Apache Spark Turns Five Years Old!
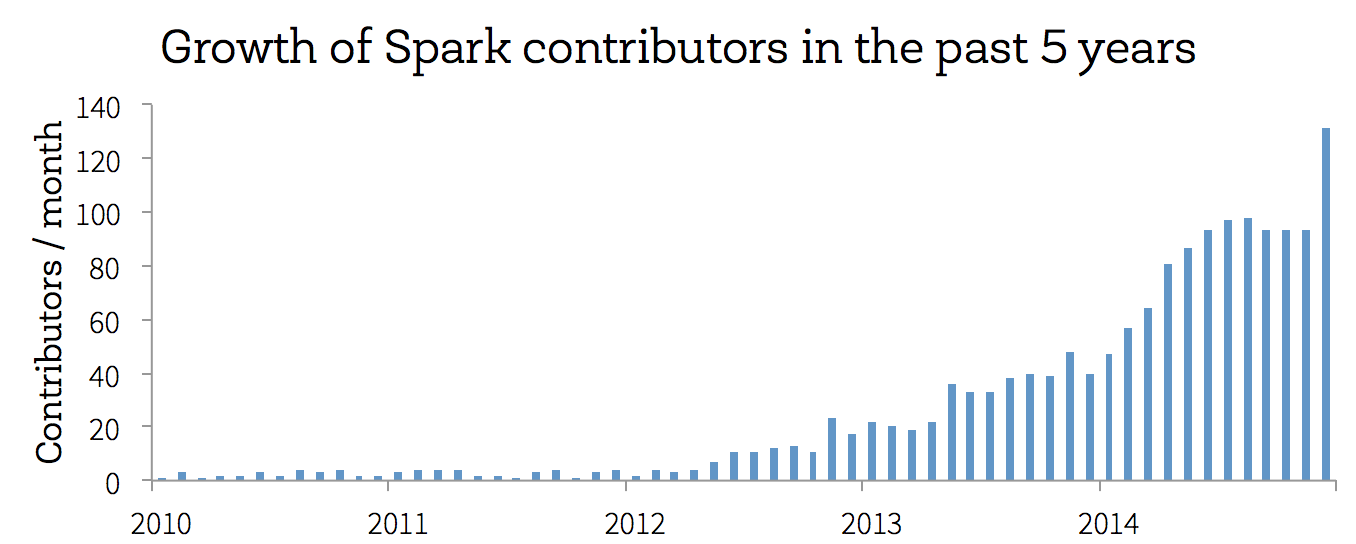
Today, we’re celebrating an important milestone for the Apache Spark project -- it’s now been five years since Spark was first open sourced. When we first decided to release our research code at UC Berkeley, none of us knew how far Spark would make it, but we believed we had built some really neat technology that we wanted to share with the world. In the five years since, we’ve been simply awed by the numerous contributors and users that have made Spark the leading-edge computing framework it is today. Indeed, to our knowledge, Spark has now become the most active open source project in big data (looking at either contributors per month or commits per month). In addition to contributors, it has built up an array of hundreds of production use cases from batch analytics to stream processing.
To celebrate Spark’s fifth birthday, one thing I wanted to do was to highlight some of the key ideas behind how we built out the project that still apply today. To do this, I took another look at the first public version of Spark.
The first thing to notice is that this version was quite small: it weighed in at 3900 lines of code, of which 1300 were the Scala interpreter, 600 were examples and 300 were tests. Since March 2010, I’m happy to say that our test coverage has gone up substantially. However, the observation about size does reflect something important: since the beginning, we’ve sought to keep the Spark engine small and compact, making it easier for many developers to understand and for us to change and improve. Even today, the core Spark engine is only about 50,000 lines of code. The main additions since that first version have been support for “shuffle” operations, which required new networking code and a DAG scheduler, as well as support for multiple backend schedulers, such as YARN. Nonetheless, even today we can regularly make large changes to the core engine that improve the performance or stability of all Spark applications. For example, during our work last year on large-scale sorting, multiple developers at Databricks ended up rewriting almost all of Spark’s networking layer.
The second thing to notice about Spark from 2010 is what it can do: even this ~2000 line engine could handle two of the most important workloads for Spark today, iterative algorithms and interactive queries. Back in 2010, we were the only cluster computing engine to support interactive use, by modifying the Scala interpreter to submit code to a Spark cluster. We’ve constantly sought to improve this experience and enable truly interactive data science through features like Spark’s Python API and DataFrames. In addition, even the 2010 version of Spark was able to run iterative algorithms like logistic regression 20-30x faster than MapReduce (subsequent improvements brought this up to 100x).
A final important element in how we think about the project is our focus on simple, stable APIs. The code examples that ship with Spark from 2010, like logistic regression and computing pi, are nearly identical to Spark code from today (see logistic regression, pi). We work very hard to define stable APIs that developers can build on years into the future, minimizing the work they must do to keep up with improvements in Spark. Starting in Apache Spark 1.0, these compatibility guarantees are now formalized for all major Spark components.
That’s enough about Spark in 2010. How has the project grown since then? While there has been tremendous activity in all areas of Spark, including support for more programming languages (Java, Python and soon R), data sources, and optimizations, the single biggest addition to Spark has been its standard libraries. Over the years, Spark has acquired four high-level libraries -- Spark Streaming, MLlib, GraphX and Spark SQL -- that all run on top of the core engine, and interoperate easily and efficiently with each other. Today these libraries are the bulk of the code in Spark -- about 200,000 lines compared to 50,000 in the core engine. They also represent the single largest standard library available for big data, making it easy to write applications that span all stages of the data lifecycle. Nevertheless, these libraries are still quite new, the majority of them having been added in the last two years. In future years I expect these libraries to grow significantly, with the aim to build as rich a toolset for big data as the libraries available for small data. You can find some of the areas where Databricks is working on these libraries in my slides from Spark Summit 2015.
Finally, like any five-year-old, Spark is still sometimes able to get into trouble without supervision and sometimes hard to understand. At Databricks, we’re working hard to make Spark easier to use and run than ever, through our efforts on both the Spark codebase and support materials around it. All of our work on Spark is open source and goes directly to Apache. In addition, we have put up a large array of free online training materials, as well as training courses and books. Finally, we have built a service to make it very easy to run Spark in a few clicks, Databricks Cloud. We hope that you enjoy using Spark, no matter which environment you run it in, as much as we enjoy building it.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.