Sparkling Water = H20 + Apache Spark
H20 – The Killer-App on Apache Spark

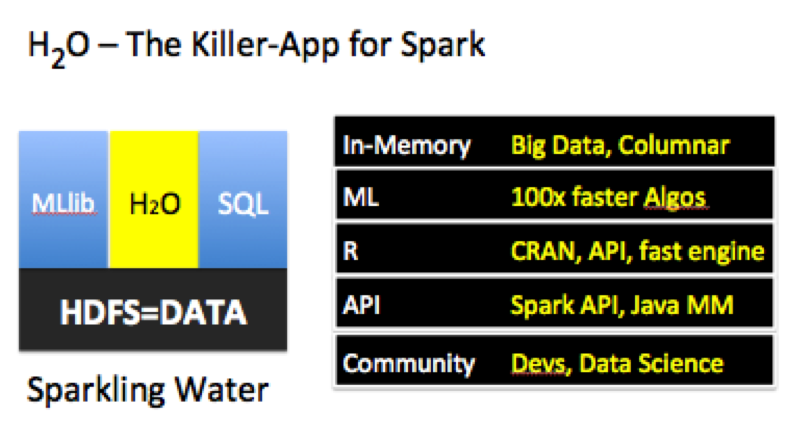
In-memory big data has come of age. The Apache Spark platform, with its elegant API, provides a unified platform for building data pipelines. H2O has focused on scalable machine learning as the API for big data applications. Spark + H2O combines the capabilities of H2O with the Spark platform – converging the aspirations of data science and developer communities. H2O is the Killer-Application for Spark.
Backdrop
Over the past few years, we watched Matei and the team behind Spark build a thriving open-source movement and a great development platform optimized for in-memory big data, Spark. At the same time, H2O built a great open source product with a growing customer base focused on scalable machine learning and interactive data science. These past couple of months the Spark and H2O teams started brainstorming on how to best combine H2O's Machine Learning capabilities with the power of the Spark platform. The result: Sparkling Water.
Sparkling Water
Users can in a single invocation and process, get the best of Spark - its elegant APIs, RDDs, multi-tenant Context and H2O's speed, columnar-compression and fully-featured Machine Learning and Deep-Learning algorithms.
One of the primary draws for Spark is its unified nature, enabling end-to-end building of API’s within a single system. This collaboration is designed to seamlessly enable H20’s advanced capabilities to be part of that data pipeline. The first step in this journey is enabling in-memory sharing through Tachyon and RDDs. The roadmap includes deeper integration where H2O’s columnar-compressed capabilities can be natively leveraged through ‘H2ORDD’.
Today, data gets parsed and exchanged between Spark and H2O via Tachyon. Users can interactively query big data both via SQL and ML from within the same context.
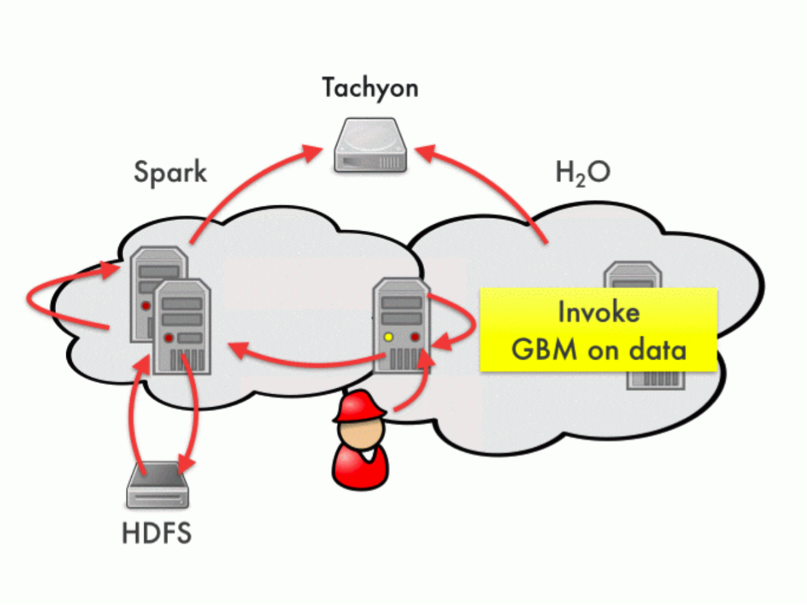
Sparkling Water enables use of H2O's Deep Learning and Advanced Algorithms for Spark's user community. H2O as the killer-application provides a robust machine learning engine and API for the Spark Platform. This will further empower application developers on Spark to build intelligent and smarter applications.
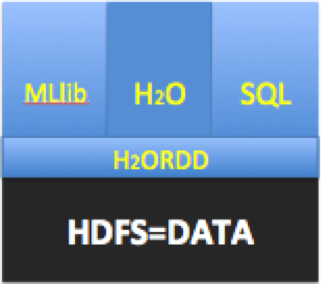
MLlib and H2O: The Triumph of Open Source!
MLlib is a library of efficient implementations of popular algorithms directly built using Spark. We believe that enterprise customers should have the choice to select the best tool for meeting their needs in the context of Spark. Over time, H2O will accelerate the community’s efforts towards production ready scalable machine learning. Fast fully featured algorithms in H2O will add to growing open source efforts in R, MLlib, Mahout and others, disrupting closed and proprietary vendors in machine-learning and predictive analytics.
Natural integration of H2O with the rest of Spark's capabilities is a definitive win for enterprise customers.
More info
- Slides of the first Sparkling Water meetup
- Sparkling Water code is here
- Install and Test Instructions
Demo Code
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.