコストのトレードオフに対応できるよ�うさまざまなシャッフル設定をサポートしています。損失にスパイクが見られる場合、ストリーミング のシャッフル設定をより強力にすることで、スパイクを防げる可能性があります。例えば、データが異なるバケット(ドメイン、言語など)から取得されており、適切にシャッフルされていない場合、損失のスパイクが発生しやすくなります。
カリキュラム学習: 事前学習は、多くの場合、単一で均質なデータセットでは実行されません。最終モデルは、トレーニング プロセス中にデータミックスを変化させることで改善できることがよくあります。そのための最も一般的な手法がカリキュラム学習です。この手法では、トレーニングの後半になるほど、より高品質で的を絞ったデータセットがデータミックスで重視されます。データミックスは事前に指定することも、特定の分野でモデルを強化するために手動で調整することもできます。
事前学習の後
事前学習の後、モデルを最終的なアプリケーション用に準備するために、次のような追加のステップが必要になる場合があります。
- さらなるカリキュラム学習や継続的な事前学習によるモデルの微調整
- 教師ありファインチューニング(指示追従やチャットなど)
- 人間のフィードバックからの強化学習(RLHF)は、人間の好みに合わせてモデルを微調整するための高度な手法です。これは非常に強力ですが、適切に利用するには複雑であり、すべてのアプリケーションで必要となるわけではありません。多くのアプリケーションでは、教師ありファインチューニングやガードレールで十分です。
- モデルまたはアプリケーションに対するエンドユーザーの評価に基づいて、上記を繰り返し改善します
未来
GenAI開発のペースは落ちていません。GPU やその他の専用ハードウェアは、より高速かつ安価になります。ソフトウェアスタックが改善されます。新しいモデルアーキテクチャとトレーニング手法が、研究から実用へと移行します。どのような準備ができますか?
Databricks を使えば、多くの開発成果をdefaultで活用できます。Databricksのモデルトレーニング、モデルサービング、およびその他の機能は、今後も最新のトップモデルのサポートを追加していきます。新しいトレーニングと推論の技術が内部で統合されます。より大規模で複雑なワークロードについては、Databricks が完全なカスタマイズをサポートし、最も最先端のワークロードは Databricks AI Research チームと密接に連携して実行されます。
貴組織では、現在から将来にわたり、柔軟でカスタマイズ可能なワークロードのサポートに重点を置いてください:
- AIインフラストラクチャを構築する。AI ゲートウェイ経由でモデル API ガバナンスを設定します。AI セキュリティ フレームワークを使用して、セキュリティ プロセスを設定します。Unity CatalogでデータとAIガバナンスを標準化し、統合します。エージェント フレームワークを使用してインナーループを、モデル トレーニングを使用してアウターループを開発します。堅牢な Model Serving と モニタリング を含む、 MLOps プラクティス を開発します。
- AI の専門知識を深めましょう。Databricks チームと協力して、AI のためのセンターオブエクセレンス(CoE)を構築しましょう。Databricks Training を活用して、チームをそれぞれの役割に合わせた学習パスで導くことができます。
- 独自の知的財産を開発します。この IP には、カスタムモデルだけでなく、さらに重要なこととして、企業のデータも含まれます。現在のアプリケーションやユーザーから��データを収集し、来歴を追跡し、規制やライセンスに注意してください。このデータは、お客様のすべての GenAI カスタマイズ(内部ループでの RAG と、外部ループでのチューニングおよび事前学習の両方)を強化します。
関連リソース
コース
- Get Started With 生成AIセルフペースチュートリアルを受講して、Databricksの認定資格を取得しましょう
- 生成AIの基礎 (Databricks Academy)
- Databricksによる生成AIエンジニアリング (講師によるトレーニングと Databricks アカデミー)
- 新しいコースは、Databricks TrainingとDatabricks Academyでご確認ください。
読み取り中
- 生成 AI モデルとシステムの開発のさまざまな側面を深く掘り下げたブログ投稿集については、The Big Book of Generative AI をご覧ください。
- 企業データで拡張された LLM を使用して生成 AI アプリケーションを構築する方法を深く掘り下げるには、検索拡張生成(RAG)のコンパクト ガイドをご覧ください
- Databricks AI Research のブログ記事
- LLMOps を含む Databricks での MLOps の詳細については、The Big Book of MLOps: Second Edition をご覧ください。
- 製品の概要、機能の詳細、多くのリソースへのリンクについては、Databricks ページをご覧ください
- GenAI向けDatabricksドキュメント(AWS、Azure、GCP)
Data + AI Summit 2024 の講演
データブリックスについて
Databricks は、グローバルで唯一のデータ & AI 企業です。現在、ブロック、コムキャスト、コンデナスト、リヴィアン、シェルをはじめ、フォーチュン 500 企業の 60% 以上を含む世界中の 10,000 を超える企業が、Databricks データインテリジェンスプラットフォームを利用して、データの管理と AI の活用を実現しています。Databricksはサンフランシスコに本社を置き、世界中にオフィスを展開しており、レイクハウス、Apache SparkTM、Delta Lake、MLflowの元の作成者によって設立されました。LinkedIn、X、Facebook での情報発信も行っております。ぜひご覧ください。
パーソナライズされたデモについては、お問い合わせください:
databricks.com/contact
(このeBookはAI翻訳ツールを使用して翻訳されています) 原文はこちら
