Securely Accessing External Data Sources from Databricks for AWS
by Itai Weiss
Databricks Unified Analytics Platform, built by the original creators of Apache SparkTM, brings Data Engineers, Data Scientists and Business Analysts together with data on a single platform. It allows them to collaborate and create the next generation of innovative products and services. In order to create the analytics needed to power these next-gen products, Data Scientists and Engineers need access to various sources of data. Apart from data in the cloud block storage such as S3, this data that they need is often located on services such as databases or even come from streaming data sources located in disparate VPCs.
Securely connecting to “non-S3” external Data Sources
For security purposes, Databricks Apache Spark clusters are deployed in an isolated VPC dedicated to Databricks within the customer's account. In order to run their data workloads, there is a need to have secure connectivity between the Databricks Spark Clusters and the above data sources.
It is straightforward for Databricks clusters located within the Databricks VPC to access data from AWS S3 which is not a VPC specific service. However, we need a different solution to access data from sources deployed in other VPCs such as AWS Redshift, RDS databases, streaming data from Kinesis or Kafka. This blog will walk you through some of the options you have available to access data from these sources securely and their cost considerations for deployments on AWS. In order to establish a secure connection to these data sources, we will have to configure the Databricks VPC with either one of the following two available options :
Option 1: VPC Peering
A secure connection between the Databricks cluster and the other non-S3 external data sources can be established by using VPC peering. AWS defines VPC peering as “a networking connection between two VPCs that enables you to route traffic between them using private IPv4 addresses or IPv6 addresses”. For more details see AWS documentation here.
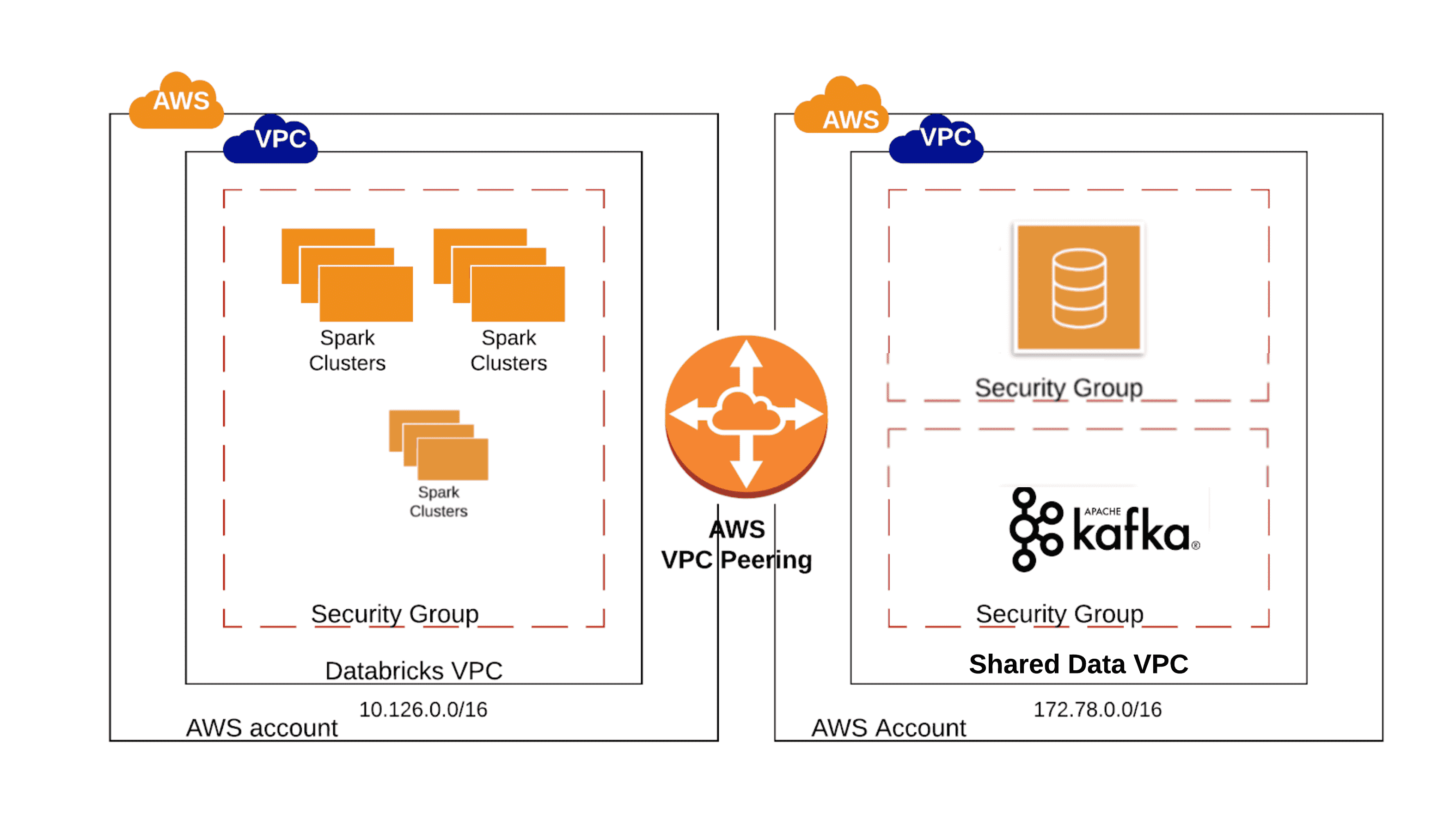
When the VPC peering option is chosen, one has to take the following factors into consideration:
- VPC Peering is easier and more appropriate when there are several resources that should communicate between the peered VPCs . When there is a high degree of inter VPC communication, VPC peering would be the recommended option.
