Focus on data workloads, not infrastructure
Fully managed, versionless Spark for all your data and AI workloads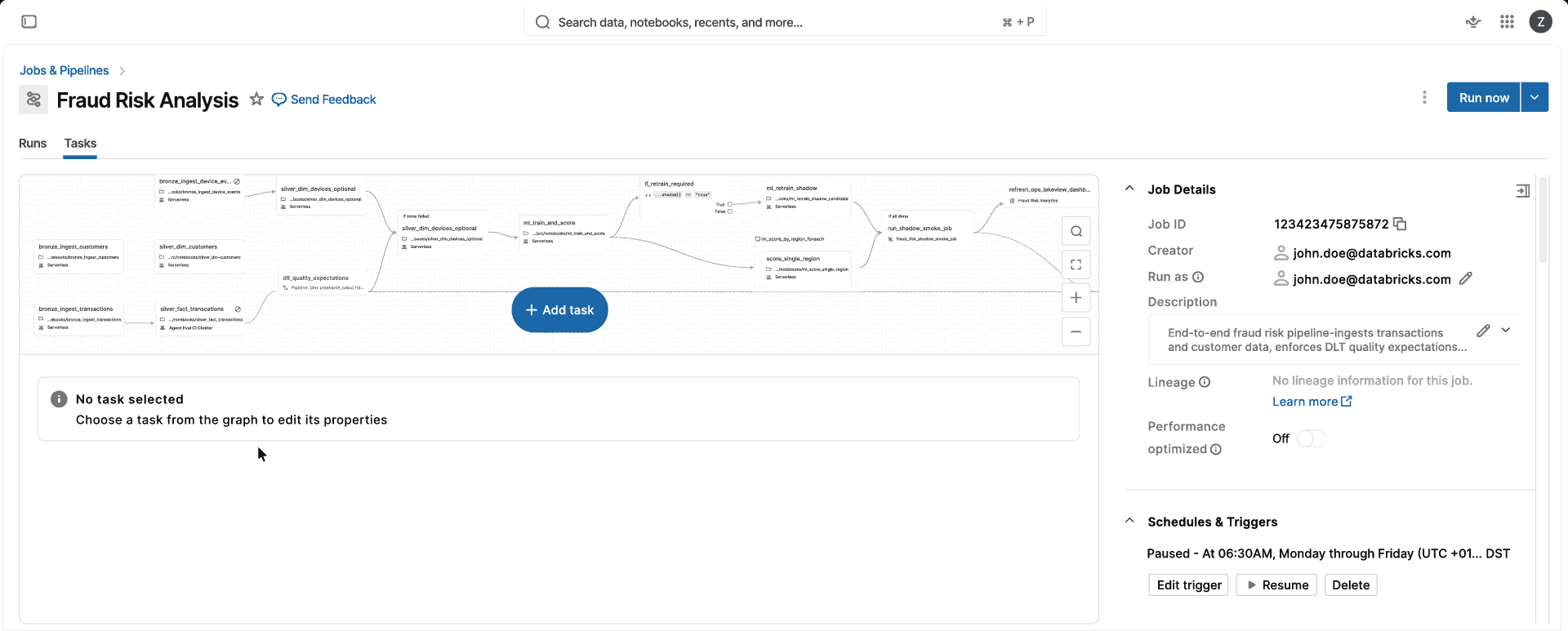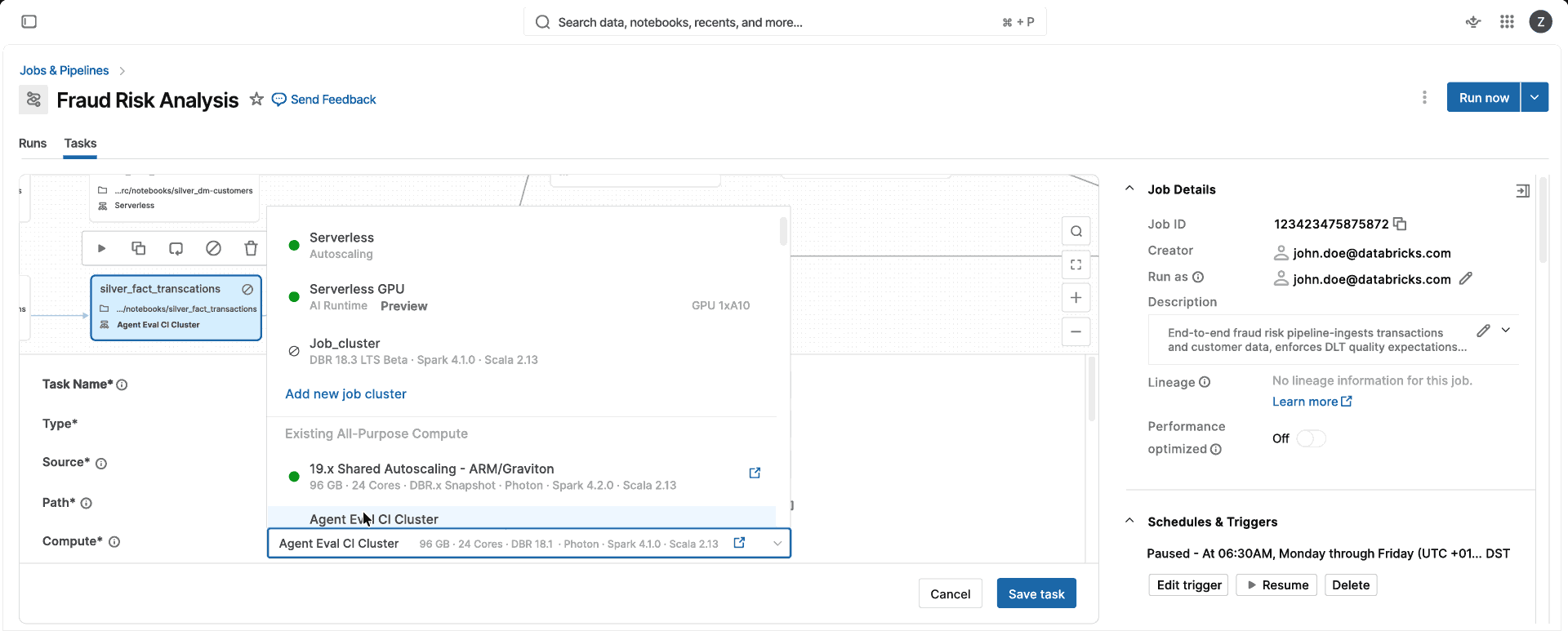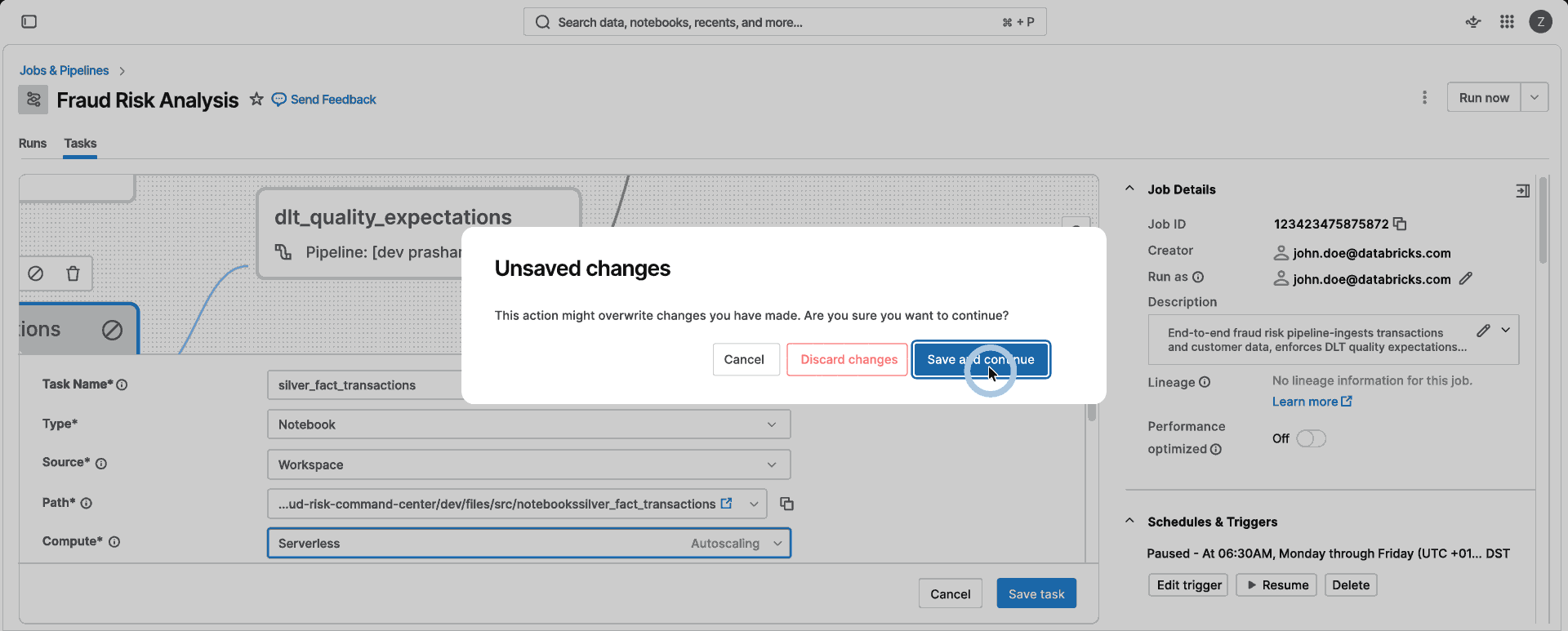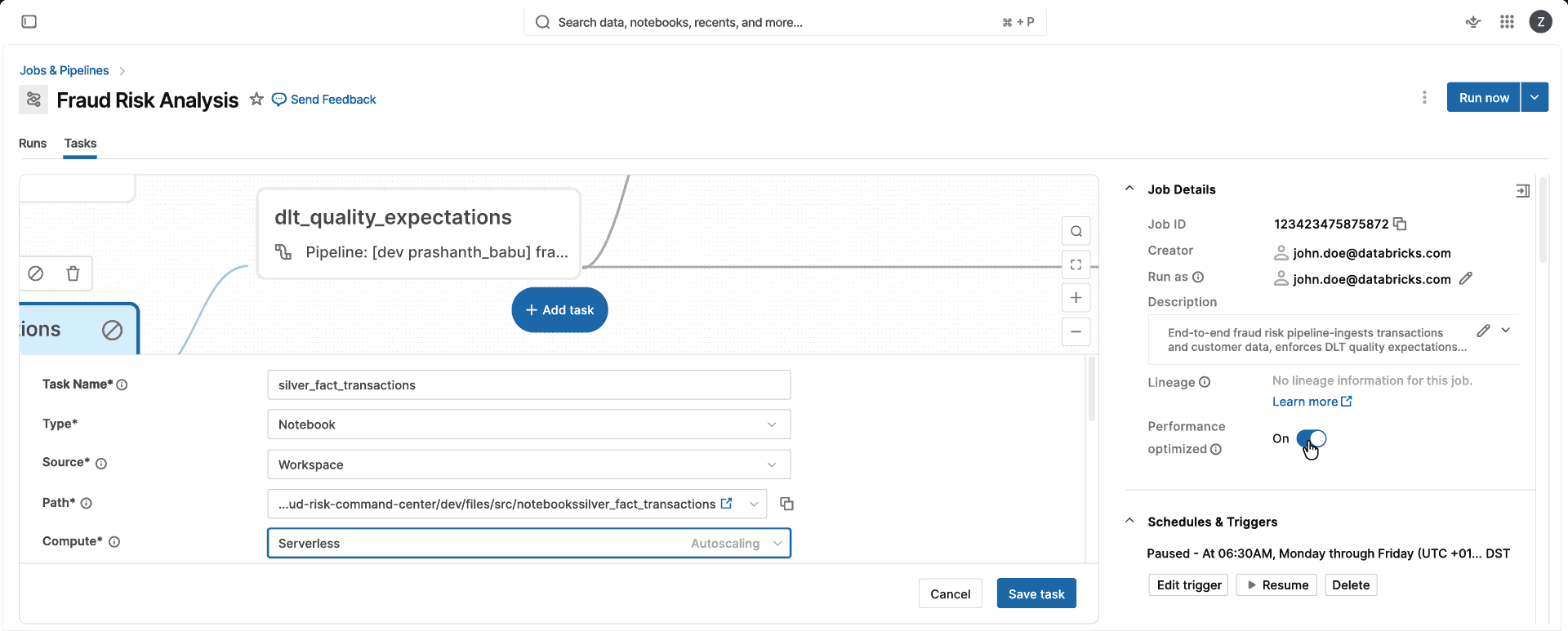
TOP COMPANIES USE SERVERLESS COMPUTE
Choose your business goal, not the infra
