Accelerating Discovery with a Unified Analytics Platform for Genomics
by Ion Stoica, Frank Austin Nothaft, Ram Sriharsha and Michael Ortega
Today we are proud to introduce the Databricks Unified Analytics Platform for Genomics. With a unified platform for genomic data processing, tertiary analytics, and machine learning at massive scale, healthcare and life sciences organizations can accelerate the discovery of life changing treatments and further advancements in personalized and preventative care.
The Genomic Data Explosion
The first human genome took 13 years and over $2.5 billion to sequence. Today, a human genome can be sequenced in a couple days for less than the price of the latest iPhone. As a result, pharmaceutical and healthcare organizations are profiling the genomes of millions of patients, generating thousands of petabytes of data. To put this in perspective, genomic sequencing is expected to generate up to 40 exabytes of data per year by 2025. This will dwarf the amount of data generated by Youtube and Twitter combined.
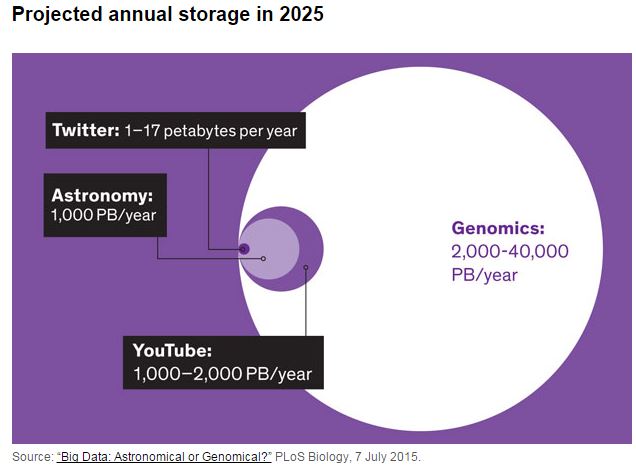
When paired with clinical data, genomic data offers huge potential to accelerate drug discovery, predict disease risks, and personalize treatments. This will enable healthcare providers to significantly improve patient outcomes.
The Technology Challenges of Modern Genomic Workflows
The potential to impact care has never been greater. Yet, the tools and systems that genomic researchers rely on do not provide the speed, scale and flexibility needed to draw insight from these massive genomic datasets. These challenges fall into three key areas:
- Messy sequence data and complex pipelines - a genomic pipeline for processing the petabytes of messy data coming off of a DNA sequencer is typically constructed of 5-10 tools (e.g., GATK, BWA, etc) that are stitched together in up to 40 stages. Building and maintaining these complex pipelines is costly, time consuming, and leads to unnecessary delays in downstream analytics.
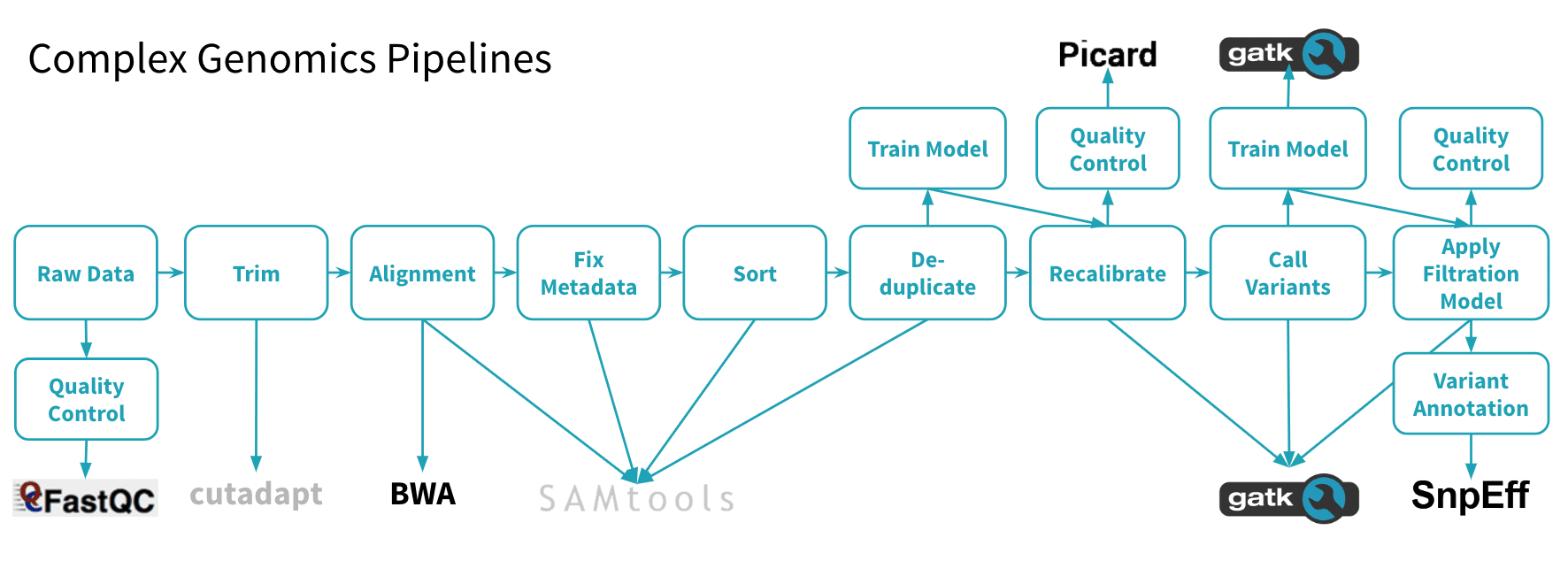
- Antiquated analytics tools - many of the genomics tools used today are command line programs built for single node machines. They were not designed for the cloud and trying to run them as such is incredibly challenging and adds multiple processing steps. Additionally, bioinformatics tools typically have complex dependencies, leading users to package them into monolithic Docker containers, which are deployed via a workflow management system. This makes developing and deploying pipelines labor intensive and time consuming, and makes scaling analytics to current data volumes infeasible. A basic set of queries can take days or weeks to execute. And advanced analytics like cross-cohort joint variant calling and machine learning are simply not possible.
- Siloed research teams - whether you’re developing a new drug or prescribing a personalized treatment, diverse teams must work together to process, analyze, and interpret insights from genomic and clinical data. The disjointed nature of today’s tools force bioinformaticians, computational biologists, and clinicians to work in silos which further hampers the discovery process.
