Simplify Streaming Stock Data Analysis Using Databricks Delta
by John O'Dwyer and Denny Lee
Traditionally, real-time analysis of stock data was a complicated endeavor due to the complexities of maintaining a streaming system and ensuring transactional consistency of legacy and streaming data concurrently. Databricks Delta Lake helps solve many of the pain points of building a streaming system to analyze stock data in real-time.
In the following diagram, we provide a high-level architecture to simplify this problem. We start by ingesting two different sets of data into two Databricks Delta tables. The two datasets are stocks prices and fundamentals. After ingesting the data into their respective tables, we then join the data in an ETL process and write the data out into a third Databricks Delta table for downstream analysis.
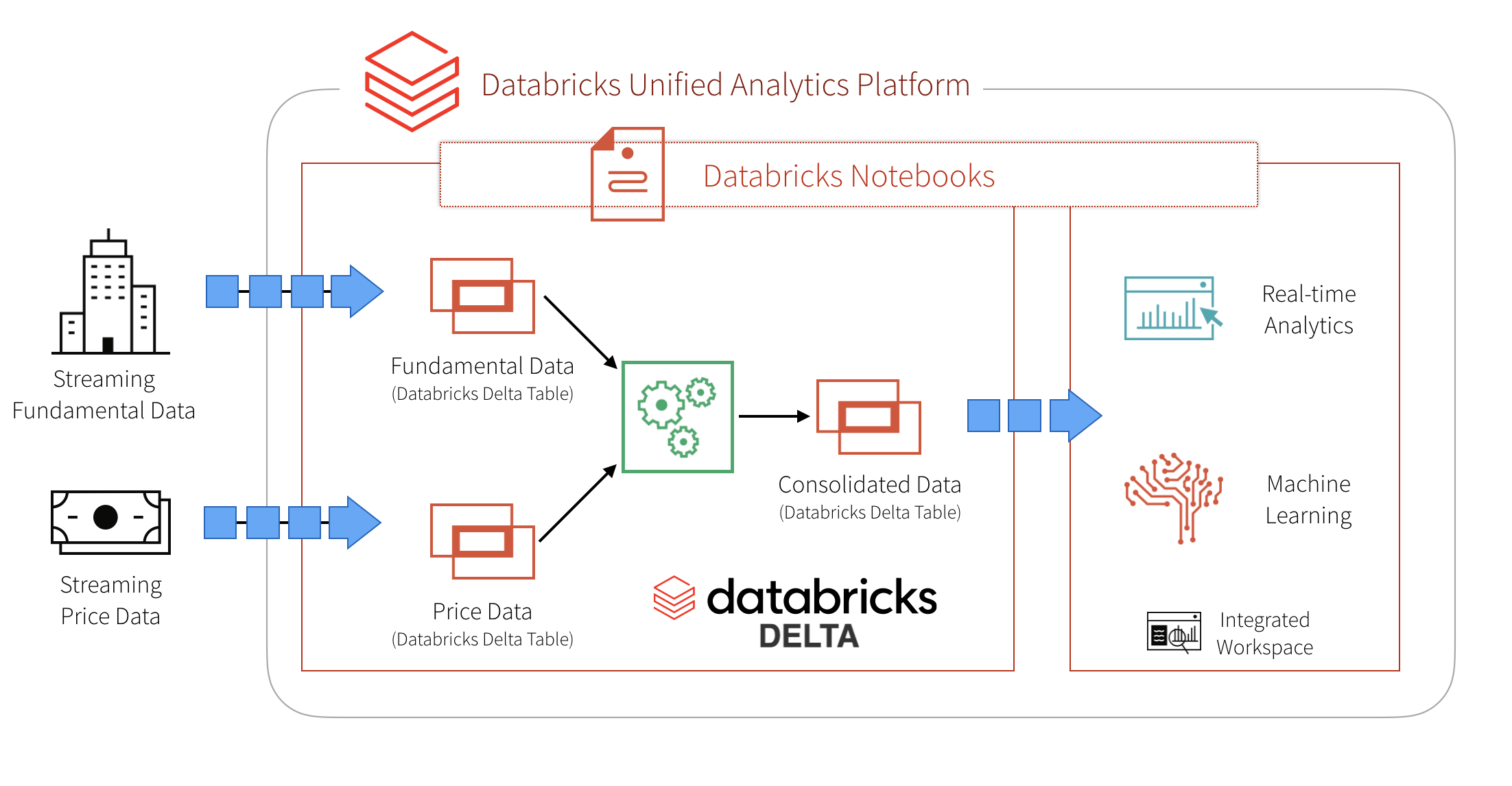
In this blog post we will review:
- The current problems of running such a system
- How Databricks Delta addresses these problems
- How to implement the system in Databricks
Databricks Delta helps solve these problems by combining the scalability, streaming, and access to advanced analytics of Apache Spark with the performance and ACID compliance of a data warehouse.
