The Growing Apache Spark Community
This year has seen unprecedented growth in both the user and contributor communities around Apache Spark. This rapid growth validates the tremendous potential of the platform, and shows the great excitement around it.
While Spark started as a research project by a few grad students at UC Berkeley in 2009, today over 90 developers from 25 companies have contributed to Spark. This is not counting contributors to Shark (Hive on Spark), of which there are 25. Indeed, out of the many new big data engines created in the past few years, Spark has the largest development community after Hadoop MapReduce. We believe that new components in the project, like Spark Streaming and MLlib, will only increase this growth.
Growth by Numbers
To give a sense of the growth of the project, the graph below shows the number of contributors to each major Spark release in the past year.
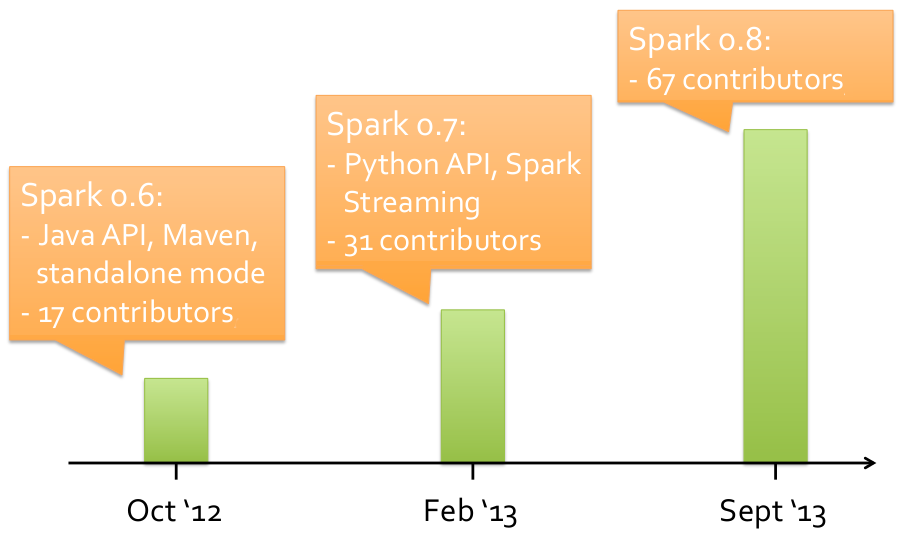
The number of contributors quadrupled between October 2012 and 2013, and each of our releases has been getting bigger in terms of features. In addition, an increasing number of Spark’s major features have been contributed by the user community. These include Hadoop YARN support in Apache Spark 0.8; metrics collection; new machine learning algorithms and examples; fair scheduling; and column-oriented compression in Shark. At Databricks, we plan to continue working with the open source community to expand Apache Spark.
A final indicator of growth is conferences and events. The AMP Camp training camp at Berkeley was sold out with members from over 100 companies attending, while our San Francisco user meetup has grown to 1,300 members. We’re excited to continue organizing such events.
Bringing the Community Together: The First Spark Summit
![]()
To celebrate the growth around Spark and bring users and contributors together, we’re excited to host the first Spark Summit, on December 2nd and 3rd, 2013. Sponsored by leading big data companies and production users of Spark, this will be the first conference around the Spark stack. In addition to talks from users and developers, the Summit and will include a day of hands-on Spark training. We’re looking forward to your continuous involvement to expand Spark and tackle tomorrow’s big data challenges. So whether you’re a big data veteran or new to Spark, come by to learn how to use it to solve your problems.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.