Scalable Decision Trees in MLlib
by Manish Amde and Joseph Bradley
Decision trees and their ensembles are industry workhorses for the machine learning tasks of classification and regression. Decision trees are easy to interpret, handle categorical and continuous features, extend to multi-class classification, do not require feature scaling and are able to capture non-linearities and feature interactions.
Due to their popularity, almost every machine learning library provides an implementation of the decision tree algorithm. However, most are designed for single-machine computation and seldom scale elegantly to a distributed setting. Apache Spark is an ideal platform for a scalable distributed decision tree implementation since Spark's in-memory computing allows us to efficiently perform multiple passes over the training dataset.
About a year ago, open-source developers joined forces to come up with a fast distributed decision tree implementation that has been a part of the Spark MLlib library since release 1.0. The Spark community has actively improved the decision tree code since then. This blog post describes the implementation, highlighting some of the important optimizations and presenting test results demonstrating scalability.
New in Spark 1.1: MLlib decision trees now support multiclass classification and include several performance optimizations. There are now APIs for Python, in addition to Scala and Java.
Algorithm Background
At a high level, a decision tree model can be thought of as hierarchical if-else statements that test feature values in order to predict a label. An example model for a binary classification task is shown below. It is based upon car mileage data from the 1970s! It predicts the mileage of the vehicle (high/low) based upon the weight (heavy/light) and the horsepower.
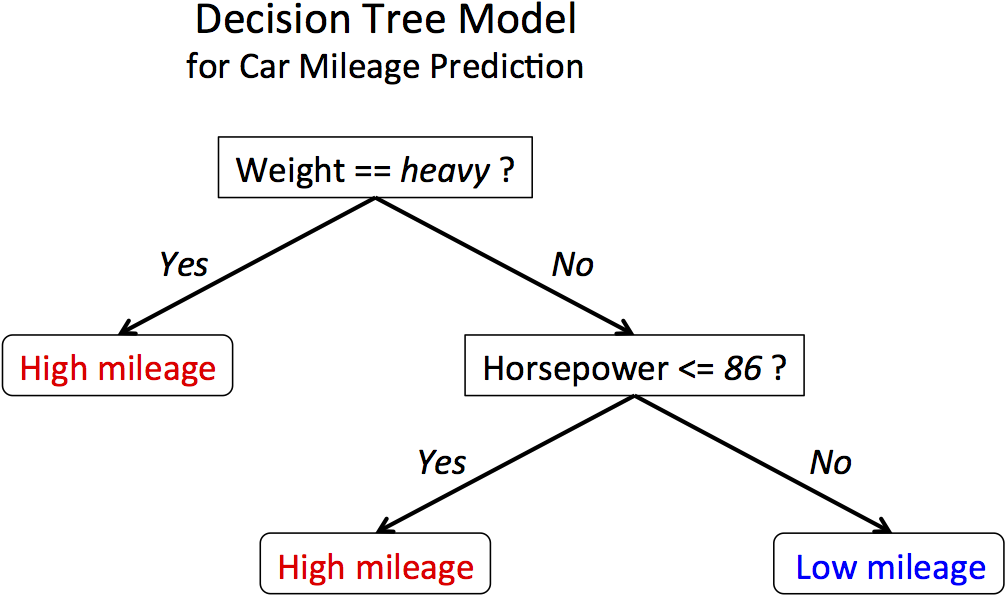
A model is learned from a training dataset by building a tree top-down. The if-else statements, also known as splitting criteria, are chosen to maximize a notion of information gain --- it reduces the variability of the labels in the underlying (two) child nodes compared the parent node. The learned decision tree model can later be used to predict the labels for new instances.
These models are interpretable, and they often work well in practice. Trees may also be combined to build even more powerful models, using ensemble tree algorithms. Ensembles of trees such as random forests and boosted trees are often top performers in industry for both classification and regression tasks.