Traditional pain points prior to Databricks Delta
The pain points of a traditional streaming and data warehousing solution can be broken into two groups: data lake and data warehouse pains.
Data Lake Pain Points
While data lakes allow you to flexibly store an immense amount of data in a file system, there are many pain points including (but not limited to):
- Consolidation of streaming data from many disparate systems is difficult.
- Updating data in a Data Lake is nearly impossible and much of the streaming data needs to be updated as changes are made. This is especially important in scenarios involving financial reconciliation and subsequent adjustments.
- Query speeds for a data lake are typically very slow.
- Optimizing storage and file sizes is very difficult and often require complicated logic.
Data Warehouse Pain Points
The power of a data warehouse is that you have a persistent performant store of your data. But the pain points for building modern continuous applications include (but not limited to):
- Constrained to SQL queries; i.e. no machine learning or advanced analytics.
- Accessing streaming data and stored data together is very difficult if at all possible.
- Data warehouses do not scale very well.
- Tying compute and storage together makes using a warehouse very expensive.
How Databricks Delta Solves These Issues
Databricks Delta (Databricks Delta Guide) is a unified data management system that brings data reliability and performance optimizations to cloud data lakes. More succinctly, Databricks Delta takes the advantages of data lakes and data warehouses together with Apache Spark to allow you to do incredible things!
- Databricks Delta, along with Structured Streaming, makes it possible to analyze streaming and historical data together at data warehouse speeds.
- Using Databricks Delta tables as sources and destinations of streaming big data make it easy to consolidate disparate data sources.
- Upserts are supported on Databricks Delta tables.
- Your streaming/data lake/warehousing solution has ACID compliance.
- Easily include machine learning scoring and advanced analytics into ETL and queries.
- Decouples compute and storage for a completely scalable solution.
Implement your streaming stock analysis solution with Databricks Delta
Databricks Delta and Apache Spark do most of the work for our solution; you can try out the full notebook and follow along with the code samples below. Let’s start by enabling Databricks Delta; as of this writing, Databricks Delta is in private preview so sign up at https://www.databricks.com/product/delta-lake-on-databricks.
As noted in the preceding diagram, we have two datasets to process - one for fundamentals and one for price data. To create our two Databricks Delta tables, we specify the .format(“delta”) against our DBFS locations.
While we’re updating the stockFundamentals and stocksDailyPrices, we will consolidate this data through a series of ETL jobs into a consolidated view (stocksDailyPricesWFund). With the following code snippet, we can determine the start and end date of available data and then combine the price and fundamentals data for that date range into DBFS.
Now we have a stream of consolidated fundamentals and price data that is being pushed into DBFS in the /delta/stocksDailyPricesWFund location. We can build a Databricks Delta table by specifying .format(“delta”) against that DBFS location.
Now that we have created our initial Databricks Delta table, let’s create a view that will allow us to calculate the price/earnings ratio in real time (because of the underlying streaming data updating our Databricks Delta table).
