Databricks Launches "Jobs" Feature for Production Workloads
by Ali Ghodsi
Databricks now includes a new feature called Jobs, enabling support for running production pipelines, consisting of standalone Spark applications. Jobs includes a scheduler that enables data scientists and engineers to specify a periodic schedule for their production jobs, which will be executed according to the specified schedule.
Notebooks as Jobs
In addition to supporting running standalone Apache Spark applications, the Jobs feature provides a unique capability that allows running Databricks notebooks as jobs. That is, a job can be specified to use an existing Notebook, which will then be executed according to the specified schedule. This enables seamless transition between interactive exploration and production. Thus, data scientists can use notebooks as they did before, to perform their interactive data explorations. Once the notebook is sufficiently developed, it can then be transitioned to production use as a Job, without requiring any time consuming code rewrites. The output of every run of a job, including graphical output, is also stored as a notebook, which can be opened and used as any other notebook, allowing interactive debugging or further post-hoc exploration. This way, data scientists can repeatedly iterate and improve their jobs without having to spend time rewriting and moving code between different systems.
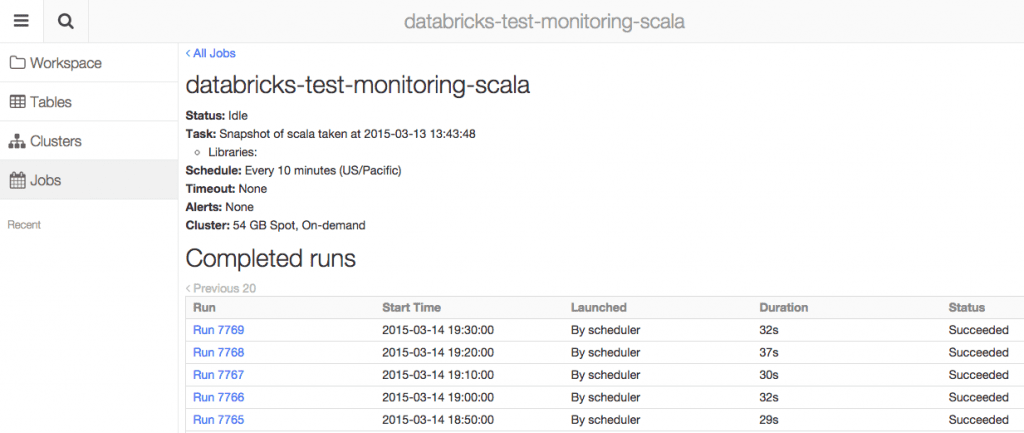
Notebooks as Workflows
In addition to running notebooks as jobs, users can run compiled applications and libraries as jobs. We have found users to often use a notebook to specify a workflow that calls other standalone jobs. Such workflows can conveniently be scripted in a language such as Python, using simple if-statements and exception-handling. Using notebooks in this way to specify production workflows is very powerful, as virtually any pattern can be expressed using a notebook.
Flexible Cluster Support
Jobs integrate with Databricks’ existing clusters. A job can be specified to use an existing Databricks cluster. Furthermore, a job can be specified to have its own dedicated cluster that is launched and torn down on every run. This will ensure that the job gets its own dedicated cluster, isolating it from errors caused by other users and jobs. Clusters can be launched on AWS on-demand instances, as well as the much cheaper spot instances. Furthermore, there is support for a hybrid mode called, fallback-on-demand, which tries to launch most of the cluster machines on spot instances, but will fallback on on-demand instances if the supply of spot instances is limited. This way, organizations can be sure to get the clusters they request, while cutting costs when possible, by using spot instances.
Notification Support
The job feature comes with a notification system, which can be configured to send an email to a set of users whenever a production job completes or fails. This is particularly important as jobs run with no human-in-the-loop, requiring attention whenever something goes wrong.
The launch of the jobs feature is aimed at further improving the end-to-end user experience of Databricks. Notebooks can now be used in production workloads, in addition to being useful as Libraries (notebooks can call other notebooks), Dashboards, and online collaboration. Although this is the first official release of the Jobs feature, we have several customers already using it in production environments as part of our early adopter program.
We would love to hear your feedback - please let us know what you think about this new feature!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.