Apache Avro as a Built-in Data Source in Apache Spark 2.4
Try this notebook in Databricks
Apache Avro is a popular data serialization format. It is widely used in the Apache Spark and Apache Hadoop ecosystem, especially for Kafka-based data pipelines. Starting from Apache Spark 2.4 release, Spark provides built-in support for reading and writing Avro data. The new built-in spark-avro module is originally from Databricks’ open source project Avro Data Source for Apache Spark (referred to as spark-avro from now on). In addition, it provides:
- New functions from_avro() and to_avro() to read and write Avro data within a DataFrame instead of just files.
- Avro logical types support, including Decimal, Timestamp, and Date types. See the related schema conversions for details.
- 2X read throughput improvement and 10% write throughput improvement.
In this blog, we examine each of the above features through examples, giving you a flavor of its easy API usage, performance improvements, and merits.
Load and Save Functions
In Apache Spark 2.4, to load/save data in Avro format, you can simply specify the file format as “avro” in the DataFrameReader and DataFrameWriter. For consistency and familiarity, the usage is similar to other data sources.
Power of from_avro() and to_avro()
To further simplify your data transformation pipeline, we introduced two new built-in functions: from_avro() and to_avro(). Avro is commonly used to serialize/deserialize the messages/data in Apache Kafka-based data pipeline. Using Avro records as columns is useful when reading from or writing to Kafka. Each Kafka key-value record is augmented with some metadata, such as the ingestion timestamp into Kafka, the offset in Kafka, etc.
There are three instances where these functions are useful:
- When Spark reads Avro binary data from Kafka, from_avro() can extract your data, clean it, and transform it.
- When you want to transform your structs into Avro binary records and then push them downstream to Kafka again or write them to a file, use to_avro().
- When you want to re-encode multiple columns into a single one, use to_avro().
Both functions are available only in Scala and Java.
For more examples, see Read and Write Streaming Avro Data with DataFrames.
Compatibility with Databricks spark-avro
The built-in spark-avro module is compatible with the Databricks’ open source repository spark-avro.
To read/write the data source tables that were previously created using com.databricks.spark.avro, you can load/write these same tables using this built-in Avro module, without any code changes. In fact, if you prefer to using your own build of a spark-avro jar file, you can simply disable the configuration spark.sql.legacy.replaceDatabricksSparkAvro.enabled, and use the option --jars when deploying your applications. Read the Advanced Dependency Management section in the Application Submission Guide for more details.
Performance Improvement
With the IO optimization of SPARK-24800, the built-in Avro data source achieves performance improvement on both reading and writing Avro files. We conducted a few benchmarks and observed 2x performance in reads, while an 8% improvement in writes.
Configuration and Methodology
We ran the benchmark on a single node Apache Spark cluster on Databricks Community edition. For the detailed implementation of the benchmark, check the Avro benchmark notebook.
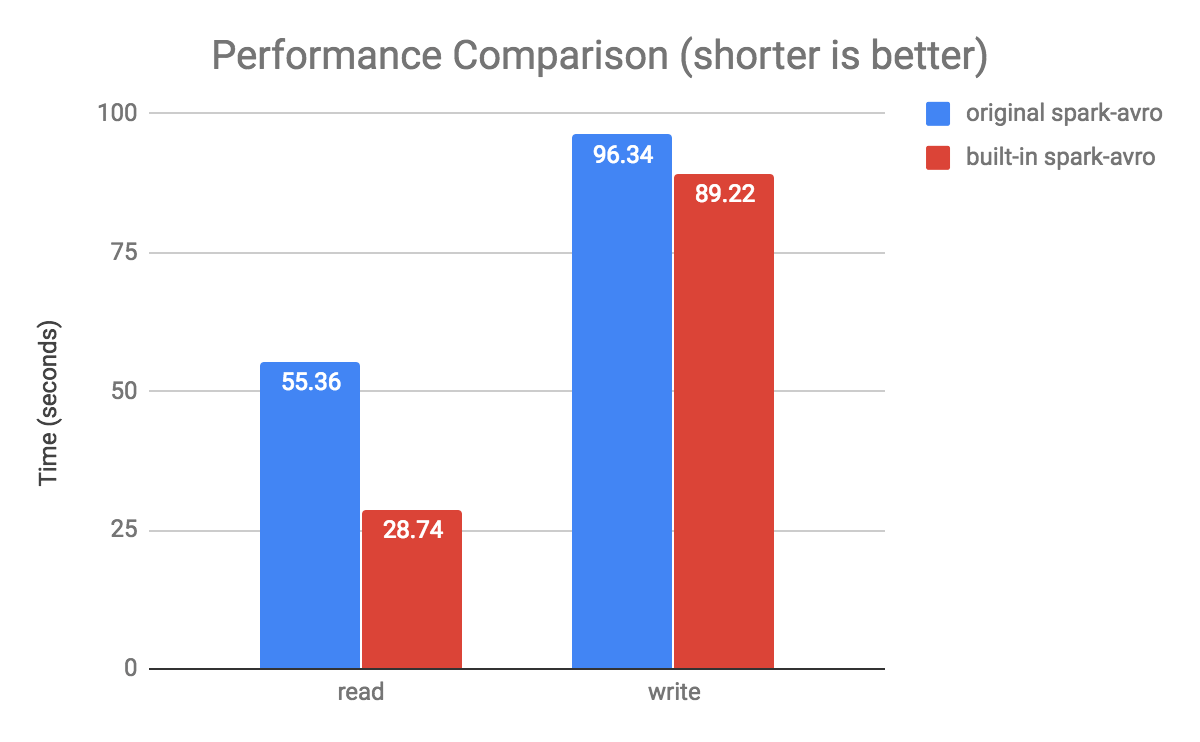
As shown in the charts, the read performance is almost 2 times faster, and the write performance also has an 8% improvement.
Configuration details:
- Data: A 1M-row DataFrame with columns of various types: Int/Double/String/Map/Array/Struct, etc.
- Cluster: 6.0 GB Memory, 0.88 Cores, 1 DBU
- Databricks runtime version: 5.0 (with new built-in spark-avro) and 4.0 (with external Databricks spark-avro library)
Conclusion
The new built-in spark-avro module provides better user experience and IO performance in Spark SQL and Structured Streaming. The original spark-avro will be deprecated in favor of the new built-in support for Avro in Spark itself.
You can try the Apache Spark 2.4 release with this package on Databricks Runtime 5.0 today. To learn more about how to use Apache Avro in the cloud for structured streaming, read our documentation on Azure Databricks or AWS.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.