Simple API
The example below shows how a decision tree in MLlib can be easily trained using a few lines of code using the new Python API in Spark 1.1. It reads a dataset, trains a decision tree model and then measures the training error of the model. Java and Scala examples can be found in the Spark documentation on DecisionTree.
Optimized Implementation
Spark is an ideal compute platform for a scalable distributed decision tree implementation due to its sophisticated DAG execution engine and in-memory caching for iterative computation. We mention a few key optimizations.
Level-wise training: We select the splits for all nodes at the same level of the tree simultaneously. This level-wise optimization reduces the number of passes over the dataset exponentially: we make one pass for each level, rather than one pass for each node in the tree. It leads to significant savings in I/O, computation and communication.
Approximate quantiles: Single machine implementations typically use sorted unique feature values for continuous features as split candidates for the best split calculation. However, finding sorted unique values is an expensive operation over a distributed dataset. The MLlib decision tree uses quantiles for each feature as split candidates. It's a standard tradeoff for improving decision tree performance without significant loss of accuracy.
Avoiding the map operation: The early prototype implementations of the decision tree used both map and reduce operations when selecting best splits for tree nodes. The current code uses significantly less computation and communication by exploiting the known structure of the pre-computed split candidates to avoid the map step.
Bin-wise computation: The best split computation discretizes features into bins, and those bins are used for computing sufficient statistics for splitting. We precompute the binned representations of each instance, saving computation on each iteration.
Scalability
We demonstrate the scalability of MLlib decision trees with empirical results on various datasets and cluster sizes.
Scaling with dataset size
The two figures below show the training times of decision trees as we scale the number of instances and features in the dataset. The training times increased linearly, highlighting the scalability of the implementation.
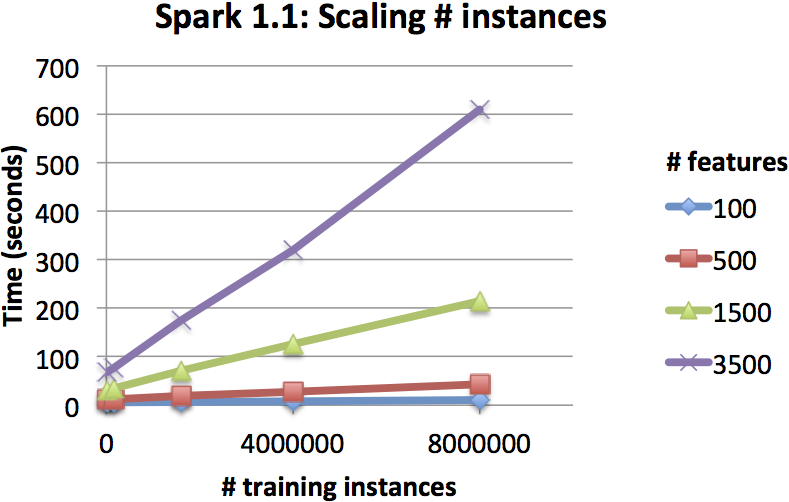
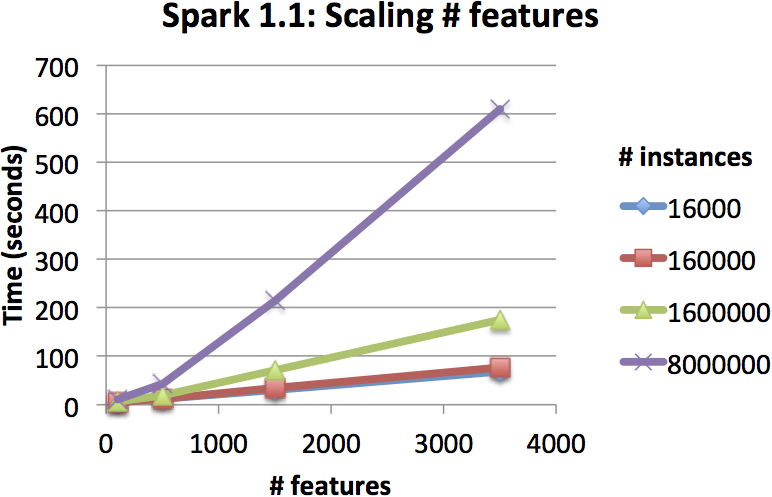
These tests were run on an EC2 cluster with a master node and 15 worker nodes, using r3.2xlarge instances (8 virtual CPUs, 61 GB memory). The trees were built out to 6 levels, and the datasets were generated by the spark-perf library.
