Apache Spark Trending in the Stack Overflow Survey
by Reynold Xin
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Last week, Stack Overflow released the result of their 2016 developer survey. This is one of the most significant surveys in the field with responses from 56,033 engineers across 173 countries. A few things from this survey caught my eye:
- Apache Spark is the second most trending technology, only after React.
- Apache Spark is the top paying tech.
- Equally interesting is that 5 out of the top 7 top paying techs are data and cloud computing related.
- Python, R, and SQL are the top tech stack for data scientists.
- Vim is a lot more popular than emacs (ok just kidding).
I've included a few charts from the survey for discussion below:
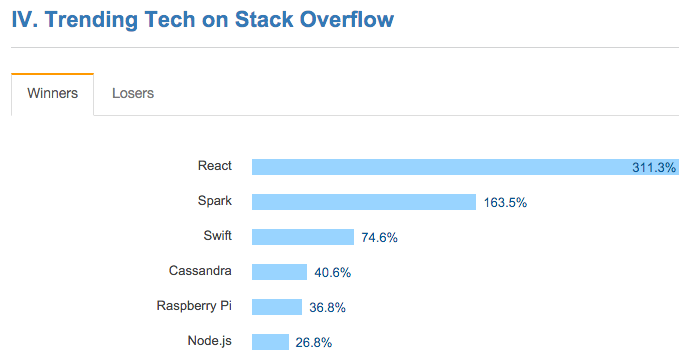
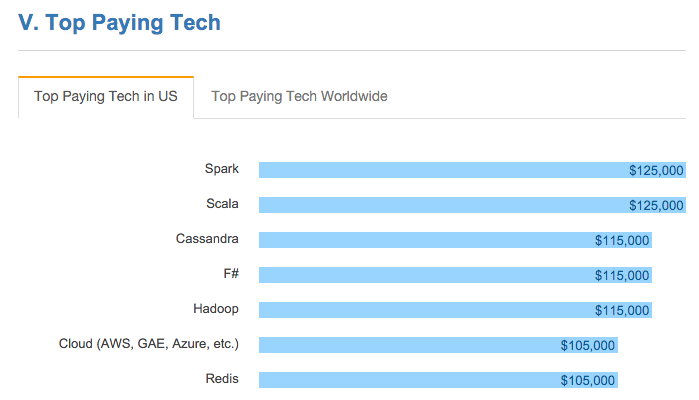
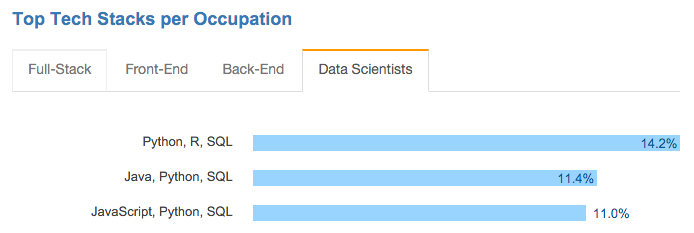
First, in partnership with UC Berkeley and UCLA, Databricks launched two free massive open online courses (MOOCs) last year about Spark, data science, and machine learning. Over 130,000 people signed up. One of these Introduction to Big Data with Apache Spark was rated as one of the top 10 MOOCs across all fields (i.e. not just computer science) last year.
This year we have increased our investment and will run 5 MOOCs as part of edX’s Data Science and Engineering with Spark series, including:
- CS105x: Introduction to Spark (April 2016)
- CS110x: Big Data Analysis with Spark (May 2016)
- CS120x: Distributed Machine Learning with Spark (June 2016)
- CS125x: Advanced Distributed Machine Learning with Spark (Aug 2016)
- CS115x: Advanced Spark for Data Science and Data Engineering (Oct 2016)
We provided free Databricks accounts to many MOOCs students last year after they told us that some features of the Databricks platform such as collaborative data exploration and automatic cluster management were really useful for learning Spark. In response, we created Databricks Community Edition (in beta) for developers, data scientists, data engineers and anyone who wants to learn Spark. On this platform, users have access to a micro-cluster, a cluster manager and a notebook environment to prototype applications. All users can share their notebooks and host them free of charge with Databricks.
In addition to the platform itself, Databricks Community Edition comes pre-populated with Spark training resources, including the MOOCs. We will also continue to develop Spark tutorials and training materials over time, which will be directly accessible from the Community Edition. Databricks Community Edition is still in private beta and we are slowly rolling it out to as users on the waitlist. Fill out this form to join the waitlist.
Finally, we continue to make Spark easier to use. We believe that the easiest APIs to learn are the ones that users are already familiar with, in programming languages they already know. DataFrames, machine learning pipelines, SQL, R, and Python support are all features of Spark that build on this idea.
We hope our educational efforts will help even more organizations and engineers build their Spark skills and extract value from data. If you want to learn Spark, sign up for the MOOCs and the Databricks Community Edition private beta.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.