Best Practices for Coarse Grained Data Security in Databricks
by Bill Chambers and Jules Damji
At Databricks, we work with hundreds of companies, all pushing the bleeding edge in their respective industries. We want to share patterns for securing data so that your organization can leverage best practices as opposed to recreating the wheel when you on -board to Databricks’ Unified Analytics Platform. This post is primarily aimed at those who are managing data in their organizations. This means controlling access to certain data and maintaining which users can access what data.
Introduction and Background
Before diving into the details of operationally what you’ll be doing, let’s make sure we have the proper vocabulary to ensure that you can turn around and enact this in your organization quickly.
DBFS
The Databricks File System (DBFS) is available to every customer as a file system that is backed by S3. Far more scalable than HDFS, it is available on all cluster nodes and provides an easy distributed file system interface to your S3 bucket.
dbutils
dbutils is a simple utility for performing some Databricks related operations inside of a Databricks notebook in Python or in Scala. They provide a number of commands to help you navigate through your S3 buckets; however, the most relevant is the fs module.
Running the following code will alias an S3 bucket as a mount point. dbutils.fs.mount(“s3a://data-science-prototype-bucket/”, “/mnt/prototypes”)
This is available across all cluster nodes at the path /mnt/prototypes/. Or equivalently, dbfs:/mnt/prototypes/
This means that we can write out a DataFrame to this path (and any directories underneath) just as if we were writing to HDFS, but DBFS will write to the S3 bucket.
df.write.parquet(“/mnt/prototypes/bill/recommendation-engine-v1/”)
In short, DBFS makes S3 seem more like a filesystem, where mount points make specific S3 bucket accessible as parts of filesystems. It’s really just an alias or shortcut that allows for rerouting one S3 physical path to another logical path. Naturally, a user must have access to the destination S3 bucket in order to access the data.
The next few sections will cover the different ways we can securely access S3 buckets.
IAM Roles vs Keys
On AWS there are two different ways that you can write data to S3. You can either do it with an IAM Role or an access key. Functionally, IAM Roles and Keys can be used interchangeably. You can use either of these on your Databricks clusters or use them in conjunction with DBFS.
When you mount a bucket with an S3 path using DBFS and if that path is associated with an IAM Role, then all nodes and users as part of the IAM Role in your cluster will have read and write access to that mounted path. For instance,
dbutils.fs.mount(“s3a://data-science-prototype-bucket/”, “/mnt/prototypes”)
can be read by only a machine with an IAM role that has access to that particular bucket.
By contrast, when you mount a bucket with an AWS key and an s3 path, as we see in the following snippet,
dbutils.fs.mount(“s3a://KEY:SECRET_KEY@data-science-prototype-bucket/”, “/mnt/prototypes”)
then this mount point will be available at the organizational level based on the access control policies of that key. That means that any cluster will be able to read (and potentially write) data to that mount point.
Controlling Coarse-Grained Data Access
Now that we introduced the various definitional terms, let’s explore how we can actually go about securing our data. All of these access control measures are performed at the administrative level. That is, individual users should not be setting these up, only administrators should.
Note: Because keys can be copied or compromised, they are not the safest way to access data sources. In general, you should favor IAM roles in place of keys.
Most Secure: Clear separation of access
The most secure setup you can undertake in Databricks is to define IAM Roles whenever you create clusters. To this IAM Role, add grant access rights, such as read and write, to S3 buckets. With cluster access controls, you can control which users have access to which data, through these IAM roles.