At Databricks, we’ve seen these problems manifest at organizations across the health ecosystem from pharmaceutical companies to healthcare providers to biotech startups. Based on this experience, we’ve been looking for ways to radically simplify and scale genomic analysis. In short, what if we could enable teams to explore today’s largest genomic datasets using cutting edge analytics and machine learning without any of the wait times? This is exactly what we set out to solve.
Accelerating Discovery with Unified Analytics for Genomics
The Databricks Unified Analytics Platform for Genomics provides the speed and scale bioinformatics teams need to unlock insights buried in their genomic data. We’ve extended the existing capabilities of the Databricks Unified Analytics Platform with genomic-specific toolkits and optimizations to deliver on three specific goals:
- Simplified genomic pipelines - prebuilt best practice pipelines are provided out-of-the-box ready in a hosted cloud platform. Instead of manually configuring a complex pipeline, all it takes is a few clicks to provision cloud resources, connect to read, variant, and feature data in Azure or AWS and kick-off bulk processing jobs.
- Interactive tertiary analytics and AI at scale - prepackaged genomic analytics—such as Joint Variant Calling, GWAS, PheWas, eQTL—and machine learning frameworks are provided in a unified platform. Genomic queries are optimized to run in parallel at speeds 60-100x faster than open source tools so you can interactively explore your genomic data at scale.
- Improved productivity across integrated teams - shared workspaces with detailed revision tracking fosters collaboration across the discovery and diagnosis lifecycle. Support for SQL, R, Python, Java, and Scala enable bioinformatics teams and data scientists to explore data with their favorite scripting language while interactive dashboards can be deployed making it easy for business users, clinicians and researchers to review findings.

All of these capabilities are built on an Apache SparkTM-optimized engine that improves the performance of genomic tasks by up to 100x. By unifying these capabilities in a single platform we enable healthcare and life sciences organizations to fully leverage their genomic data to reduce drug development timelines and deliver on precision care initiatives.
Getting Started with Unified Analytics for Genomics
The Unified Analytics Platform for Genomics is currently in preview with multiple Databricks customers. The platform will be generally available on Databricks Azure and AWS later this year, but if you’re interested in participating in the preview, please sign up on the product page www.databricks.com/genomics and we will be in touch!
Conclusion
While genomic data has become widely available over the last decade, the processing and downstream analytics required to turn these massive datasets into life changing insight has become the new bottleneck. With the Databricks Unified Analytics Platform for Genomics, we’ve made significant leaps in addressing these challenges. Instead of wrestling with complex pipelines and reducing the scope of research due to rigid tools, healthcare and life sciences organizations can now accelerate critical discovery with a single, collaborative platform for genomic data processing, tertiary analytics and AI at massive scale.
Try it!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.