Do your Streaming ETL at Scale with Apache Spark’s Structured Streaming
At the Spark Summit in San Francisco in June, we announced that Apache Spark’s Structured Streaming is marked as production-ready and shared benchmarks to demonstrate its performance compared to other streaming engines.
Structured Streaming is a novel way to process streams. Not only does this new way make it easy to build end-to-end streaming applications, but it also handles all the underlying complexities for fault-tolerance. You as a developer need not worry about it.
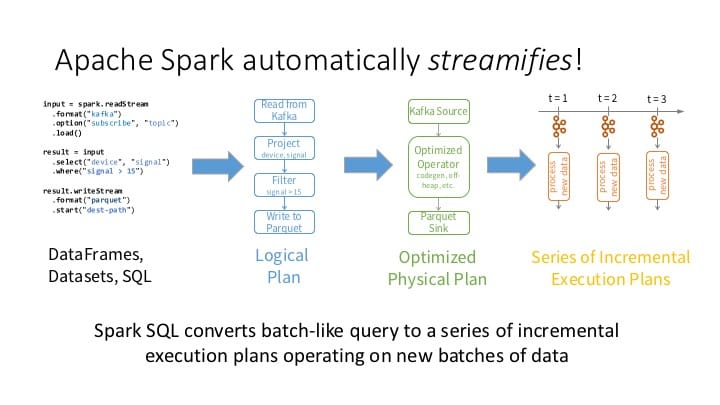
At the Data + AI Summit, I will present two talks covering many aspects of Structured Streaming. The first talk covers concepts, APIs, integration with external sources and sinks, underlying incremental Spark SQL execution engine, and fault-tolerant semantics, while the second will focus on stateful stream processing using mapGroupsWithState APIs.
- Easy, Scalable, fault-tolerant Stream Processing with Structured Streaming in Apache Spark
- Deep Dive into Stateful Streaming Processing in Structured Streaming
Why should you attend these sessions? If you are a data engineer or data scientist who wants to turbocharge your ETL with streaming, build low-latency predictive IoT or fraud-detection applications with fast-data, and create streaming pipelines for data ingestion and real-time streaming analytics, then attend my sessions.
And see you Dublin!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.