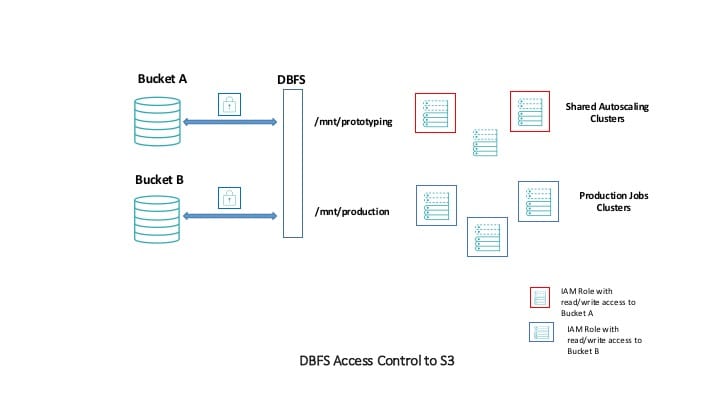
The S3 buckets are on the left side, and we have two types of clusters, a shared autoscaling cluster for development work that has permissions to read and write to the prototyping S3 bucket (and mount point) and production clusters that can read and write from the production bucket (B).
It should go without saying but the following code, running on the Shared Autoscaling or Databricks Serverless cluster,
df.write.parquet(“/mnt/production/some/location”)
would fail because the IAM Role associated with that cluster does not include access rights to bucket B.
This is a common pattern for engineering organizations who want to restrict access at the cluster level and want to ensure that production data is not mixed with prototyping data. An example policy for these IAM roles might be.
Secure: A collaborative access
Another pattern that is similar but slightly less secure works more often for data science teams, who work in collaboration across clusters. In this scenario, some data should be read-only from all clusters, for instance, for training and testing different data science models but writing to that location should be a privileged action. In this architecture, we will mount two buckets with keys. The production bucket is mounted with read-only permission. When using DBFS, these keys will be hidden from view (unlike using raw S3). Alternatively, you can also just specify read-only access with an IAM role. However, this mount will not, by default, be accessible on all clusters. You’ll have to be sure to start a cluster with an IAM Role.
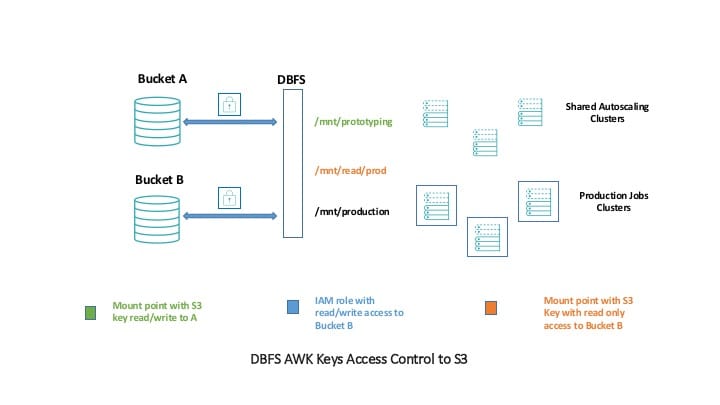
That means that the following code works just fine on any cluster.
spark.read.parquet(“/mnt/read/prod/some/data”)
However, this code would fail on any cluster.
df.write.parquet(“/mnt/read/prod/some/data”)
This is because the S3 key does not have the proper permissions. In this structure, you will note that we can mount the same S3 bucket in multiple ways; we could even mount different prefixes (directories) to different locations as well.
The only way to actually write data to the production bucket is to use the proper IAM role and write to the specific location as we do in the following snippet.
df.write.parquet(“/mnt/production/some/data/location”)
This pattern can help administrators ensure that production data is not accidentally overwritten by users while still making it accessible to end users more generally.
Least Secure: Only Keys
The last access pattern to access S3 buckets is to use only AWS access keys. Because keys can be easily copied or compromised, we do not recommend this data access pattern in Databricks.
Conclusion
In this post, we outlined a number of best practices to secure and control access to your data on Databricks’ Unified Analytics Platform. With DBFS, we can mount the same bucket to multiple directories using both AWS secret keys as well as IAM roles. We can use these mechanisms to our advantage, making some data generally available for reading but not writing.
The next post will cover how we solve fine-grained access controls in Databricks Enterprise Security (DBES).
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.