Analyze streaming stock data in real time
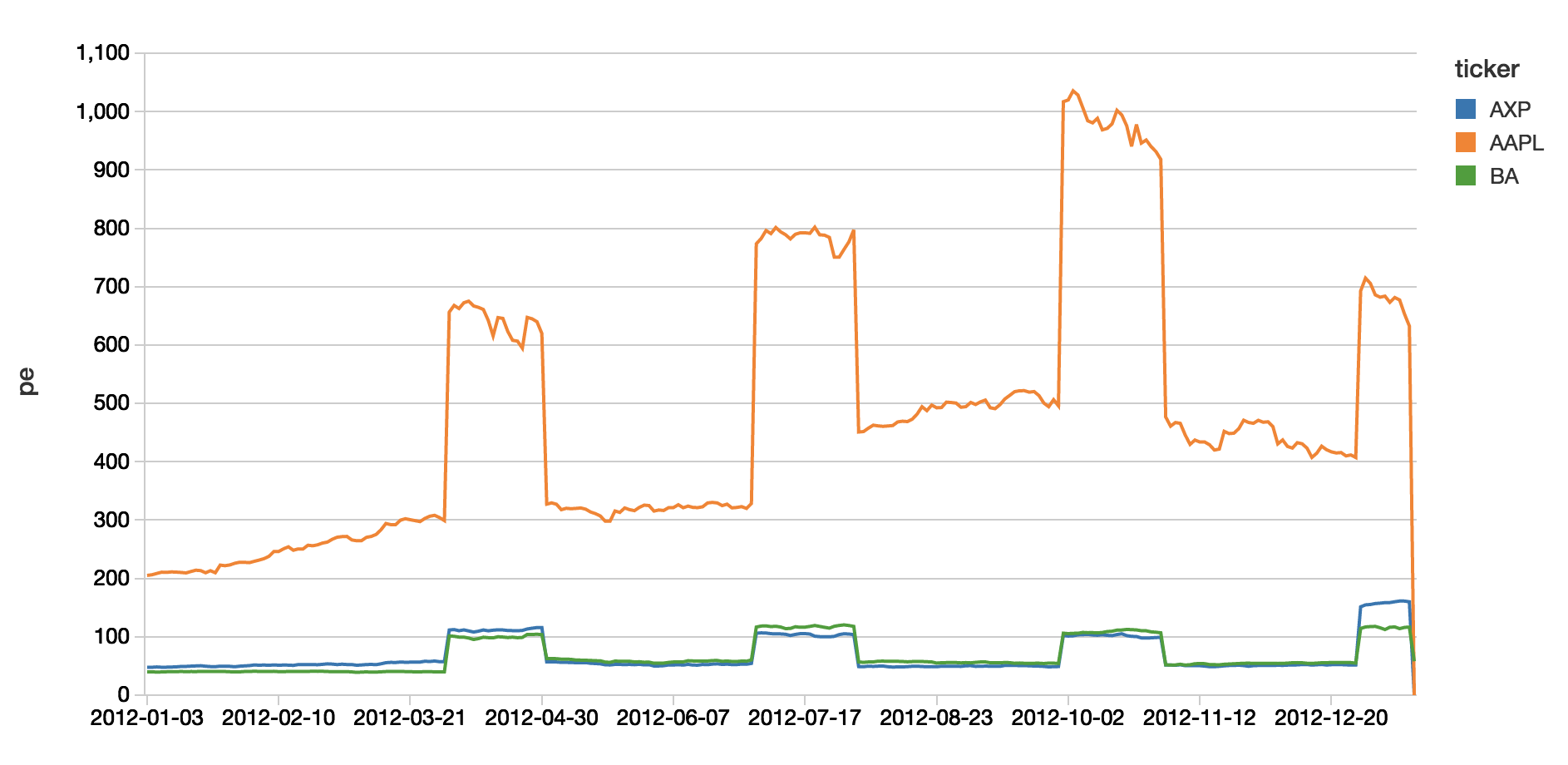
With our view in place, we can quickly analyze our data using Spark SQL.
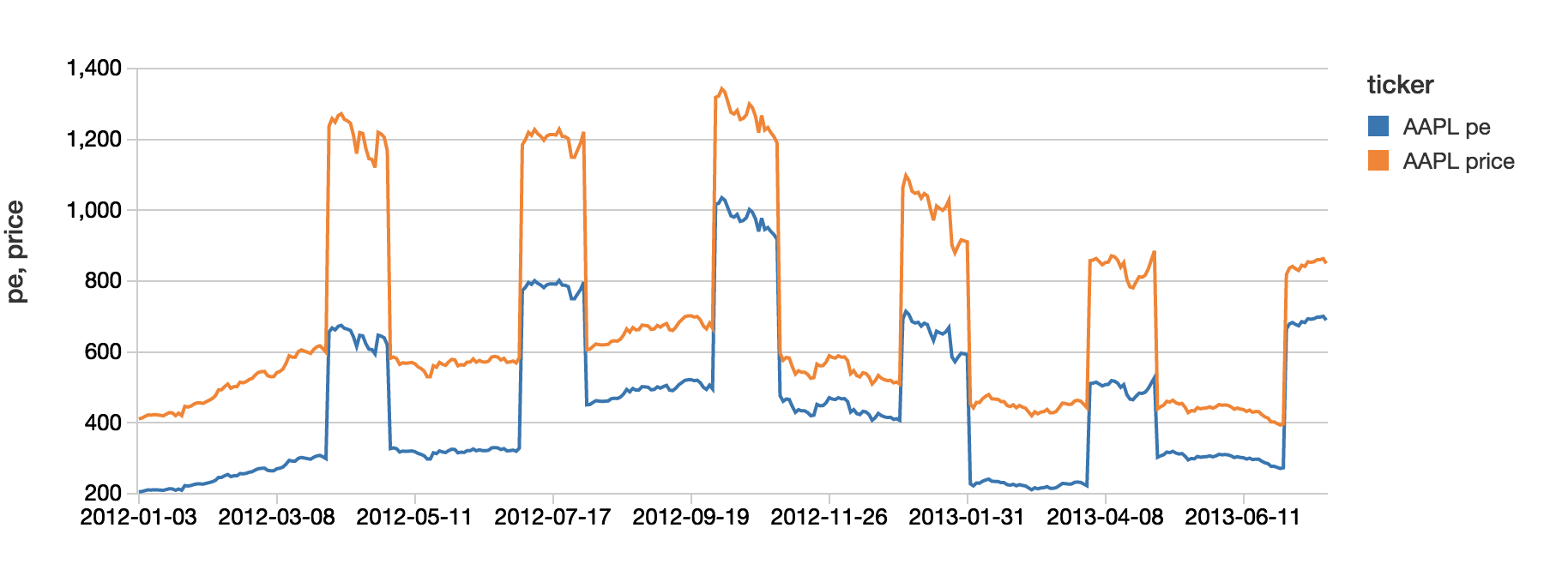
As the underlying source of this consolidated dataset is a Databricks Delta table, this view isn’t just showing the batch data but also any