Run data and AI workloads on compute that automatically scales, upgrades, and optimizes without infrastructure management.Fully managed
One compute. No CPU-optimized vs memory-optimized vs instance-class decisions, no cluster configuration to manage. Choose Standard or Performance-Optimized mode, and Databricks automatically selects the right instance and compute types (single VM or Spark cluster) for you, so your team can ship data products rather than manage compute.
Performant
Serverless starts in seconds, not minutes, loads environments from cache, and automatically right-sizes to workload demand. Standard mode delivers cost-efficient batch processing, while Performance-Optimized mode typically runs latency-sensitive jobs 2x faster than classic clusters.
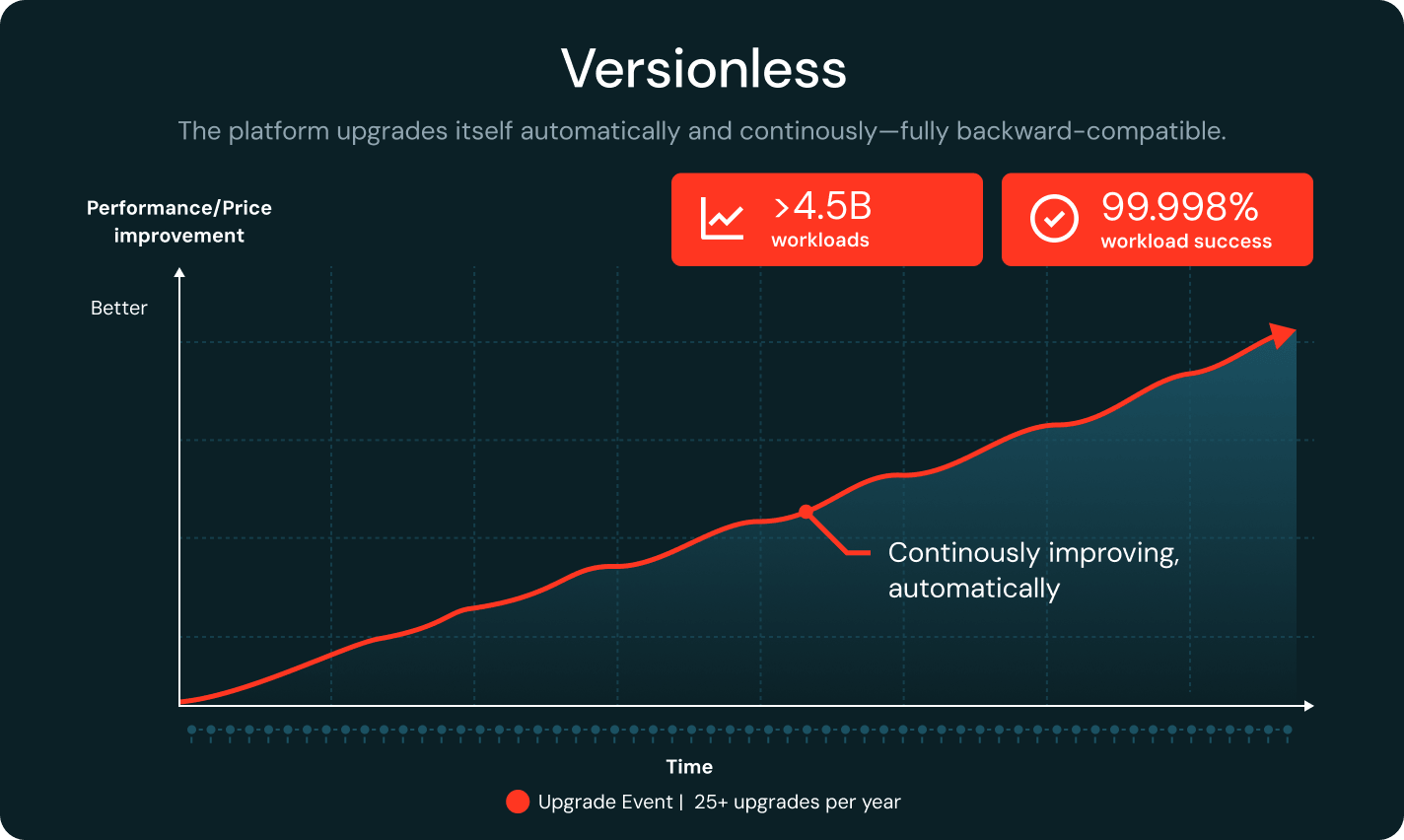
Versionless
Databricks continuously upgrades the runtime while staying fully backward-compatible. Regression detection pins workloads to stable versions automatically. With 25+ upgrades per year and 99.998% workload success, teams save up to 20% of engineering time.
Compute that just works
Stop managing infrastructure and start running your data and AI workloads on fully managed, autoscaling, versionless compute.Serverless upgrades continuously and automatically while staying fully backward-compatible, keeping workloads running without intervention.
Choose Standard mode for cost-optimized batch workloads or Performance-Optimized mode for latency-sensitive jobs, typically running jobs 2x faster than classic clusters.
