Build a Mobile Gaming Events Data Pipeline with Databricks Delta
How to build an end-to-end data pipeline with Structured Streaming
Try this notebook in Databricks
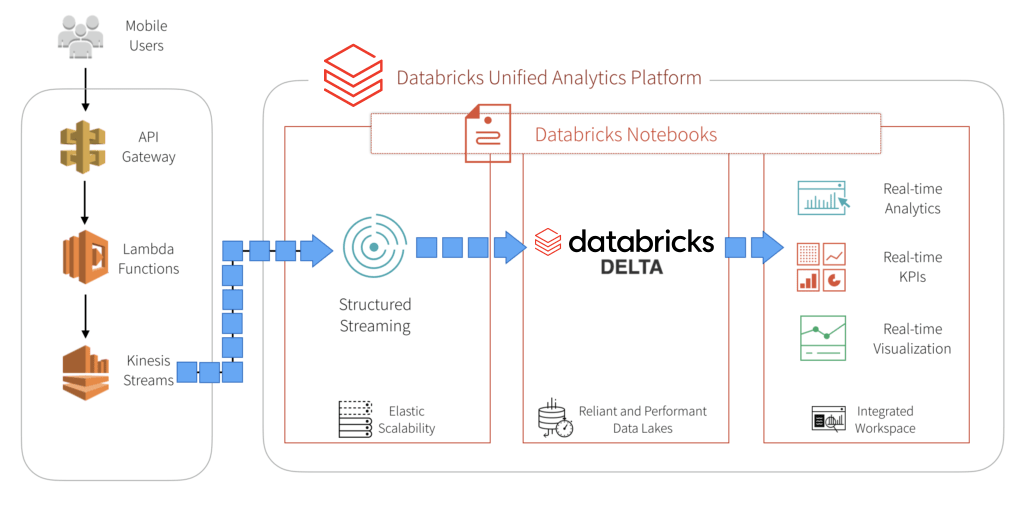
The world of mobile gaming is fast paced and requires the ability to scale quickly. With millions of users around the world generating millions of events per second by means of game play, you will need to calculate key metrics (score adjustments, in-game purchases, in-game actions, etc.) in real-time. Just as important, a popular game launch or feature will increase event traffics by orders of magnitude and you will need infrastructure to handle this rapid scale.
With complexities of low-latency insights and rapidly scalable infrastructure, building data pipelines for high volume streaming use cases like mobile game analytics can be complex and confusing. Developers who are tasked with this endeavor will encounter a number architectural questions.
- First, what set of technologies they should consider that will reduce their learning curve and that integrate well?
- Second, how scalable will the architecture be when built?
- And finally, how will different personas in an organization collaborate?
Ultimately, they will need to build an end-to-end data pipeline comprises of these three functional components: data ingestion/streaming; data transformation (ETL); and data analytics and visualization.
One approach to address these questions is by selecting a unified platform that offers these capabilities. Databricks provides a Unified Analytics Platform that brings together big data and AI and allows the different personas of your organization to come together and collaborate in a single workspace.
In this blog, we will explore how to:
- Build a mobile gaming data pipeline using AWS services such as API Gateway, Lambda, and Kinesis Streams
- Build a stream ingestion service using Spark Structured Streaming
- Use Databricks Delta Lake as a sink for our streaming operations
- Explore how analytics can be performed directly on this table, minimizing data latency
- Illustrate how Databricks Delta solves traditional issues with streaming data
High Level Infrastructure Components
Building mobile gaming data pipelines is complicated by the fact that you need rapidly scalable infrastructure to handle millions of events by millions of users and gain actionable insights in real-time. That’s where the beauty of building a data pipeline with AWS and Databricks comes into play. Kinesis shards can be dynamically re-provisioned to handle increased loads, and Databricks automatically scales out your cluster to handle the increase in data.
In our example, we simulate game play events from mobile users with an event generator. These events are pushed to a REST endpoint and follow our data pipeline through ingestion into our Databricks Delta table. The code for this event generator can be found here.
Amazon API Gateway, Lambda, and Kinesis Streams
For this example, we build a REST endpoint using Amazon API Gateway. Events that arrive at this endpoint automatically trigger a serverless lambda function, which pipes these events into a Kinesis stream for our consumption. You will want to setup lambda integration with your endpoint to automatically trigger, and invoke a function that will write these events to kinesis.