- The VPC hosting the other “non-S3 data sources” must have a CIDR range distinct from the CIDR range of the Databricks VPC or any other CIDR range included as a destination in the Databricks VPC’s main route table
- VPC peering has scale limitations. Please check AWS documentation for the latest.
- Pricing considerations:
- Same region pricing: If the VPCs in the VPC peering connection are within the same region, the charges for transferring data over the VPC peering connection are the same as the charges for transferring data across Availability Zones.
- Different regions pricing: If the VPCs are in different regions, inter-region data transfer costs apply.
- For accurate and latest pricing, please refer AWS documentation.
Here is an example of a situation where VPC peering option would be ideal - You are tasked with creating a data table that will pull the data from a Kafka cluster and store the aggregated results on Aurora database both located on the same VPC external to the Databricks VPC. Assuming no other security limitations, you can use VPC peering connection between the Databricks VPC and the external VPC where the data sources are located and then connect to both sources.
Option 2: AWS Privatelink
The second option available to connect with the non-S3 data sources would be to use an AWS Privatelink. AWS defines PrivateLink as a service that “provides private connectivity between VPCs, AWS services, and on-premises applications, securely on the Amazon network. AWS PrivateLink simplifies the security of data shared with cloud-based applications by eliminating the exposure of data to the public Internet.”
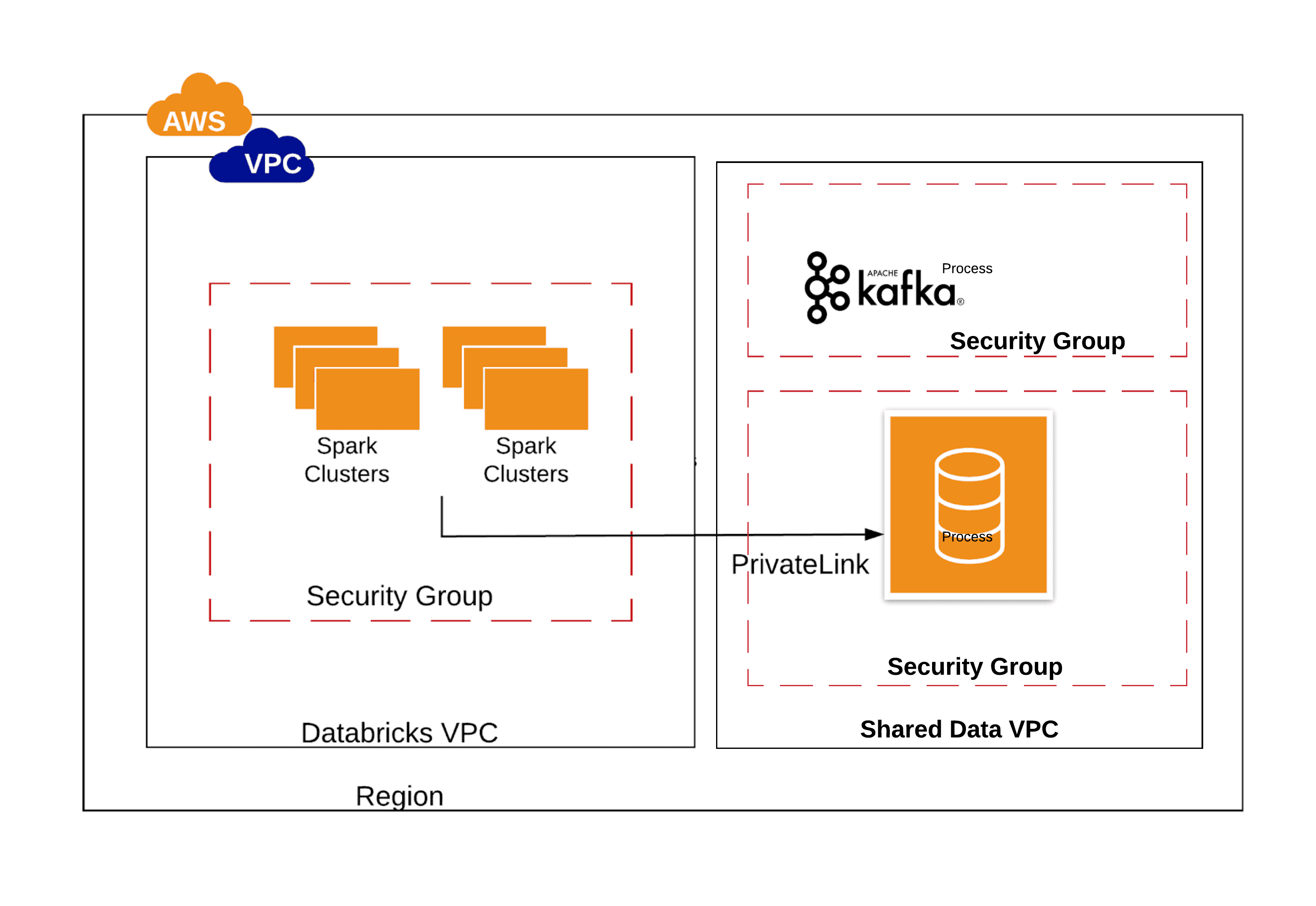
One has to take the following considerations into account while choosing the Privatelink option:
- Privatelinks are overall easier to setup and more suited for VPC relationships that have the following security requirements:
- Each Privatelink will connect only to one single service
- It is easy to find out which services/ports are open to the Databricks service
- Each service accessed can be controlled separately
- AWS Privatelink supports overlapping CIDR ranges by applying source NAT from the consumer to the provider of the AWS Privatelink
- Although, AWS Privatelink can scale to thousands of consumers per VPC, at any time only one Privatelink can be configured
