Integrating Apache Airflow and Databricks: Building ETL pipelines with Apache Spark
This is one of a series of blogs on integrating Databricks with commonly used software packages. See the “What’s Next” section at the end to read others in the series, which includes how-tos for AWS Lambda, Kinesis, and more.
Apache Airflow Overview
Airflow is a platform to programmatically author, schedule, and monitor workflows. It can be used to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies.
There are two key concepts in Airflow: DAGs describe how to run a workflow, while Operators determine what actually gets done by defining a task in a workflow. Operators are usually (but not always) atomic, meaning they can stand on their own and don’t need to share resources with any other operators.
Airflow is a heterogenous workflow management system enabling gluing of multiple systems both in cloud and on-premise. In cases that Databricks is a component of the larger system, e.g., ETL or Machine Learning pipelines, Airflow can be used for scheduling and management.
Airflow already works with some commonly used systems like S3, MySQL, or HTTP endpoints; one can also extend the base modules easily for other systems.
This blog assumes there is an instance of Airflow up and running already. See the “References” section for readings on how to do setup Airflow.
How to use Airflow with Databricks
The Databricks REST API enables programmatic access to Databricks, (instead of going through the Web UI). It can automatically create and run jobs, productionalize a data flow, and much more. It will also allow us to integrate Airflow with Databricks through Airflow operators.
Airflow provides operators for many common tasks, and you can use the BashOperator and Sensor operator to solve many typical ETL use cases, e.g. triggering a daily ETL job to post updates in AWS S3 or row records in a database.
The BashOperator
The BashOperator executes a bash command. It can be used to integrate with Databricks via the Databricks API to start a preconfigured Spark job, for example:
You can test this operator by typing in:
In the above example the operator starts a job in Databricks, the JSON load is a key / value (job_id and the actual job number).
Note: Instead of using curl with the BashOperator, you can also use the SimpleHTTPOperator to achieve the same results.
The Sensor Operator
The Sensor operator keeps running until a criteria is met. Examples include: a certain file landing in a S3 bucket (S3KeySensor), or a HTTP GET request to an end-point (HttpSensor); it is important to set up the correct time interval between each retry, ‘poke_interval’. It is necessary to use a Sensor Operator with the ‘hook’ to the persistence layer to do a push notification in an ETL workflow.
JSON File to Parquet Processing Example
Below is an example of setting up a pipeline to process JSON files and converting them to parquet on a daily basis using Databricks. Airflow is used to orchestrate this pipeline by detecting when daily files are ready for processing and setting “S3 sensor” for detecting the output of the daily job and sending a final email notification.
Setup of the pipeline:
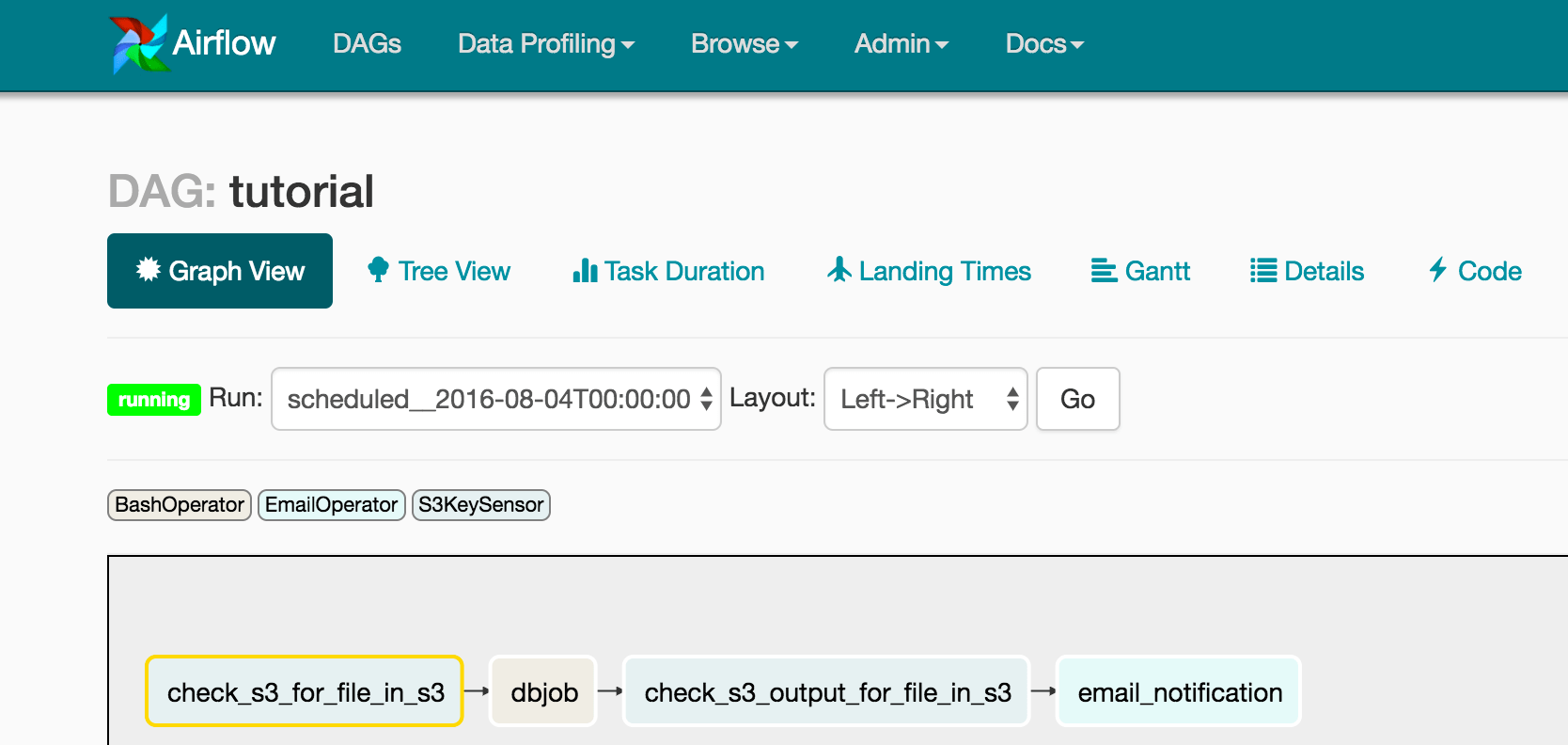
As shown above this pipeline has five steps:
- Input S3 Sensor (check_s3_for_file_s3) checks that input data do exist:
- Databricks REST API (dbjob), BashOperator to make REST API call to Databricks and dynamically passing the file input and output arguments. For the purposes of illustrating the point in this blog, we use the command below; for your workloads, there are many ways to maintain security if entering your S3 secret key in the Airflow Python configuration file is a security concern:
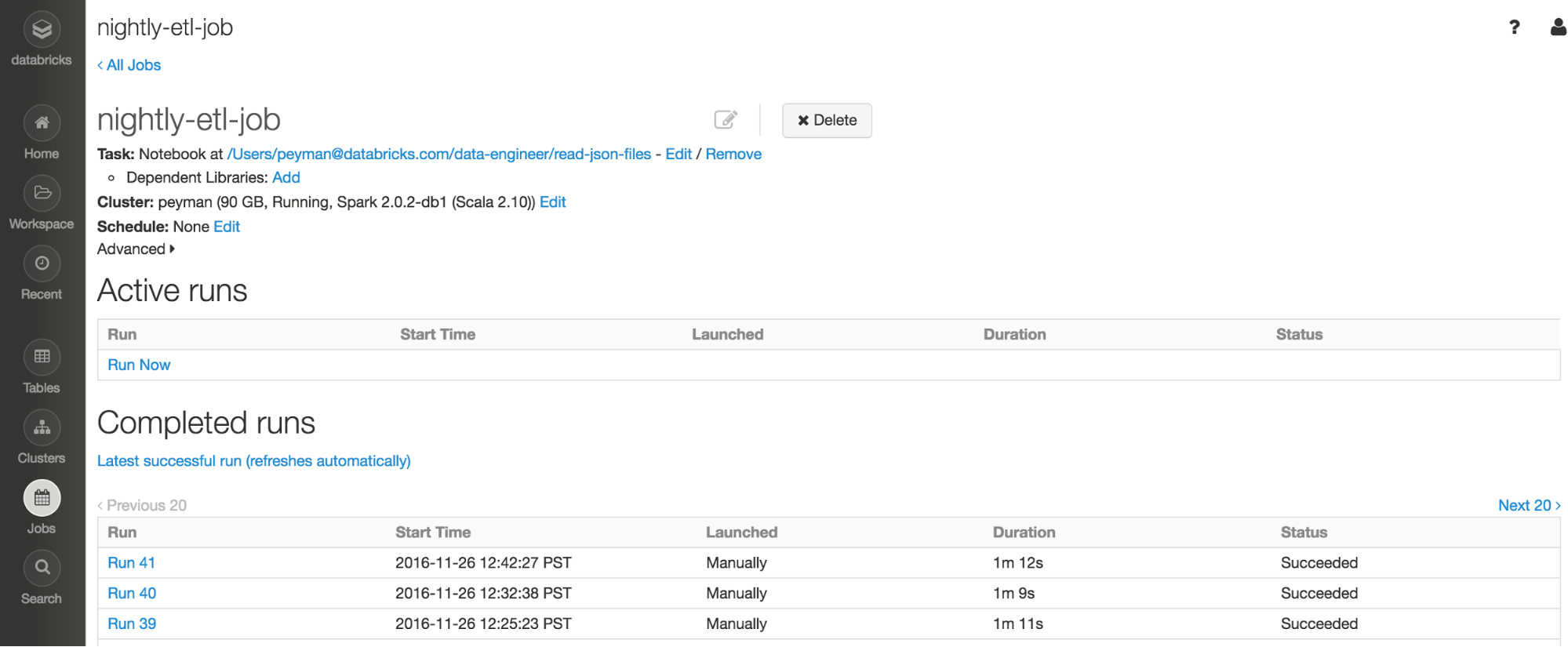
Above is the screen-shot of the job within Databricks that is getting called from Airflow. Read the Databricks jobs documentation to learn more.
- Databricks Action involves reading an input JSON file and converting it into parquet:
- Output S3 Sensor (check_s3_output_for_file_s3) checks that output data do exist:
- Email Notification (email_notification), sends out an email to alert when the job is successful.
Below is the Python configuration file for this Airflow pipeline:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.