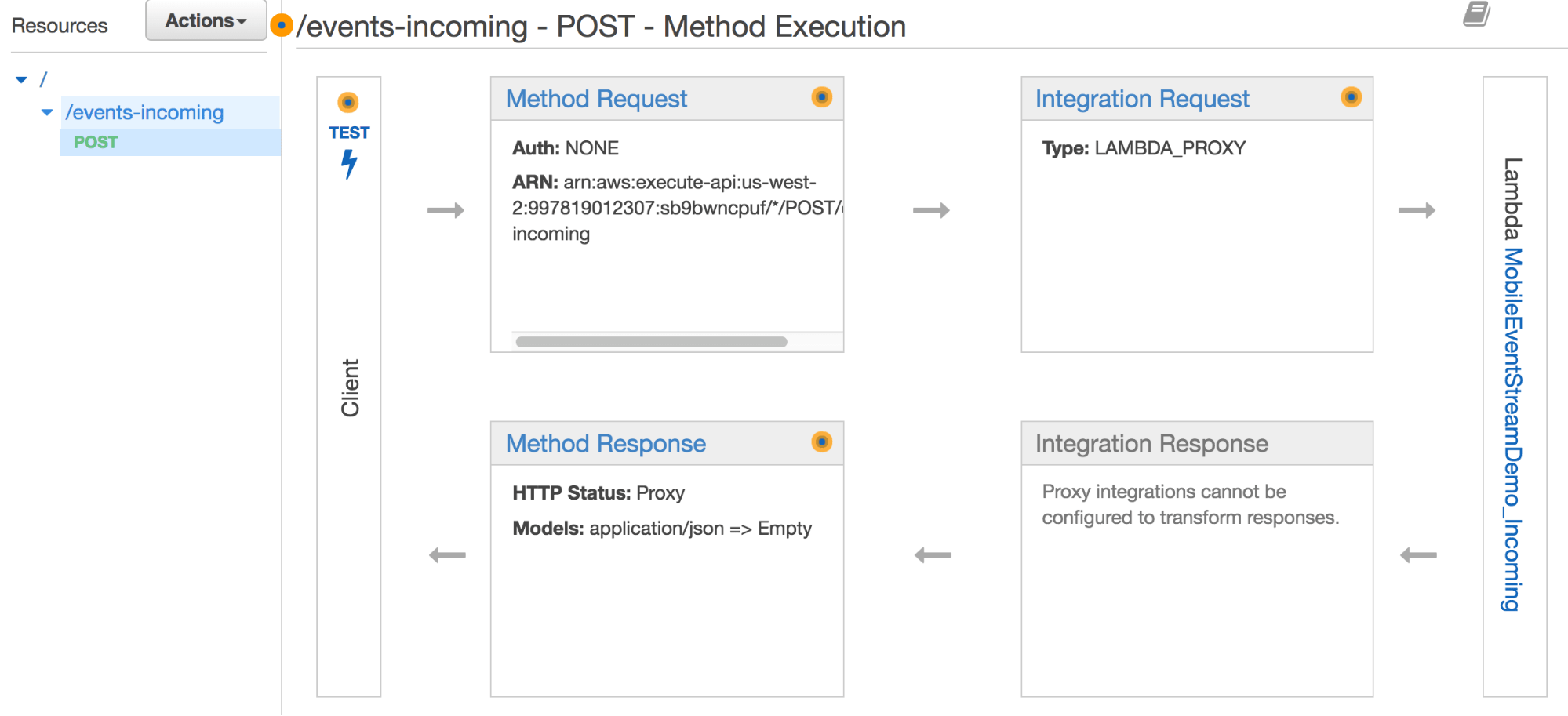

Setup a Python lambda function like so:
Kinesis streams are provisioned by throughput, so you can provision as many shards as necessary to handle your expected data throughput. Each shard provides a throughput of 1 MB/sec for writes and 2MB/sec for reads, or up to 1000 records per second. For more information regarding Kinesis streams throughput, check out the documentation. Random PartitionKeys are important for even distribution if you have more than one shard.
