Delivering Exceptional Care Through Data-Driven Medicine
This is a guest blog from our friends at Distal.
Today, 96% of U.S. health care providers use electronic health records (EHRs) - up from 10% in 2008. When I was a clinical intern, paper charts were the norm. Today, we practice medicine in a data-driven world. Large payers, such as Medicare and health insurance companies, would like to see providers leverage clinical data in ways that improve health outcomes, lower costs, and improve the patient experience.
In order to effect such change, payers have begun to shift some of the costs associated with suboptimal care to providers; this is a fundamental shift in the healthcare industry. Just a few years go, healthcare claims were paid without regard to clinical outcomes. Today, over 30% of all Medicare payments ($117B annually) are linked to clinical quality through a number of “value-based payment” mechanisms. Beginning this year, healthcare providers that fail to demonstrate progress toward data-driven quality improvement will face substantial financial penalties.
Providers have responded by assembling teams of clinical quality managers, informaticians, and health IT experts to navigate the transition to value-based payment. These clinical and technical leaders must overcome a number of technical challenges, and it remains to be seen whether all providers will ultimately succeed. An emerging theme among providers that are reporting early wins is the central role of big data technologies, such as Apache Spark.
Healthcare providers have a big data problem
- Massive volume and overwhelming variety: Collectively, U.S. hospitals generate over 20 petabytes of data each year. This figure doesn’t include data collected in outpatient medical offices, pharmacies, third-party clinical labs, consumer wearables, or portable monitors.
- Disparate systems: Clinical data doesn't reside exclusively in electronic health records (EHRs). It is common to have clinical data scattered across radiology, lab, and pharmacy information systems (to name a few).
- Siloed data stores: Sometimes multiple EHR instances are deployed at a single physical location. For example: Stanford Hospital and Lucile Packard Children's Hospital at Stanford both use the same EHR software but they operate separate instances. As a result, there is no way to retrieve a complete patient record from the adult hospital through the children's hospital EHR (and vice versa). This is a big problem in the setting of medical emergencies where patient care teams are comprised of staff from both hospitals (e.g. STAT C-sections or pediatric trauma). Poor data interoperability in healthcare creates information gaps that expose patients to harm and contribute billions to wasteful spending.
- Inconsistent data schemas: The RDBMS representation of raw clinical data consists of hundreds of tables that relate to one another in ways that are poorly documented (if at all). That's because the underlying schemas evolve as customizations are made to the front-end. This also means that Stanford's data schema is very different from that of Kaiser's, Sutter's, and UCSF - even though they all license their EHR software from the same vendor.
How Distal tames healthcare big data with Databricks
Distal offers a turnkey software solution that connects healthcare providers to the information they need to deliver exceptional care. Our clinical intelligence platform delivers clinically-meaningful insights through an easy-to-use web application. We use Databricks to build ETL pipelines that blend multiple data sources into a canonical source of truth. We also combine Distal’s proprietary algorithm with MLlib's DataFrame-based pipelines to automate data modeling and clinical concept mapping.
Databricks has been key to building a cost-effective software solution that enables clinicians to engage in data-driven quality improvement. Databricks allows us to leverage the power of Apache Spark to:
- ingest massive volumes of structured, semi-structured, and unstructured data from a variety of sources,
- apply a common semantic layer to raw data,
- integrate and deduplicate data elements,
- analyze the data,
- map the results to a common set of API resources,
- surface the insights to the end-user, and
- protect patient privacy through encryption, granular access controls, and detailed audit trails.