new streams of data that are coming in as per the following streaming dashboard.
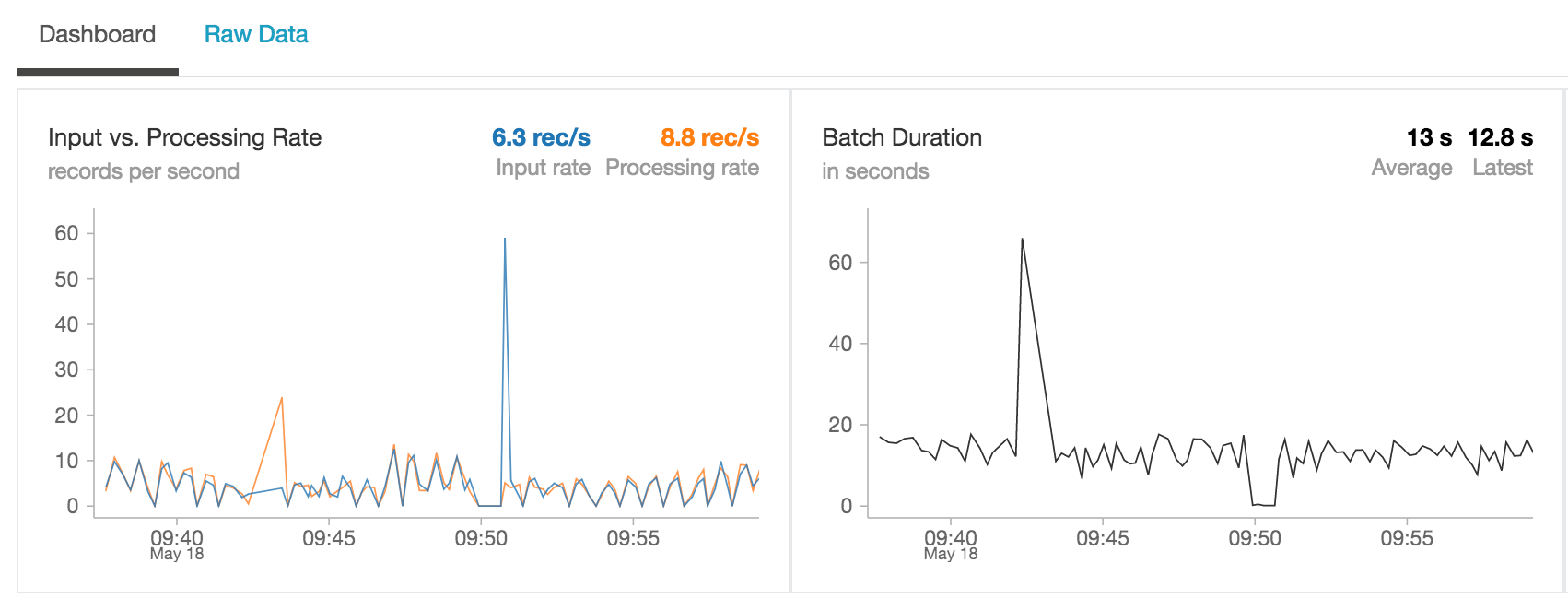
Underneath the covers, Structured Streaming isn’t just writing the data to Databricks Delta tables but also keeping the state of the distinct number of keys (in this case ticker symbols) that need to be tracked.