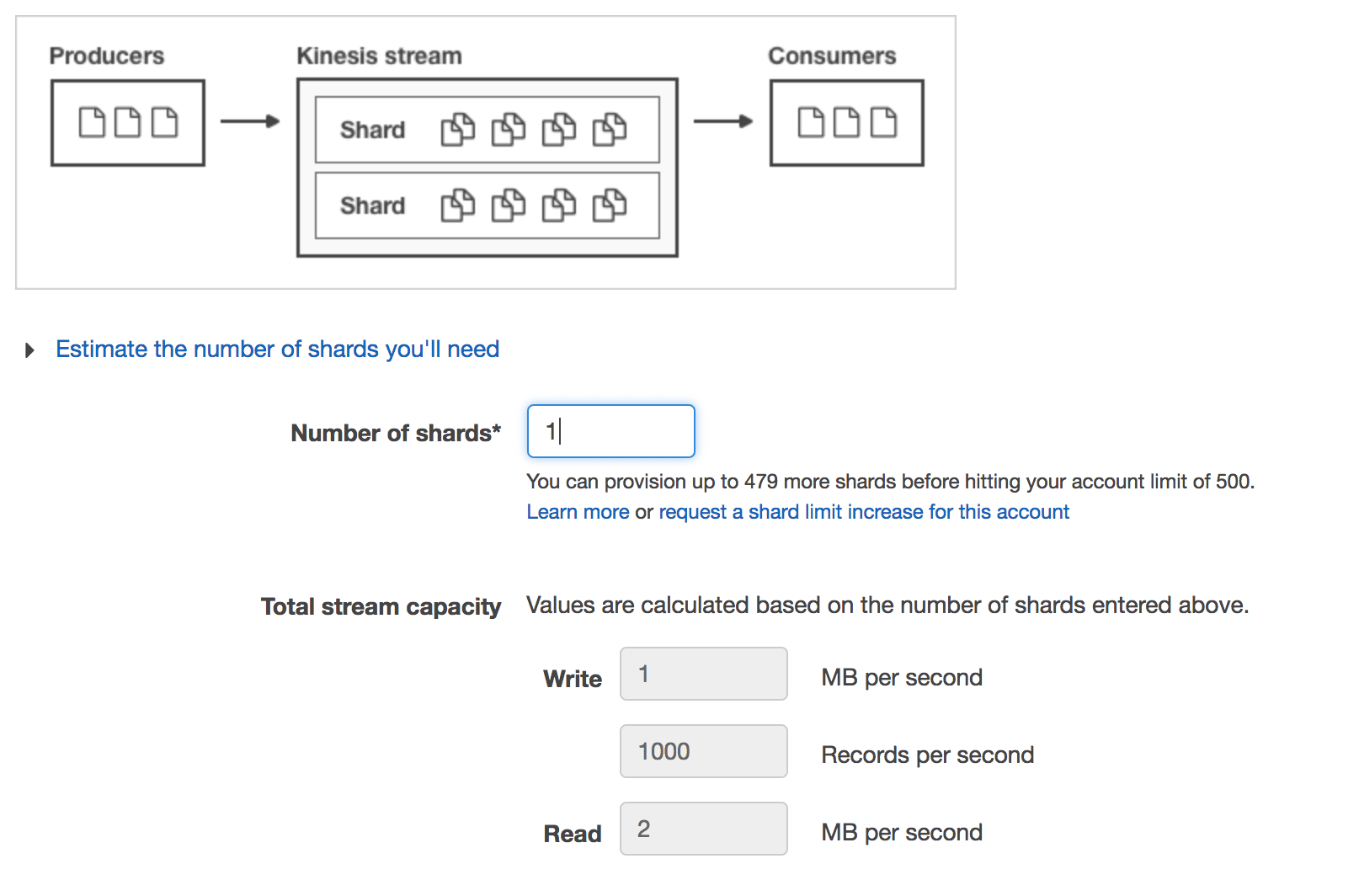
Ingesting from Kinesis using Structured Streaming
Ingesting data from a Kinesis stream is straight forward. In a production environment, you will want to setup the appropriate IAM role policies to make sure your cluster has access to your Kinesis Stream. The minimum permissions for this look like this:
Alternatively, you can also use AWS access keys and pass them in as options, however, IAM roles are best practice method for production use cases. In this example, let’s assume the cluster has the appropriate IAM role setup.
Start by creating a DataFrame like this:
You’ll want to also define the schema of your incoming data. Kinesis data gets wrapped like so:
For this demo, we’re really only interested in the body of the kinesisSchema, which will contain data that we describe in our eventSchema.
