Introducing Cluster-scoped Init Scripts
This summer, I worked at Databricks as a software engineering intern on the Clusters team. As part of my internship project, I designed and implemented Cluster-scoped init scripts, improving scalability and ease of use.
In this blog, I will discuss various benefits of Cluster-scoped init scripts, followed by my internship experience at Databricks, and the impact it had on my personal and professional growth.
Cluster-scoped Init Scripts
Init scripts are shell scripts that run during the startup of each cluster node before the Spark driver or worker JVM starts. Databricks customers use init scripts for various purposes such as installing custom libraries, launching background processes, or applying enterprise security policies. These new scripts offer several improvements over previous ones, which are now deprecated.
Init scripts are now part of the cluster configuration
One of the biggest pain points for customers used to be that init scripts for a cluster were not part of the cluster configuration and did not show up in the User Interface. Because of this, applying init scripts to a cluster was unintuitive, and editing or cloning a cluster would not preserve the init script configuration. Cluster-scoped init scripts addressed this issue by including an ‘Init Scripts’ panel in the UI of the cluster configuration page, and adding an ‘init_scripts’ field to the public API. This also allows init scripts to take advantage of cluster access control.
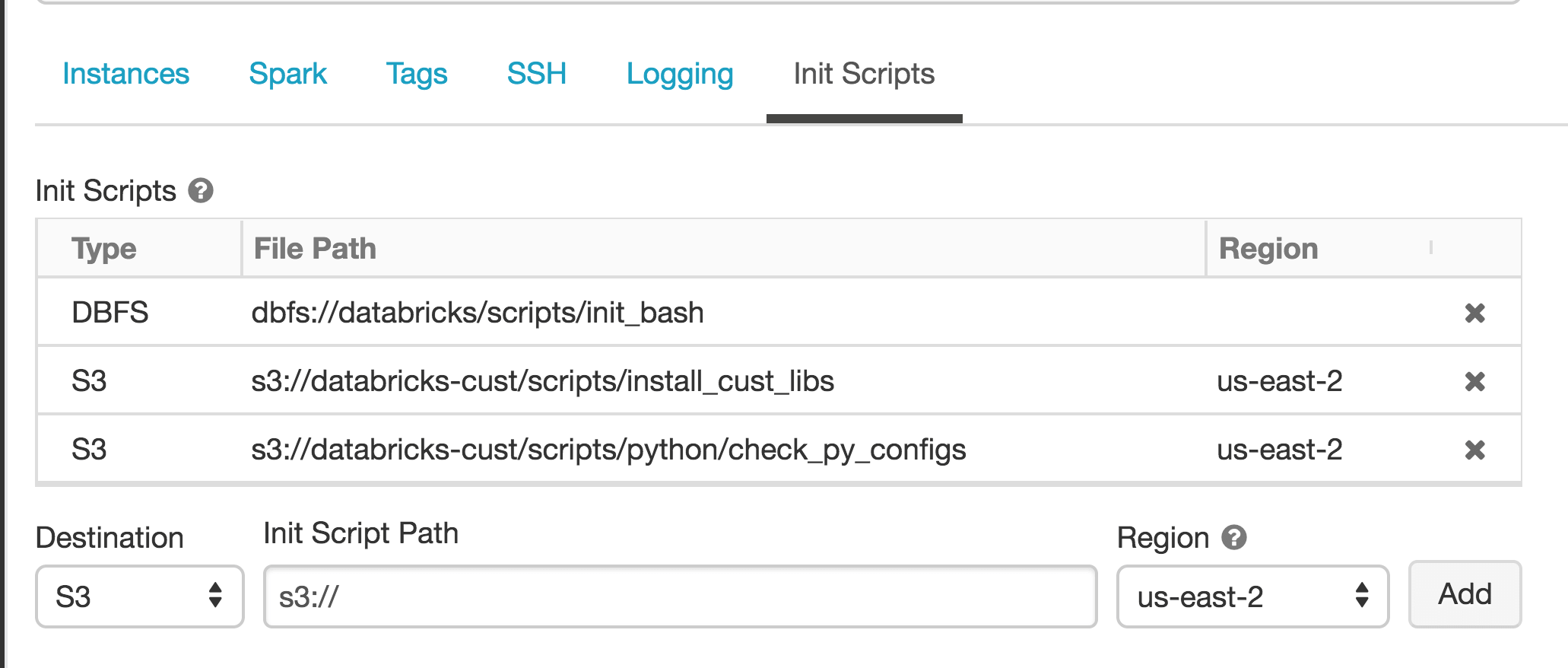
Init scripts now work for jobs clusters
Previous init scripts depended on storing the scripts in a folder with the cluster-name. This prevents them from being used in jobs clusters, where cluster names are generated on the fly. Since Cluster-scoped init scripts are part of the cluster configuration, they can be applied to jobs clusters as wel, with an identical interface via both the UI and API.
Environment variables for init scripts
Init scripts now provide access to certain environment variables that are listed here. This reduces the complexity of many init scripts that require access to information such as whether the node is a driver or executor and the cluster id.
Access Control for init scripts
Users can now provide a DBFS or S3 path for their init scripts, which can be stored at arbitrary locations. When using S3, IAM roles can be used to provide access control for init scripts, protecting against malicious or mistaken access/alteration to the init scripts. Read more details on how to set this up here.
Simplified logging
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and can be found in the same root folder as driver and executor logs for the cluster.
Additional cluster events
Init Scripts now expose two new cluster events: INIT_SCRIPTS_STARTED and INIT_SCRIPTS_FINISHED. These help users determine the duration of init scripts execution and provide additional clarity as to the state of the cluster at a given moment.
Conclusion
Working on this project exposed me to the process of designing, implementing and testing a customer-facing feature. I learned how to write robust, maintainable code and evaluate execution semantics. I remember my distributed systems professor claiming that a good design can simplify engineering effort by orders of magnitude, resulting in shorter, cleaner code that is less prone to bugs. However, I never imagined that this point would be driven home just a few months later in an industry setting.
I found Databricks engineers to be extremely helpful, with a constant desire to learn and improve, as well as the patience to teach. The leadership is extremely open with the employees and is constantly looking for feedback, even from the interns. The internship program also had a host of fun activities, as well as educational events that allowed us to learn about other areas of the company (e.g., sales, field engineering, customer success).
Finally, I’d like to thank the clusters team for their encouragement and support throughout my project. A special shout out to my manager Ihor Leshko for always being there when needed, Mike Lin for completely changing the way I approach front-end engineering, and my mentor Haogang Chen for teaching me valuable technical skills that enabled me to graduate from writing simple, working code to building robust, production-ready systems.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.