Near-Real-Time Hardware Failure Rate Estimation with Bayesian Reasoning
by Sean Owen
Try this notebook in Databricks
You might be using Bayesian techniques in your data science without knowing it! And if you're not, then it could enhance the power of your analysis. This blog follows the introduction to Bayesian reasoning on Data Science Central, and will demonstrate how these ideas can improve a real-world use case: estimating hard drive failure rate from a source of streaming sensor data. When you’re caught up on what these techniques can do for you, read on!
Use Case: Hard Drive Failure
You have telemetry from your data center’s hard drives, including drive model and failures. You’d like to understand which drives have an unusually high failure rate.
The kind people at Backblaze have provided just this kind of data from several years of operating data centers. The data is broken down by individual drive and by day, and has rich information from SMART sensor readings, but we’ll just use the drive model and whether it failed on a given day. Take the Q2 and Q3 2018 data as an example; download the archives of CSV files and unpack to a shared location.
As above, the most straightforward thing to do is find the failure rate by model, and take that as the best estimate of actual failure rate. The top 6 drives by failure rate (note: here the rate is annualized to failure rate per year, for readability) are:
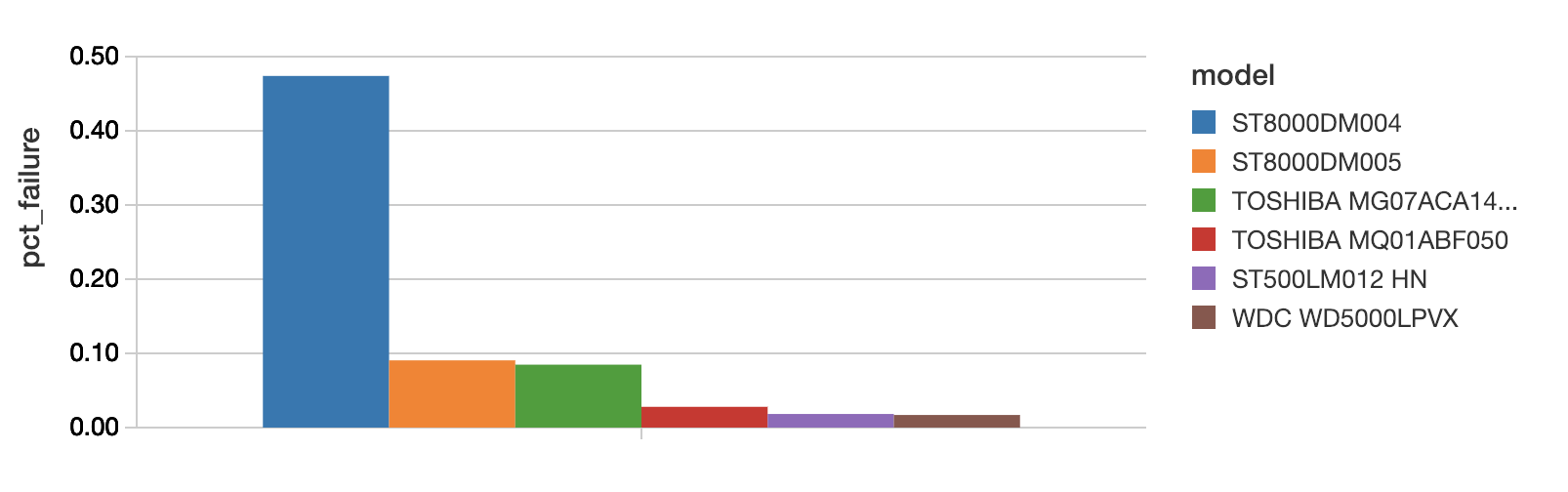
(In Databricks, just use the plot options in the cell output to switch from a table view of these results to the histogram above.) The ST8000DM004 looks like it has a high failure rate of almost 0.5% per year, but, how sure are we that it has not just experienced an unfortunately high string of failures in Q2 and Q3?
Assuming a constant true failure rate λ, the number of failures per time follows a Poisson distribution, Poisson(λ), just as the number of heads above followed a binomial distribution. Also as above, we’d instead like to understand the distribution of the failure rate λ. It follows a gamma distribution with parameters ɑ and β. As with the beta distribution, they have a convenient interpretation. After seeing f failures in t days, the distribution of λ is Gamma(f,t).