Real-time Data Pipelines Using Databricks Delta
Now that we have our streaming dataframe defined, let’s go ahead and do some simple transformations. Event data is usually time-series based, so it’s best to partition on something like an event date. Our incoming stream does not have an event date parameter, however, so we’ll make our own by transforming the eventTime column. We’ll also throw in a check to make sure the eventTime is not null:
Let’s also take this opportunity to define our table location.
Real-time Analytics, KPIs, and Visualization
Now that we have data streaming live into our Databricks Delta table, we can go ahead and look at some KPIs. Traditionally, companies would only look at these on a daily basis, but with Structured Streaming and Databricks Delta, you have the capability to visualize these in real time all within your Databricks notebooks.
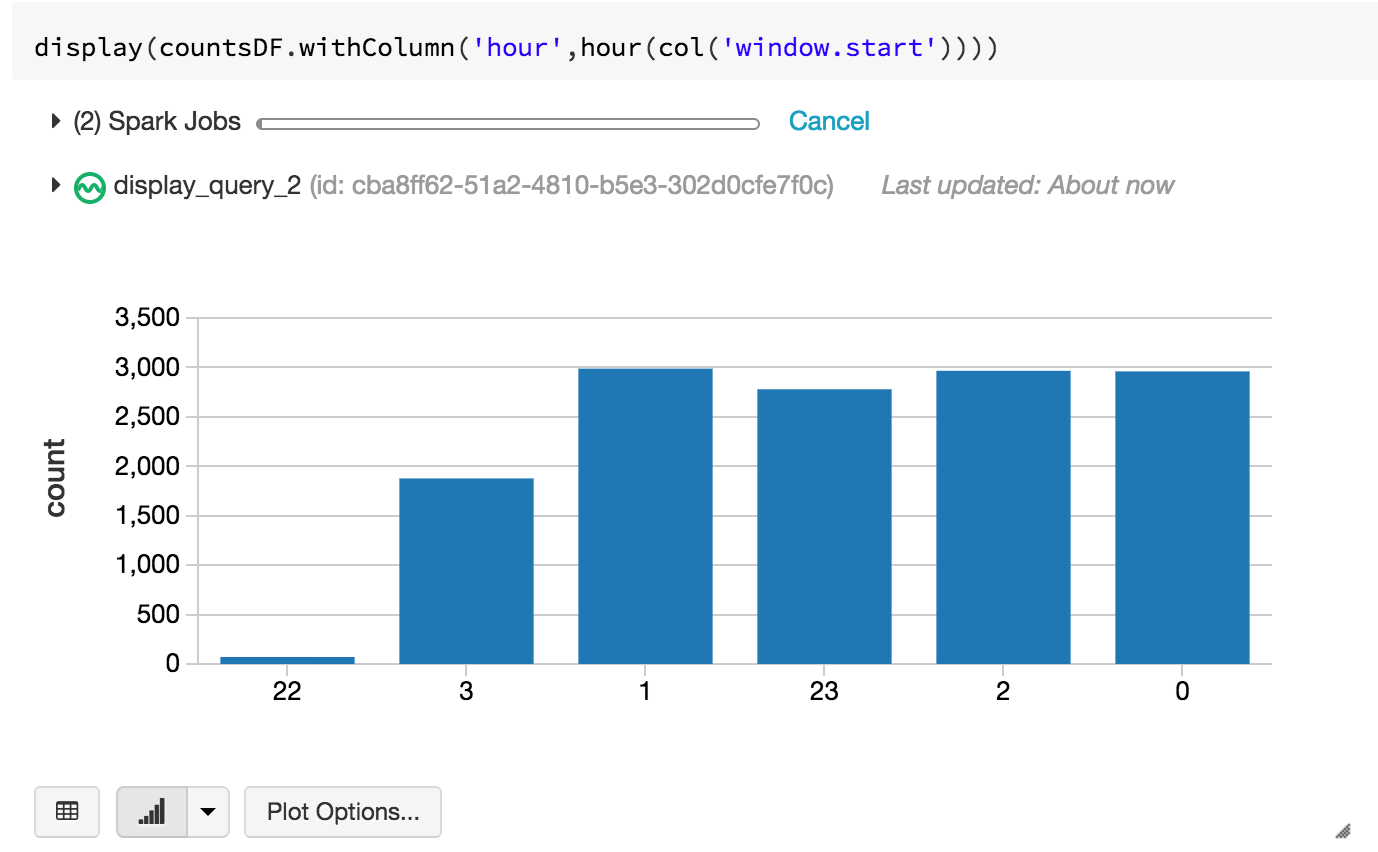
Let’s start with a simple one. How many events have I seen in the last hour?