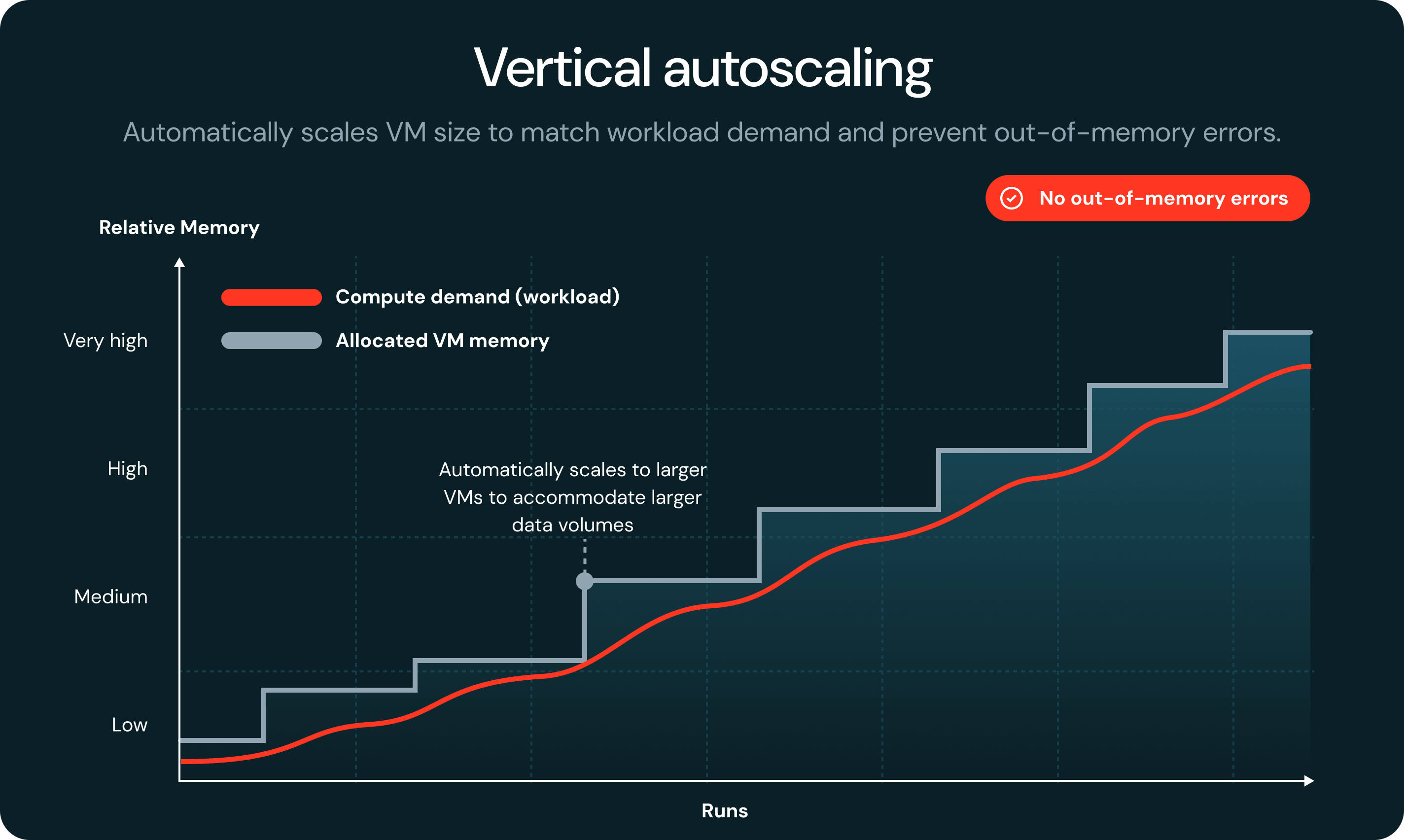
When a task runs out of memory, serverless automatically detects the failure and restarts it on a larger VM, with no job failures or manual intervention required.
Library environments are cached globally, so once a user in your org runs with a specific set of packages, the environment is ready in seconds for everyone else.
Serverless scales compute up or down in seconds, not minutes, automatically right-sizing to workload demand without cluster configuration.
