Extending MemSQL Analytics with Apache Spark
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
This is a guest blog from our one of our partners: MemSQL
Summary
Coupling operational data with the most advanced analytics puts data-driven business ahead. The MemSQL Apache Spark Connector enables such configurations.
Meeting Transactional and Analytical Needs
Transactional databases form the core of modern business operations. Whether that transaction is financial, physical in terms of inventory changes, or experiential in terms of a customer engagement, the transaction itself moves our business forward.
But while transactions represent the state of our business, analytics tell us patterns of the past, and help us predict patterns of the future. Analytics can tell us what levers influence profitability and put us ahead of the pack.
Success in digital business requires both transactional and analytical prowess, including the foremost means to analyze data.
Speed and Agility with MemSQL and Apache Spark
As a real-time database for transactions and analytics, MemSQL helps companies simultaneously ingest and query data with a focus on SQL operations. SQL is the lingua franca of business database operations and provides rich capabilities for complex queries, but there are some thing even SQL cannot accomplish.
In the cases where analysts and data scientists want the ability to manipulate and explore data in new ways, Apache Spark has emerged as the premier data processing framework that is fast, programmatic, and scalable. So that MemSQL users can take advantage of this functionality in Spark, MemSQL recently introduced the MemSQL Spark Connector.
MemSQL Spark Connector Architecture
The MemSQL Spark Connector combines the memory-optimized and distributed architectures of both MemSQL and Spark to drive a high-throughput, highly parallelized, bi-directional link between two clusters.
Two primary components of the MemSQL Spark Connector enable Spark to query from and write to MemSQL.
- A MemSQLRDD class for loading data from a MemSQL query
- A saveToMemsql function for persisting results to a MemSQL table
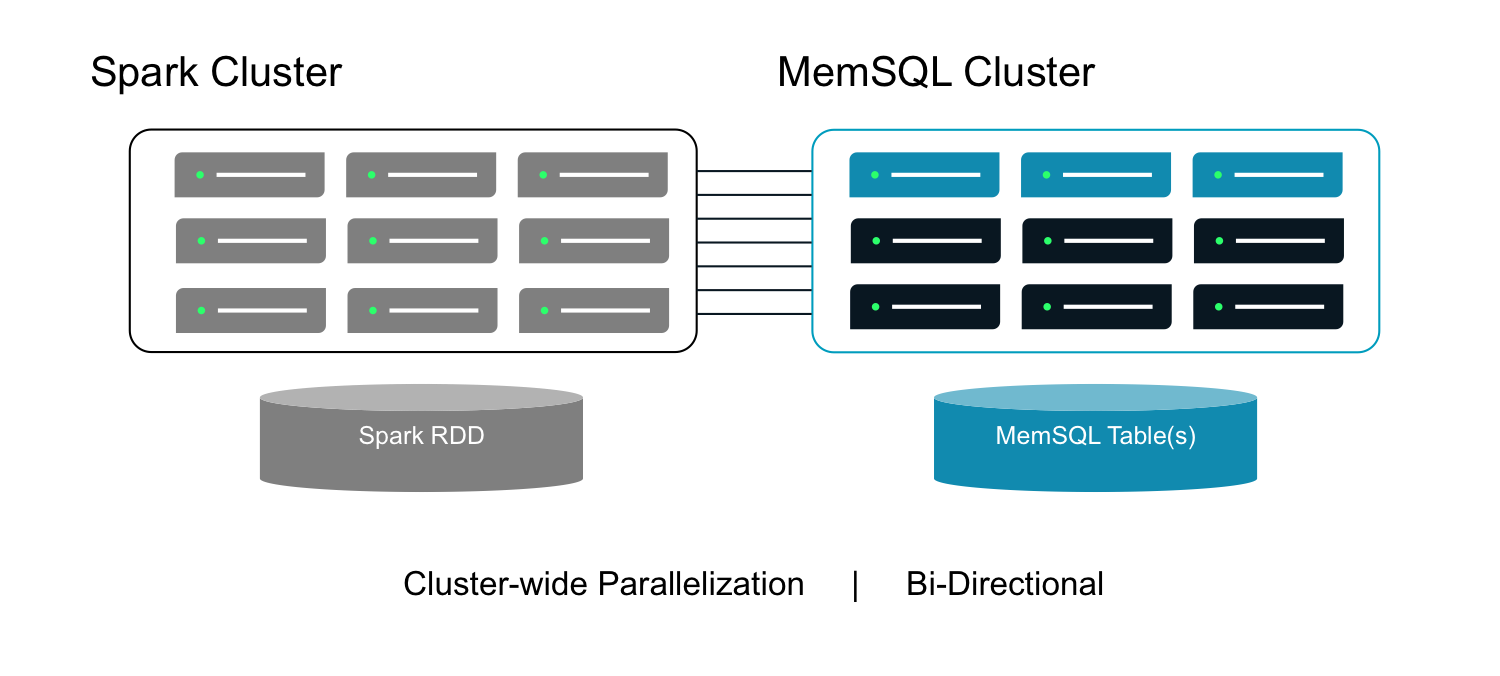
Figure 1: MemSQL Spark Connector Architecture
Bringing Data to the Light of Day
The MemSQL Spark Connector takes the most current operational data and makes it accessible from Spark, expanding the analytics capabilities of MemSQL with the full range of Spark tools and libraries.