We can then visualize this in our notebook as say, a bar graph:
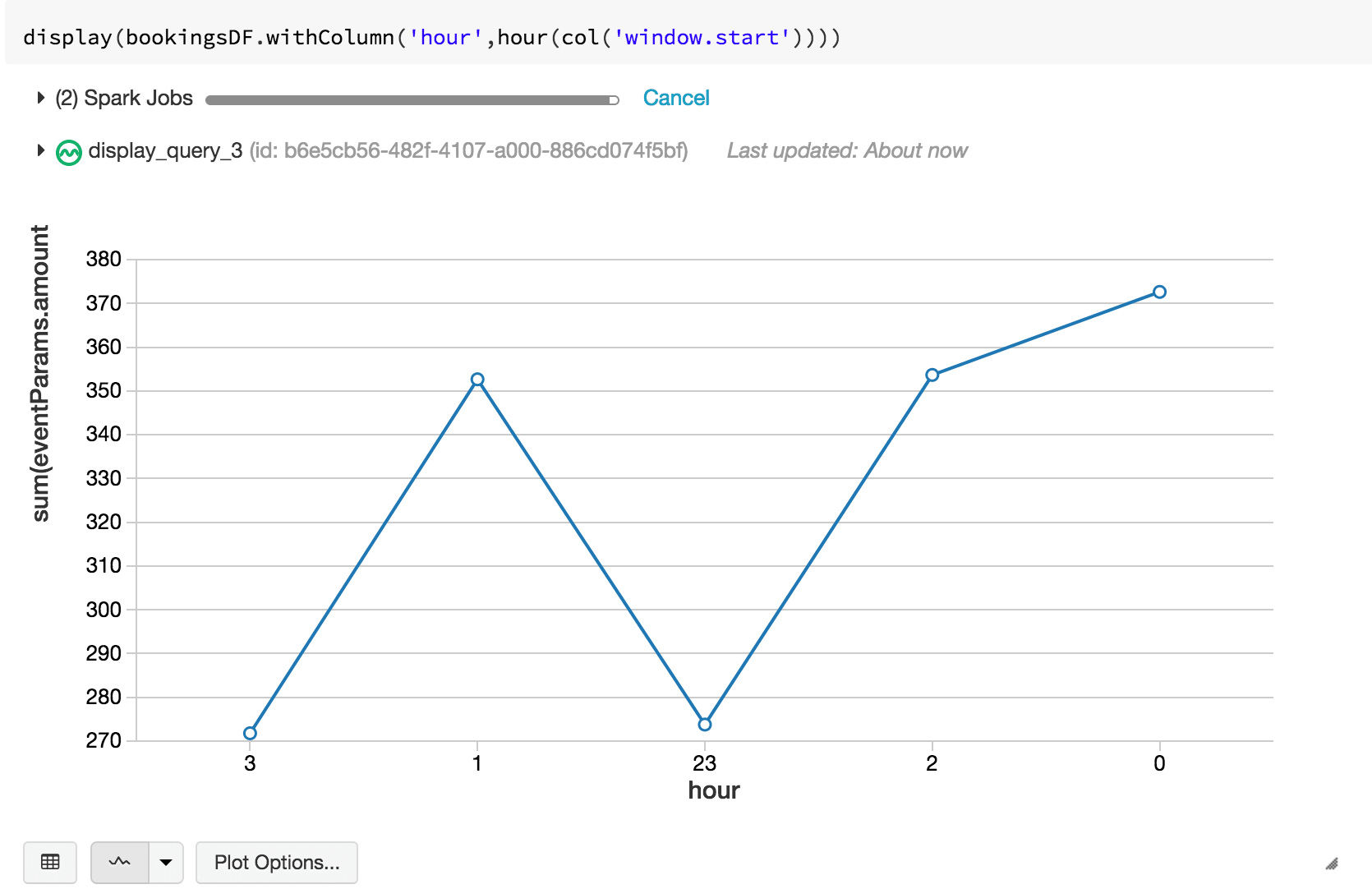
Maybe we can make things a little more interesting. How much money have I made in the last hour? Let’s examine bookings. Understanding bookings per hour is an important metric because it can be indicative of how our application/production systems are doing. If there was a sudden drop in bookings right after a new game patch was deployed, for example, we immediately know something is wrong.