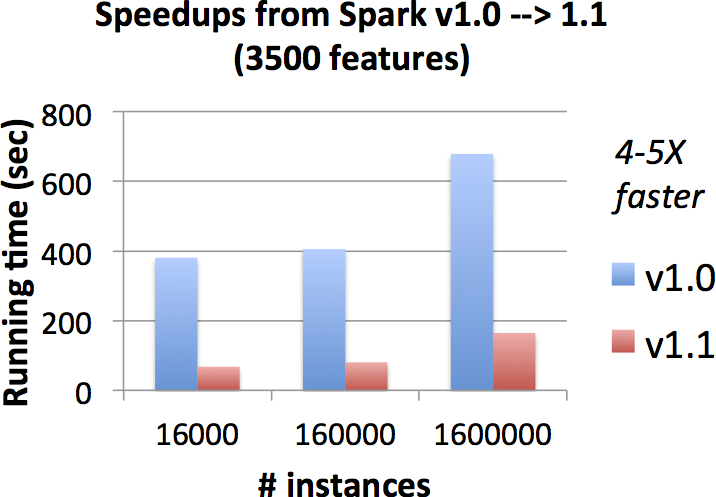
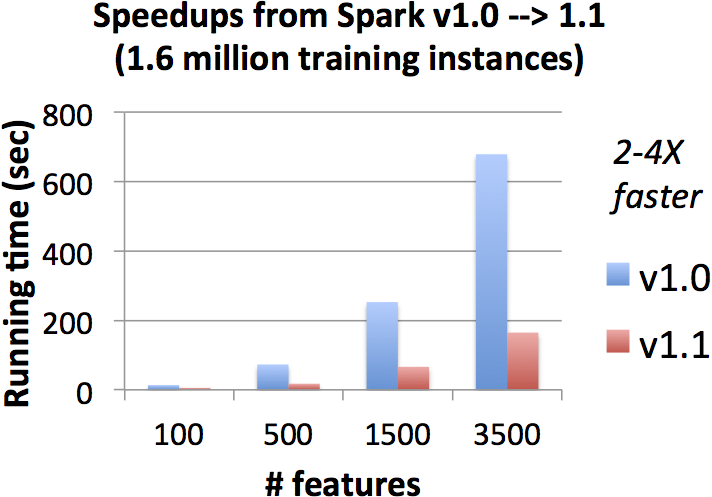
Spark 1.1 speedups
The next two figures show improvements in Apache Spark 1.1, relative to the original Apache Spark 1.0 implementation. On the same datasets and cluster, the new implementation is 4-5X faster on many datasets!
What’s Next?
The tree-based algorithm development beyond release 1.1 will focus primarily on ensemble algorithms such as random forests and boosting. We will also keep optimizing the decision tree code for performance and plan to add support for more options in the upcoming releases.
To get started using decision trees yourself, download Spark 1.1 today!
Further Reading
- See examples and the API in the MLlib decision tree documentation.
- Watch the decision tree presentation from the 2014 Spark Summit.
- Check out video and slides from another talk on decision trees at a Sept. 2014 SF Scala/Bay Area Machine Learning meetup.
Acknowledgements
The Spark MLlib decision tree work was initially performed jointly with Hirakendu Das (Yahoo Labs), Evan Sparks (UC Berkeley AMPLab), and Ameet Talwalkar and Xiangrui Meng (Databricks). More contributors have joined since then, and we welcome your input too!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.