MemSQL users can employ Spark’s rich analytical functionality through the following steps.
- Set up a replicated cluster providing clear demarcation between operations and analytics teams
- Give Spark access to live production data for the most recent and relevant results
- Allow Spark to write results set back to the primary MemSQL cluster to put new analyses into production
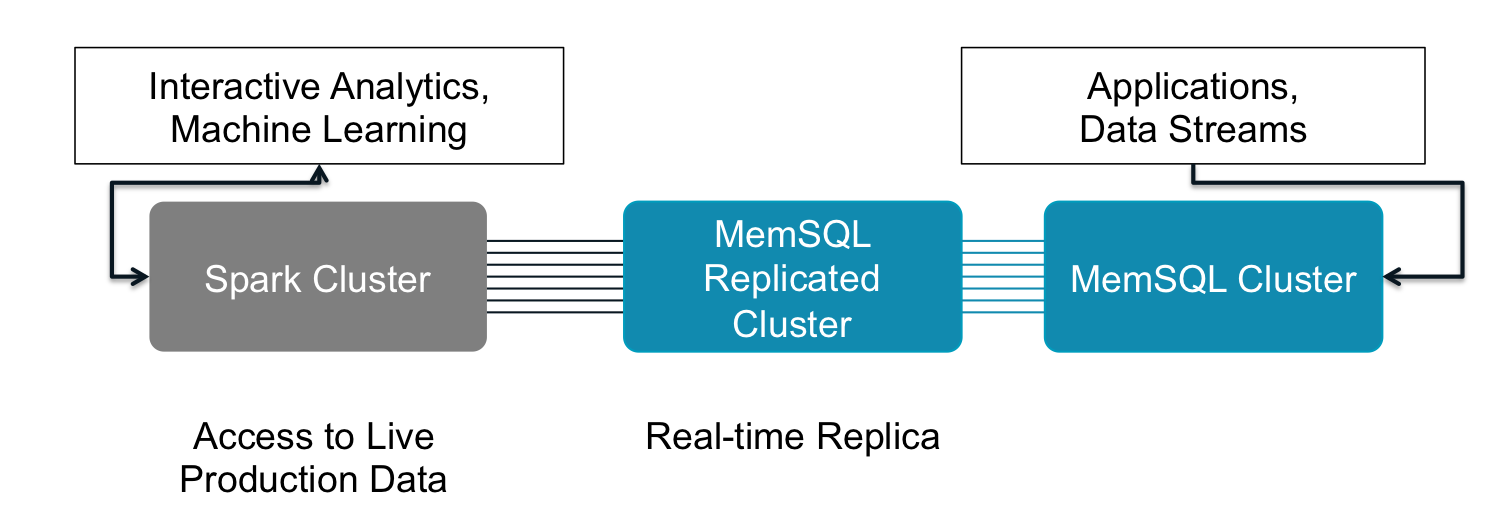
Figure 2: Extend MemSQL Analytics
Twin Power of Memory Optimized Clusters
With both clusters operating at lightening fast memory optimized speeds and able to parallel process data transfers between Spark RDDs and MemSQL tables, the combination delivers top performance.
Given the native integration with Spark, data transfer is convenient as an advanced SQL query can be leveraged to push down computation to MemSQL and only transfer the data needed.
For more information on the MemSQL Spark Connector please visit:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.