We can take the same dataframe, but filter on all purchaseEvents, grouping by a window of 60 minutes.
Let’s pick a line graph to visualize this one:
For the SQL enthusiasts, you can query the Databricks Delta table directly. Let’s take a look at a simple query to show the current daily active users (DAU). I know we’re actually looking at device id because our sample set doesn’t contain a user id, so for the sake of example, let’s assume that there is a 1-1 mapping between users and devices (although, in the real world, this is not always the case).
Solving the Traditional Streaming “Small Files” Problem with Databricks Delta
A common challenge that many face with streaming is the classic “small files” problem. Depending on how frequently your writes are being triggered and the volume of the traffic that you are ingesting, you may end up with a lot of files that are of varying sizes, many of them too small to be operationally efficient.
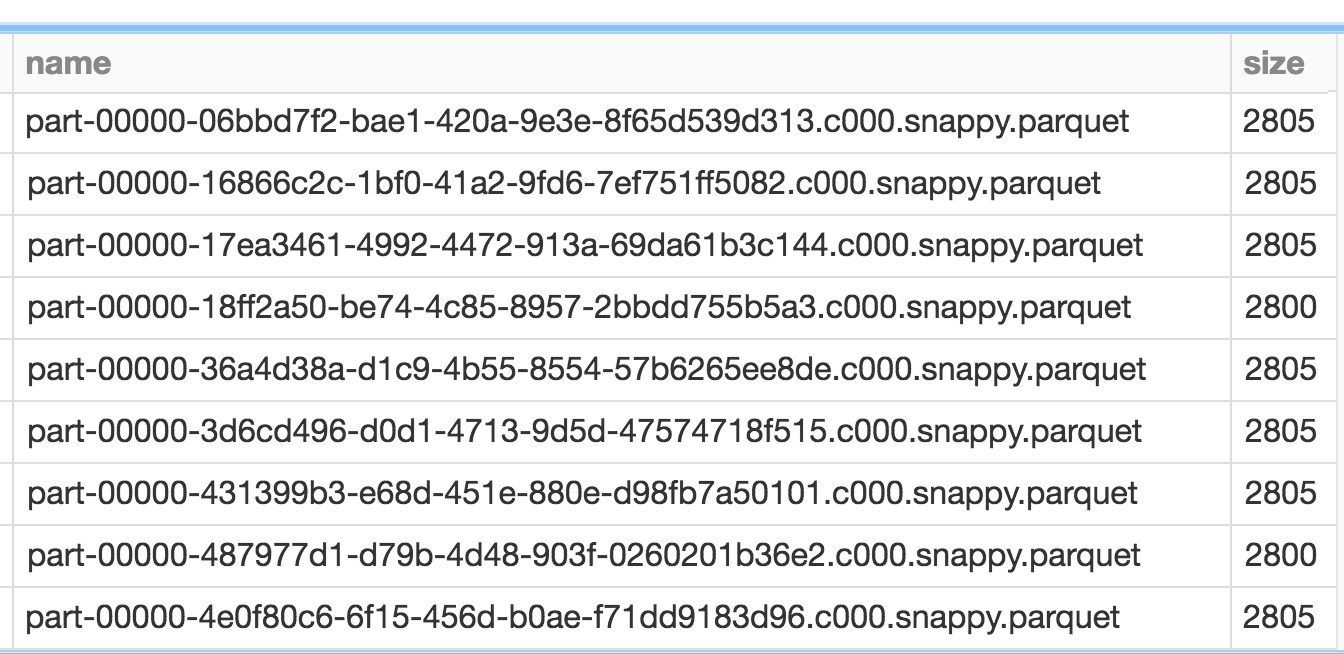
Databricks Delta solves this issue by introducing the OPTIMIZE command. This command effectively performs compaction on these files so that you have larger (up to 1GiB) files.