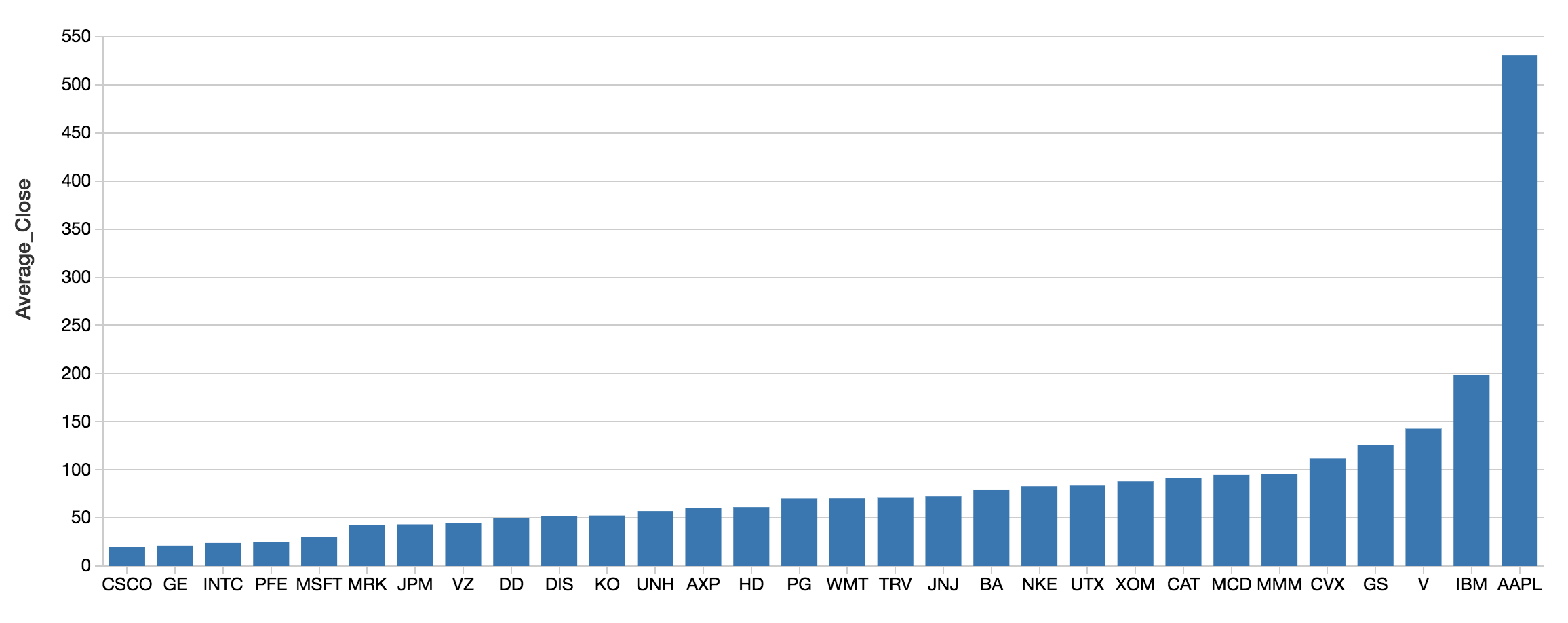
Because you are using Spark SQL, you can execute aggregate queries at scale and in real-time.
Summary
In closing, we demonstrated how to simplify streaming stock data analysis using Databricks Delta Lake. By combining Spark Structured Streaming and Databricks Delta, we can use the Databricks integrated workspace to create a performant, scalable solution that has the advantages of both data lakes and data warehouses. The Databricks Unified Analytics Platform removes the data engineering complexities commonly associated with streaming and transactional consistency enabling data engineering and data science teams to focus on understanding the trends in their stock data.
Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.