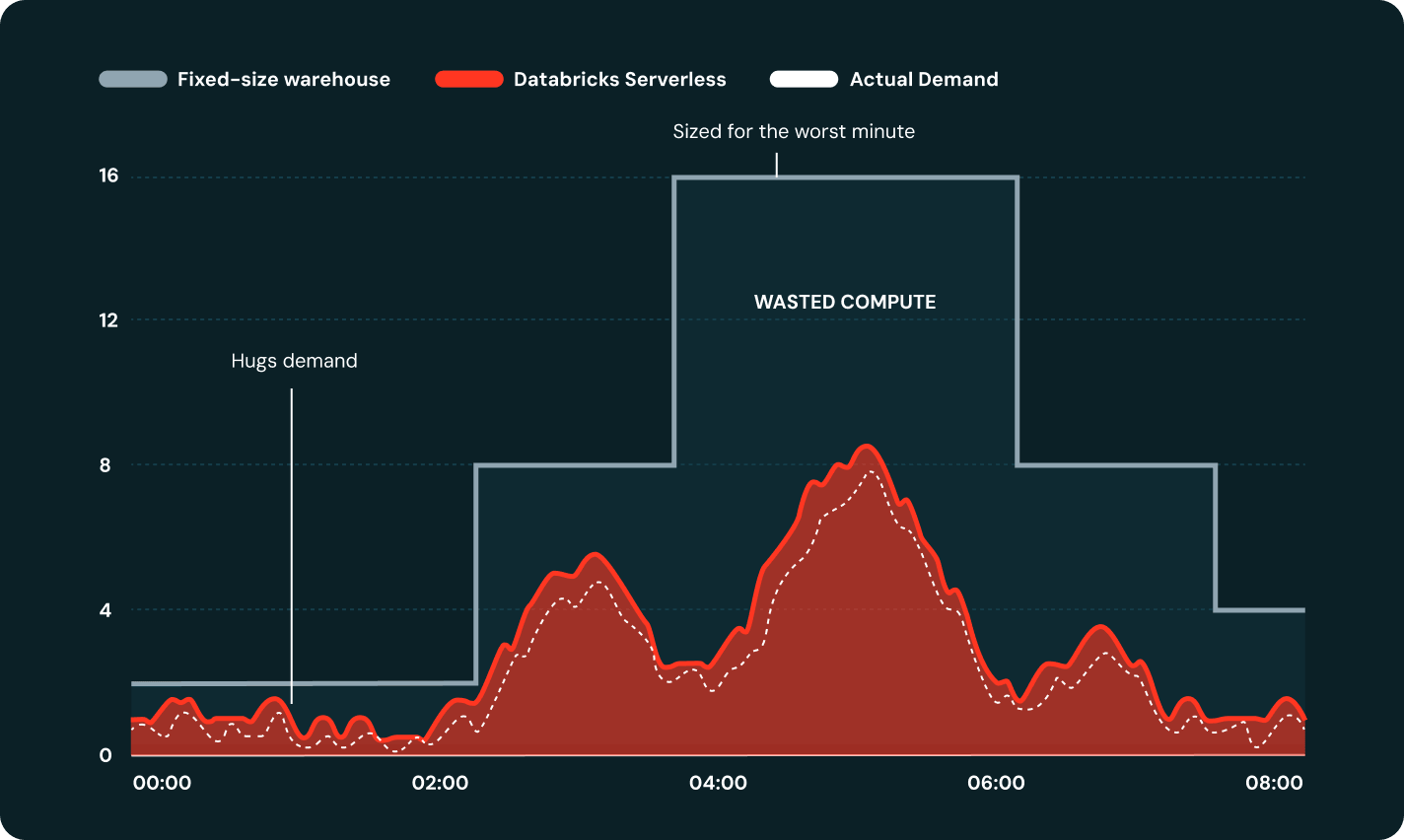
Serverless automatically retries failed tasks and reroutes around cloud-level failures, keeping pipelines on schedule without on-call intervention.
More features
Serverless for every workload

Query data without managing warehouse compute
Databricks serverless SQL warehouses start in seconds and scale automatically to match demand, so analysts always have compute ready. No sizing decisions, no idle clusters, and no infrastructure overhead. Just fast, reliable queries.




