Next Generation Physical Planning in Apache Spark
Never underestimate the bandwidth of a station wagon full of tapes hurtling down the highway. —Andrew Tanenbaum, 1981
![]() magine a cold, windy day at Lake Tahoe in California. When a group of Bricksters who were cross-country skiing stopped for lunch, one found a 4TB hard drive in their backpack. One brickster remarked that this data had traveled by car over 200 miles in less than 8 hours — accounting for a speed of over 1 Gb/s. This led to an idea: What if Apache Spark leveraged physical storage media and vehicles to move data?
magine a cold, windy day at Lake Tahoe in California. When a group of Bricksters who were cross-country skiing stopped for lunch, one found a 4TB hard drive in their backpack. One brickster remarked that this data had traveled by car over 200 miles in less than 8 hours — accounting for a speed of over 1 Gb/s. This led to an idea: What if Apache Spark leveraged physical storage media and vehicles to move data?
 High throughput physical data channel leading from a data lake
High throughput physical data channel leading from a data lake
Transcontinental Data Transfer Shortcomings
In this era of high-volume, inter-continental data processing, with globally distributed, exponentially growing data volumes, networks are too slow. A single link between two nodes in a datacenter may be as slow as 10Gb/s -- and cross-datacenter links are often 100x slower! So how do we better solve the everyday problem of transferring billions, trillions, or quadrillions of bytes around the world?
While for analytical queries it is possible to optimize global execution via proper task and data placement, sometimes data movement is unavoidable, e.g. due to the nature of an ETL job, compute constraints, or local regulations. We found a number of such use cases when we talked with our customers, including:
- Recurring transfers due to
- Desire to retain data in particular region (e.g. safe harbor laws)
- Excess purchased compute capacity available in certain regions
- Streaming ETL of cross-continental data
- One-time transfer tasks, such as
- Moving data to implement with data architecture changes
- Disaster recovery (adding or recovering data replicas)
For example, consider a Spark job in which thousands of terabytes of data distributed in the Mumbai, Singapore, and Seoul regions need to be moved to Sydney, where there is more purchased compute capacity available. We'd also like to repartition the data into an appropriate number of Parquet-encoded files to optimize performance.
Normally, such a job would be expressed in Spark as follows:
However, if a user were to run this job, they would quickly see two problems.
- Cross-region data transfer across the Internet is incredibly slow. Compared to intra-datacenter networks, Internet egress is orders of magnitude slower.
- Cross-region data transfer is incredibly expensive. Large data transfers can sometimes cost into the millions of dollars.
Most users, faced with these insurmountable time and cost obstacles, would have to turn to hand-optimizing their data transfers. More sophisticated users may seek to optimize data transfers using private links. Others would consult with maritime shipping agencies to figure out how to ship their data -- in secure physical containers.
At Databricks, our vision is to make Big Data simple. So we find these sort of workarounds unacceptable. Inspired by their experience with the efficiency of cross-country skiing, our group of engineers turned their efforts towards addressing this issue.
Introducing Catalyst APP (Actual Physical Planning)
Enter Catalyst actual physical planning. Combining the power of the Spark Catalyst optimizer with Amazon Snowmobile, Spark identifies queries running with compute in one region and data in another region, and adaptively decides to migrate the data to the local datacenter before running the query. Prior to this approach, all data access would necessarily occur cross-region, going over public Internet links and capped in a best-case scenario at around 100 Gb/s.
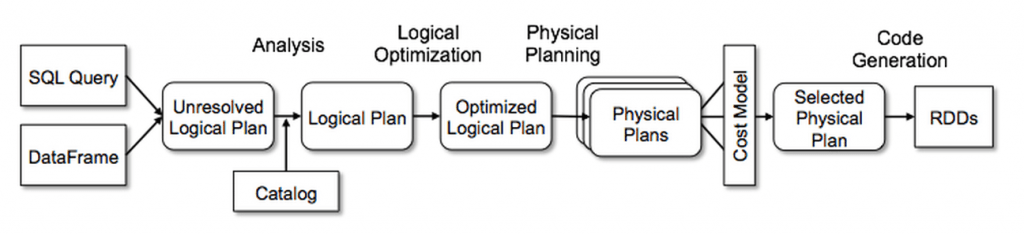
Catalyst APP uses the Amazon Snowball and Snowmobile APIs to schedule one or more trucks (depending on the amount of data and desired parallelism) to one datacenter and ship it to the target datacenter. Once the transfer is complete, the query begins on the local data.
Using this technique, we’ve found we can achieve 60x the performance while being 30x cheaper than the alternatives.
