Large Scale Topic Modeling: Improvements to LDA on Apache Spark
by Feynman Liang, Yuhao Yang and Joseph Bradley
This blog was written by Feynman Liang and Joseph Bradley from Databricks, and Yuhao Yang from Intel.
To get started using LDA, download Apache Spark 1.5 or sign up for a 14-day free trial of Databricks today.
What are people discussing on Twitter? To catch up on distributed computing, what news articles should I read? These are questions that can be answered by topic models, a technique for analyzing the topics present in collections of documents. This blog post discusses improvements in Apache Spark 1.4 and 1.5 for topic modeling using the powerful Latent Dirichlet Allocation (LDA) algorithm.
Spark 1.4 and 1.5 introduced an online algorithm for running LDA incrementally, support for more queries on trained LDA models, and performance metrics such as likelihood and perplexity. We give an example here of training a topic model over a dataset of 4.5 million Wikipedia articles.
Topic models and LDA
Topic models take a collection of documents and automatically infer the topics being discussed. For example, when we run Spark’s LDA on a dataset of 4.5 million Wikipedia articles, we can obtain topics like those in the table below.
 Table 1: Example LDA topics learned from Wikipedia articles dataset
Table 1: Example LDA topics learned from Wikipedia articles dataset
In addition, LDA tells us which topics each document is about; document X might be 30% about Topic 1 (“politics”) and 70% about Topic 5 (“airlines”). Latent Dirichlet Allocation (LDA) has been one of the most successful topic models in practice. See our previous blog post on LDA to learn more.
A new online variational learning algorithm
Online variational inference is a technique for learning an LDA model by processing the data incrementally in small batches. By processing in small batches, we are able to easily scale to very large datasets. MLlib implements an algorithm for performing online variational inference originally described by Hoffman et al.
Performance comparison
The table of topics shown previously were learned using the newly developed online variational learning algorithm. If we compare timing results, we can see a significant speedup in using the new online algorithm over the old EM algorithm:
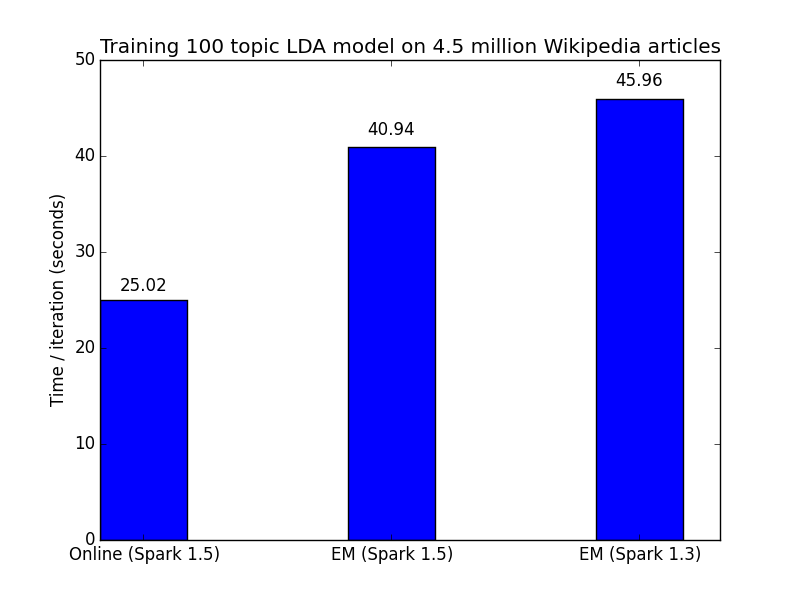 Figure 1: Online learning algorithm learns faster than earlier EM algorithm
Figure 1: Online learning algorithm learns faster than earlier EM algorithm
Experiment details
We first preprocessed the data by filtering common English stop words and limiting the vocabulary to the 10,000 most common words. We then trained a 100 topic LDA model for 100 iterations using the online LDA optimizer. We ran our experiments using Databricks on a 16 node AWS r3.2xlarge cluster with data stored in S3. For the actual code, see this Github gist.
Improved predictions, metrics, and queries
Predict topics on new documents
In addition to describing topics present in the training set, Spark 1.5 makes the trained LDA models more useful by allowing users to predict topics for a new test document.
Evaluate your model with likelihood and perplexity
After learning an LDA model, we are often interested in how well the model fits the data. We have added two new metrics to evaluate this: likelihood and perplexity.
Make more queries
This new release also adds several new queries users can perform on a trained LDA model. For example, we can now obtain the top k topics for each document (“What is this document discussing?”) as well as the top documents per topic (“To learn about topic X, what documents should I read?”).
Tips for running LDA
- Make sure to run for enough iterations. Early iterations may return useless (e.g. extremely similar) topics, but running for more iterations dramatically improves the results. We have noticed this is especially true for EM.
- To handle stop words specific to your data, a common workflow is to run LDA, look at topics, identify stop words that show up in the topics, filter them out, and run LDA again.
- Picking the number of topics is an art; there are algorithms to choose automatically, but domain expertise is critical to getting good results.
- The Pipelines API feature transformers are very useful for preprocessing text to prepare it for LDA; see Tokenizer, StopwordsRemover and CountVectorizer in particular.
What’s next?
Spark contributors are actively working on improving our LDA implementation. Some works in progress include: Gibbs sampling (a slower but sometimes more accurate algorithm), streaming LDA algorithms, and hierarchical Dirichlet processes (for automatically choosing the number of topics).
Acknowledgements
The development of LDA has been a collaboration between many Spark contributors.
Feynman Liang, Yuhao Yang, Joseph K. Bradley, and others made recent improvements, and many others contributed to the earlier work.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.