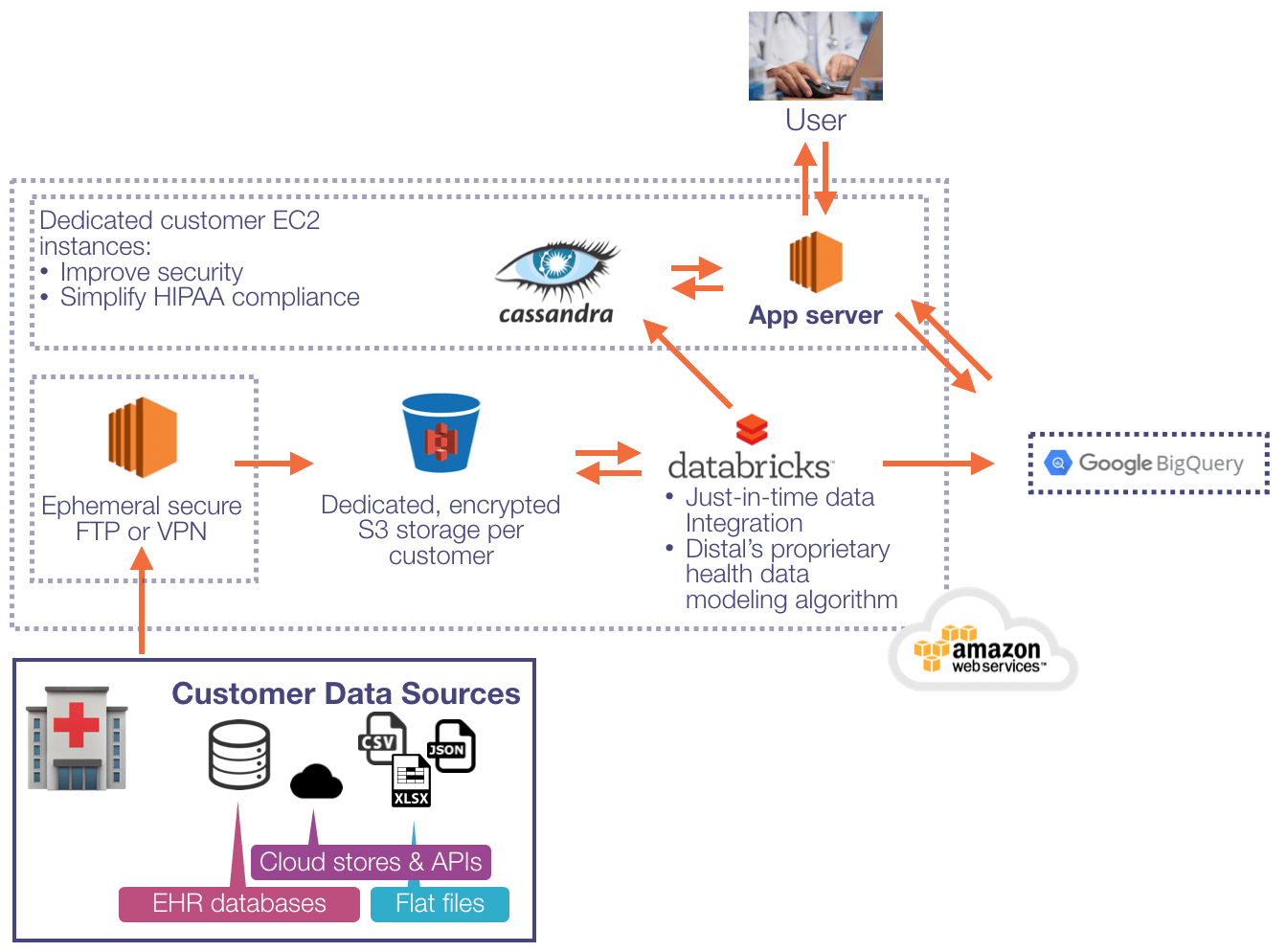
Databricks components that play particularly important roles include:
- Notebooks and collaboration features: Databricks notebooks allowed us to quickly iterate on new ETL components and to test how they fit into complementary pipelines. We began with a single notebook that included all of the code to get the job done. At this stage, there were snippets of Java, Scala, and Python in a single notebook. Once we had a working concept, we broke out functional code blocks into separate notebooks in order to run them as independent jobs. Throughout the process, we relied on Databricks’ collaboration features to a) fix bugs, b) track changes, and c) share production-ready libraries internally.
- Databricks library manager: We felt the need to move quickly, so we incorporated open source libraries/packages into our ETL processes whenever possible. Very early on, we used Databricks to search through Spark Packages and Maven Central for the most stable, best-supported libraries. Once the pipelines began to take shape, we used the Databricks package manager to automatically attach required libraries to new clusters.
- Integration with Amazon Web Services: The fact that Databricks is built on Amazon Web Services (AWS) allowed us to seamlessly integrate with the full spectrum of AWS services while adhering to security best practices. Rather than relying exclusively on AWS access keys, which can be lost or stolen, Databricks enabled us to use IAM roles to restrict read/write access to S3 buckets. Furthermore, we restricted access to pipelines that handle sensitive data by applying user-level access controls through the Databricks admin panel.
A hint of things to come
With Apache Spark serving as the cornerstone of our ETL and analytics stack, we are confident in our ability to develop new features and products. In the near term, we are looking to augment our ETL pipelines and knowledge representation by developing novel ML algorithms and borrowing from existing methods. We are also looking grow our team. If you love Databricks and would like to help us build products that have a measurable impact on millions of people, please introduce yourself by sending a quick note to team@distal.co.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.