| Bandwidth | Cost per exabyte | |
|---|---|---|
| Over-the-Internet | ~100 Gb/s | $80mm ($0.08/GB) |
| Mail (USPS) (250k 4TB hard drives) | ~53 Gb/s (1 person boxing and unboxing drives constantly for 4 years) | $2.25mm ($1.25mm shipping, $1mm min. salary) |
| Lay your own undersea cable | ~60,000 Gb/s (but takes a couple years to build) | $300mm (fixed cost) |
| Snowmobile (10 trucks, 2 week travel time) | ~6,614 Gb/s | $2.5mm ($0.0025/GB) |
| Improvement | 66x faster than Internet | 32x cheaper than Internet |
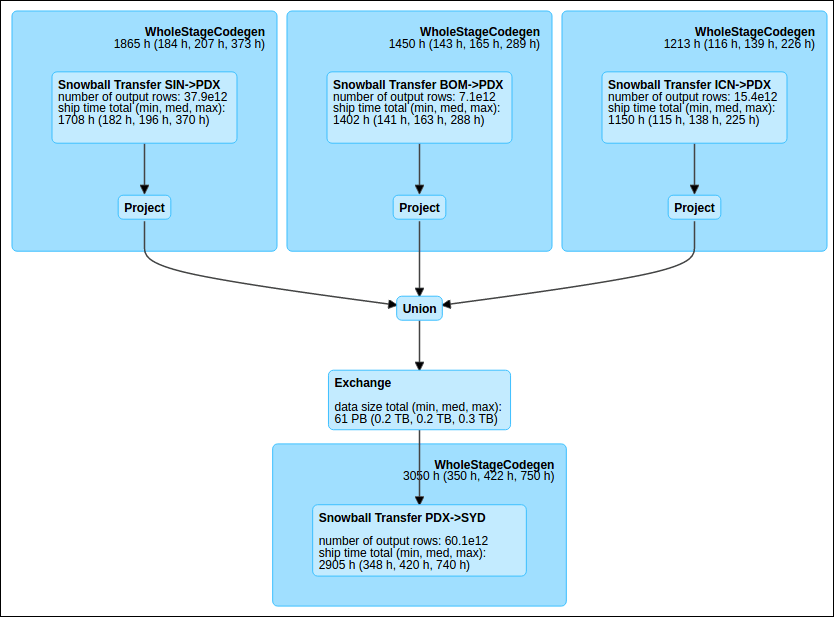
Let us describe how Catalyst APP works in detail by considering the previous example of an ETL job. This job requires executing three steps:
- First, data needs to be read from the three source regions.
- Second, the data needs to be efficiently partitioned into 250,000 slices.
- Finally, the data needs to be written into the destination region (Sydney).
Normally, Catalyst will only consider one physical strategy for each of these steps, since it has no alternative but to access the data over the network from the Spark executors. This unoptimized query plan is simple:
When we ran the job using this naïve plan, it never finished execution because the WAN transfer was too slow, despite using hundreds of executors. We also saw our AWS bill skyrocket. Eventually, we gave up and cancelled the job after a few months:
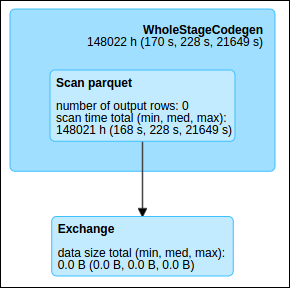
However, with Catalyst actual physical planning, Catalyst can consider alternate strategies for moving the data. Based on data statistics and real-time pricing information, it determines the optimal physical strategy for executing transfers. In the optimized job, from our cluster in the Oregon (us-west-2) region, Spark ingests the data from Mumbai, Singapore, and Seoul via Snowmobile, performs a local petabyte-scale repartitioning, and then writes it out to Sydney again via Snowmobile.
This optimized plan completed in only a few weeks -- more than fast enough given the scale of the transfer. In fact, if not for some straggler shipments when crossing the Pacific (more on that later) it would have completed significantly faster:
Future Optimizations
While Catalyst actual physical planning is already a breakthrough, we also plan on implementing several other physical planning techniques in Spark:
Physical Shuffle: The best distributed sorting implementations, even using Apache Spark, take hundreds of dollars in compute cost to sort 100 TB of data. In contrast, using physical data containers, an experienced intern at Databricks can sort over 10 PB per hour. We are excited to offer this physical operator to our customers soon. If you are interested in an internship, applications for that are also open.

Actual Broadcast Join: Many Spark applications, ranging from SQL queries to machine learning algorithms, heavily use broadcast joins. On traditional intercontinental networks, broadcast joins soon become impractical for large tables due to congestion. However, the physical electromagnetic spectrum is naturally a broadcast medium. Thanks to the falling cost of satellite technology, we're excited to (literally) launch a Physical Broadcast operator that can transmit terabyte-sized tables to globally distributed datacenters.
Serverless Transfer: If the query plan includes no intermediate transformations, it is possible to dispatch Snowmobile jobs that write directly to the output destination. This cuts cost and latency by removing the need for a cluster. In fact, thanks to deep learning on Apache Spark, future transfers could be both serverless and driverless.
CAPP (Catalyst Actual Physical Planning) Theorem
In the course of this work, we noticed that in addition to the expected weather delays, piracy is a real problem for high throughput cross-continental data transfers. This is especially true when using low-cost shipping, creating a tradeoff between Piracy and Cost. We formalized this tradeoff in a new paper on an extension to the CAP Theorem called CAPP. There, we discuss how we ultimately must choose two of the following: Consistency, Availability, Partition-tolerance, and Piracy-proofness.
Thankfully Databricks can automatically encrypt data in transit, which means that Catalyst APP is safe even for organizations with the most stringent data security requirements.
Conclusion
Catalyst actual physical planning enables a new class of exabyte-scale, cross-continent ETL workloads on Databricks, moving us one step closer to our vision of making Big Data simple. Watch out for our entry in this year’s international sorting competition. Catalyst actual physical planning is now available in private preview for Databricks users. Please contact us if you are interested in early access.
Also, Happy April 1st!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.