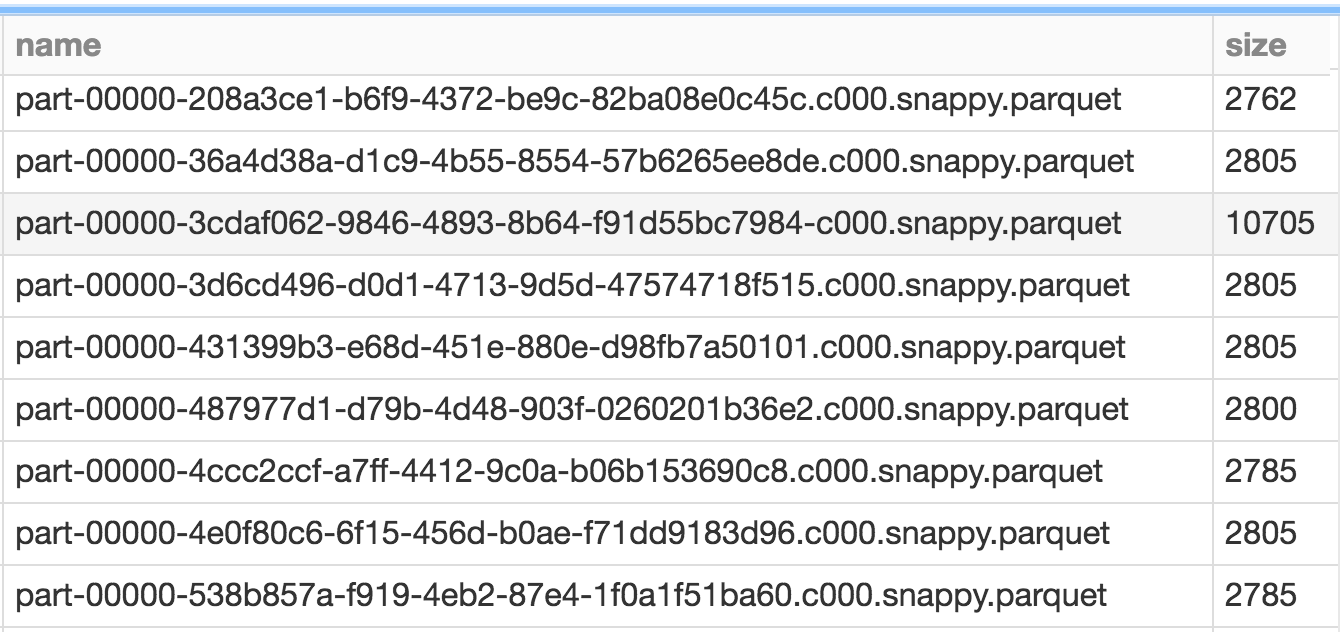
You’ll notice, however, that there are still a bunch of small files. That’s because Databricks Delta manages transactions. You might have queries or longer running processes that are still accessing your older files, after your compaction completes. Any new queries or jobs submitted at this time end up accessing the newer, larger files, but any existing jobs would still query the older files.
You can clean these up periodically by calling the VACUUM command.
Which results simply with:

By default VACUUM removes files that are older than 7 days. But you can manually set your own retention by specifying a RETENTION clause like so:
It’s highly recommended that you do not set the retention to zero hours, unless you are absolutely certain that no other processes are writing to or reading from your table.
Summary
In closing, we demonstrated how to build a data pipeline’s three functional components using the Databricks Unified Analytics Platform: Spark Structured Streaming, and Databricks Delta, and Databricks Notebooks. We’ve illustrated different ways that you can extrapolate key performance metrics from this real-time streaming data, as well as solve issues that are traditionally associated with streaming. The combination of Spark Structured Streaming and Databricks Delta reduces the overall end-to-end latency and availability of data, enabling data engineering, data analytics, and data science teams to respond quickly to events like a sudden drop in bookings, or an increased error-message events, that have direct impact on revenue. Additionally, by removing the data engineering complexities commonly associated with such pipelines with the Databricks Unified Analytics Platform, this enables data engineering teams to focus on higher-value projects.
To understand more about this specific example, I’ve included some resources below, as well as a notebook for you to try on your own.
Read More
For more information on Databricks Delta, Structured Streaming, and notebooks, read these sources
- Databricks Delta Guide
- Databricks Guide: Structured Streaming
- An Anthology of Technical Assets on Apache Spark’s Structured Streaming
- Streaming Mobile Game Events Notebook
Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.