Efficient Similarity Algorithm Now in Apache Spark, Thanks to Twitter
by Reza Zadeh
Introduction
We are often interested in finding users, hashtags and ads that are very similar to one another, so they may be recommended and shown to users and advertisers. To do this, we must consider many pairs of items, and evaluate how “similar” they are to one another.
We call this the “all-pairs similarity” problem, sometimes known as a “similarity join.” We have developed a new efficient algorithm to solve the similarity join called “Dimension Independent Matrix Square using MapReduce,” or DIMSUM for short, which made one of Twitter’s most expensive batch computations 40% more efficient.
To describe the problem we’re trying to solve more formally, when given a dataset of sparse vector data, the all-pairs similarity problem is to find all similar vector pairs according to a similarity function such as cosine similarity, and a given similarity score threshold.
Not all pairs of items are similar to one another, and yet a naive algorithm will spend computational effort to consider even those pairs of items that are not very similar. The brute force approach of considering all pairs of items quickly breaks, since its computational effort scales quadratically.
For example, for a million vectors, it is not feasible to check all roughly trillion pairs to see if they’re above the similarity threshold. Having said that, there exist clever sampling techniques to focus the computational effort on only those pairs that are above the similarity threshold, thereby making the problem feasible. We’ve developed the DIMSUM sampling scheme to focus the computational effort on only those pairs that are highly similar, thus making the problem feasible.
Intuition
The main insight that allows gains in efficiency is sampling columns that have many non-zeros with lower probability. On the flip side, columns that have fewer non-zeros are sampled with higher probability. This sampling scheme can be shown to provably accurately estimate cosine similarities, because those columns that have many non-zeros have more trials to be included in the sample, and thus can be sampled with lower probability.
There is an in-depth description of the algorithm on the Twitter Engineering blog post.
Experiments
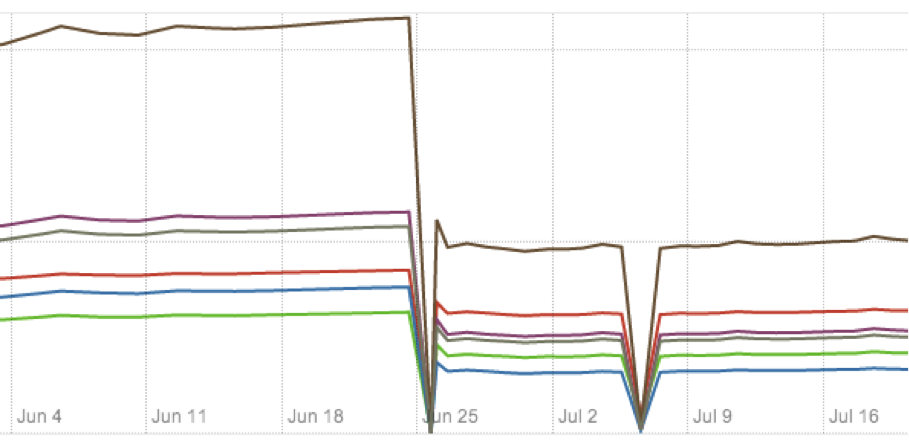
We run DIMSUM on a production-scale ads dataset. Upon replacing the traditional cosine similarity computation in late June, we observed 40% improvement in several performance measures, plotted below.

Usage from Spark
The algorithm is available in Apache Spark MLlib as a method in RowMatrix. This makes it easy to use and access:
// Arguments for input and threshold
val filename = args(0)
val threshold = args(1).toDouble
// Load and parse the data file.
val rows = sc.textFile(filename).map { line =>
val values = line.split(' ').map(_.toDouble)
Vectors.dense(values)
}
val mat = new RowMatrix(rows)
// Compute similar columns perfectly, with brute force.
val simsPerfect = mat.columnSimilarities()
// Compute similar columns with estimation using DIMSUM
val simsEstimate = mat.columnSimilarities(threshold)
Here is an example invocation of DIMSUM. This functionality will be available as of Spark 1.2.
Additional information can be found in the GigaOM article covering the DIMSUM algorithm.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.