An Introduction to Writing Apache Spark Applications on Databricks
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Try this notebook in Databricks
This is part 1 of a 3 part series providing a gentle introduction to writing Apache Spark applications on Databricks.
When I first started learning Apache Spark several years ago, the biggest challenge for me was finding material that introduced me to the key concepts and the thinking that one must apply to write efficient Spark applications. I attended the UC Berkeley AMP Camps as a graduate student at UC Berkeley and Spark Summit SF 2015; while these were great learning experiences that taught me the basics, I had a hard time finding examples that took me beyond the basic word count. This changed when I started working at Databricks six months ago.
Databricks has excellent reference resources for our users in the Databricks Guide. However, I also observed that many users want Apache Spark tutorials that progress through an end-to-end example in more detail. I frequently get questions such as, “how do I use DataFrames, SparkSQL, or Datasets?”, “how do I create a machine learning pipeline?” or “how do I create a UDF and use it in Spark SQL and on my DataFrames?” So I set about writing a series of three tutorials in the form of Databricks notebooks to illustrate these answers.
With the general availability of Databricks Community Edition (DCE), a free version of the Databricks platform, anyone can sign-up and run these notebooks to learn hands-on. If you do not have access to DCE yet, sign up now to work through the examples in the notebooks.
What’s in the First Tutorial
The first part of the series is intended for the most general audience - anyone who is new to Apache Spark or Databricks. This notebook will demonstrate the tools in Databricks that make working with your data easier, showing you how to do things like creating Apache Spark clusters, visualizing data, and simplifying access to the Spark UI. Beyond Databricks itself, you’ll also get an architectural overview of Apache Spark to give you a sense of what is going on during the execution of a Spark job. This notebook is also a good review for those who want to make sure they’ve got a solid understanding of the fundamentals of Apache Spark.
The major concepts covered in this tutorial include:
- Introducing Apache Spark and Databricks terminology.
- The different contexts and environments in Apache Spark including 2.0’s SparkSession Context.
- The fundamental data interfaces like DataFrames and Datasets.
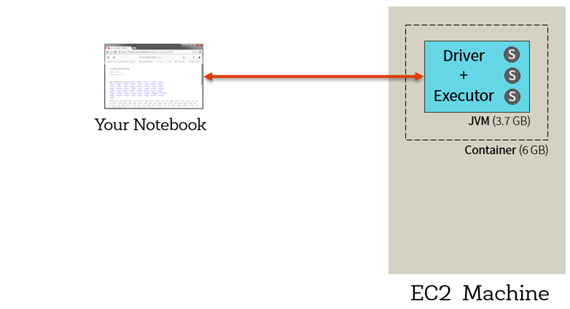
- An overview of how Apache Spark takes code and executes it on your Spark cluster in Databricks Community Edition.
- The difference between transformations and actions.
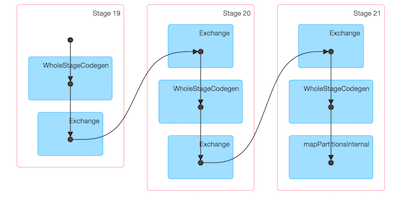
- A walkthrough of the below directed acyclic graph (DAG), to see how Spark uses transformations and actions to take your raw data and convert it into its final form. Since Databricks already includes the preview version of Apache Spark 2.0, we’ll be able to compare the ways that different Spark versions generate their query plans. Here’s an extract from a 2.0 query plan:
You can download the first notebook here.
What’s Next
While this first notebook introduces each concept at a high level, notebooks two and three in the series take a much deeper dive into the material. The second part of this series will show how a data scientist should go about using Spark and Databricks together. We’ll do this by attempting to predict the number of farmers’ markets in a given zipcode based on the individual and business taxes paid in the area. The final notebook in the series will take the reader through an ETL pipeline end-to-end. This will include parsing raw log files, creating UDFs, handling messy datetimes, and combining that with another dataset — all the while taking advantage of Spark’s data-connectors to integrate with multiple data sources. These notebooks have plenty of code and explanations so be sure to stay tuned for the next notebooks in the series!
If you have not done so, download the notebook and sign-up for Databricks Community Edition to get started today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.