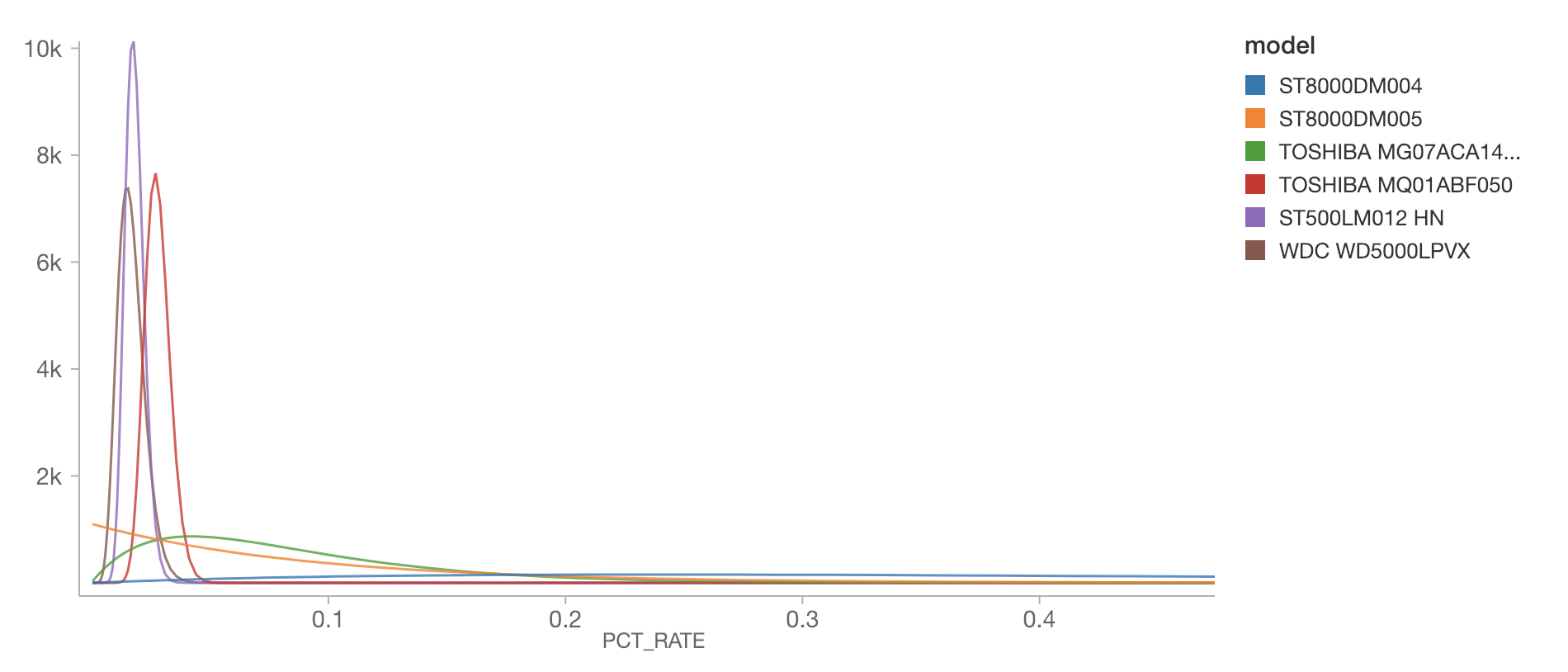
Notice how different the distribution of estimated failure rate is for various models. The ST8000DM004 has a very wide distribution across, admittedly, higher failure rates; it’s cut off for readability here, but the bulk of its distribution extends past 0.4% per year (again note that the plot is annualized failure rate, for readability). This is because we have relatively very few observations of this model:
Zoom in on the two peaked distributions at the left, for the “ST500LM012 HN” and “WDC WD5000LPVX”:
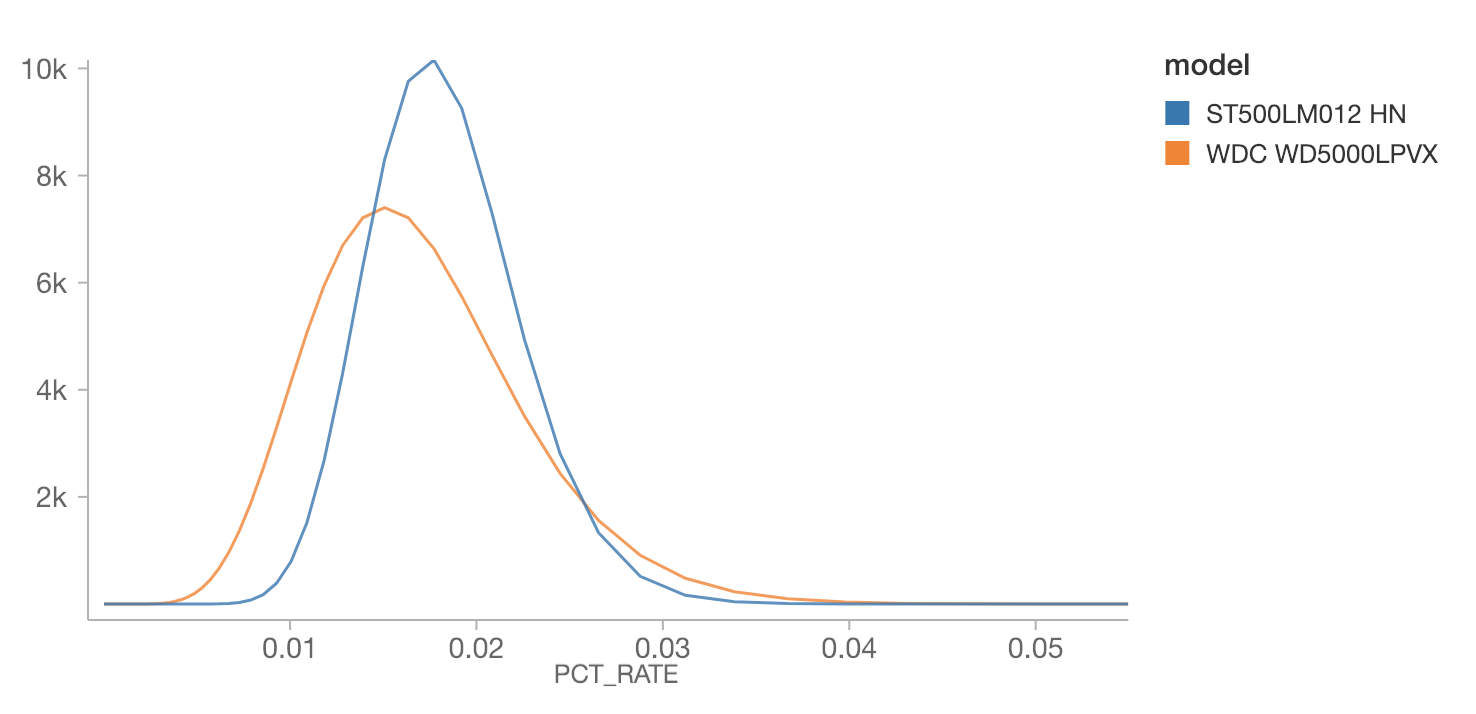
Interestingly, the WDC’s most likely annualized failure rate is lower than the ST500’s -- about 0.015% vs 0.02%. However, we have fewer observations of the WDC, and its distribution is wider. If the question were, which drive is more likely to have a failure rate above 0.03%, then based on this information, it would be the WDC. This might actually be relevant if, for example, deciding which drives are most likely to be out of manufacturer’s tolerances. Distributions matter! Not just MAP estimates.
Analyzing Failures in a Stream with Priors
This data doesn’t arrive all at once, in reality. It arrives in a stream, and so it’s natural to run these kind of queries continuously. This is simple with Apache Spark’s Structured Streaming, and proceeds almost identically.
Of course, on the first day this streaming analysis is rolled out, it starts from nothing. Even after two quarters of data here, there’s still significant uncertainty about failure rates, because failures are rare.
An organization that’s transitioning this kind of offline data science to an online streaming context probably does have plenty of historical data. This is just the kind of prior belief about failure rates that can be injected as a prior distribution on failure rates!
The gamma distribution is, conveniently, conjugate to the Poisson distribution, so we can use the gamma distribution to represent the prior, and can trivially compute the posterior gamma distribution after observing some data without a bunch of math. Because of the interpretation of the parameters ɑ and β as number of failures and number of days, these values can be computed over historical data and then just added to the parameters computed and updated continuously by a Structured Streaming job. Observe:
https://www.youtube.com/watch?v=8dzq5EEhuxk
Historical data yields the ɑ and β from the gamma-distributed priors for each model, and this is easily joined into the same analysis on a stream of data (here, simulated as a ‘stream’ from the data we analyzed above).
When run, this yields an updating plot of failure rate distributions for the models with the highest failure rate. It could as easily produce alerts or other alerts based on other functions of these distributions, with virtually the same code that produced a simple offline analysis.
Conclusion
There’s more going on when you fit a distribution than you may think. You may be employing ‘frequentist’ or ‘Bayesian’ reasoning without realizing it. There are advantages to the Bayesian point of view, because it gives a place for prior knowledge about the answer, and yields a distribution over answers instead of one estimate. This perspective can easily be put into play in real-world applications with Spark’s Structured Streaming and understanding of prior and posterior distributions.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.