Usage-based pricing keeps spending in check
Only pay for the products you use at per second granularity.Discover more
Learn more about products powered by serverless compute
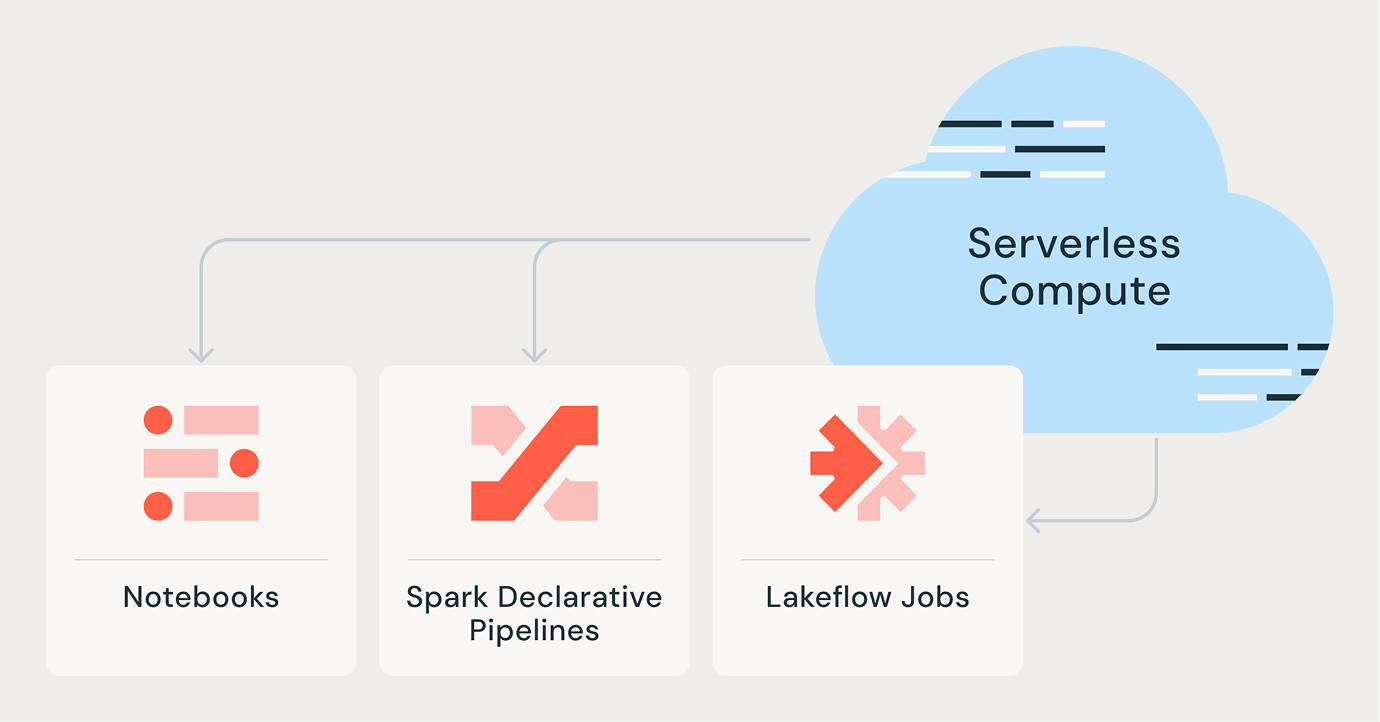
Lakeflow Jobs
Equip teams to better automate and orchestrate any ETL, analytics, and AI workflow with deep observability, high reliability, and broad task type support.

Databricks SQL
An intelligent, self-optimizing data warehouse built on lakehouse architecture, offering the best price/performance in the market.

Spark Declarative Pipelines
Simplify batch and streaming ETL with automated data quality, change data capture (CDC), data ingestion, transformation, and unified governance.

Notebooks
Boost team productivity with Databricks Collaborative Notebooks, enabling real-time collaboration and streamlined data science workflows.

Databricks Apps
Create applications using popular frameworks, serverless deployment and built-in governance. Deliver impactful solutions to users without complex infrastructure management.

Lakebase
Postgres integrated with the lakehouse, built for modern operational workloads.
Take the next step
Related content
Serverless compute FAQ
Ready to become a data + AI company?
Take the first steps in your data transformation