- AWS Privatelink only allows the data consumer to originate connections to the data provider. If bidirectional communication is needed, VPC Peering or a reciprocal AWS Privatelink between the consumer and provider may be required.
- AWS Privatelink inherits the design consideration of Network Load Balancers (NLB). For example, NLBs only support TCP and connections from the consumer to provider go through source NAT which may prevent applications from identifying the consumer IP address.
- Pricing Consideration:
- Data processing charges apply for each Gigabyte processed through the VPC endpoint regardless of the traffic’s source or destination
- Data transferred between availability zones, or between your Endpoint and your premises via Direct Connect will also incur the usual EC2 Regional and Direct Connect data transfer charges. See AWS PrivateLink pricing.
Here is an example of when you would use a AWS privatelink. You have a production VPC with many data sources such as Redshift, Aurora and MySQL. The business would like to query the data from the MySQL database, but not expose confidential data stored in Redshift or Aurora. Using privatelink, you can open a connection from Databricks clusters to MySQL, allowing your users to access MySql securely while restricting connectivity to Redshift and Aurora.
The Configuration
Manual or programmatic VPC peering: https://docs.databricks.com/administration-guide/cloud-configurations/aws/vpc-peering.html
Manual Privatelink setup: https://docs.aws.amazon.com/vpc/latest/privatelink/endpoint-services-overview.html
Databricks resources on connecting to data sources
Final Steps
Once a network connection via VPC Peering or Privatelink is established, authentication with the specific data source or service can then be setup. Please access Databricks on AWS documentation for the specific data sources that you need access to. Wherever possible consider using secrets to keep your connection secure. Using the correct connection options based on your needs reduces overall complexity and helps Data Scientist and Data Engineers have access to the data they need in a secure manner.
Try It!
- Call us to find out how Databricks can improve your security posture.
- Learn more by downloading our security e-book Protecting Enterprise Data on Apache Spark.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.