Introducing Databricks Runtime 5.4 with Conda (Beta)
by Hossein Falaki and Yifan Cao
We are excited to introduce a new runtime: Databricks Runtime 5.4 with Conda (Beta). This runtime uses Conda to manage Python libraries and environments. Many of our Python users prefer to manage their Python environments and libraries with Conda, which quickly is emerging as a standard. Conda takes a holistic approach to package management by enabling:
- The creation and management of environments
- Installation of Python packages
- Easily reproducible environments
- Compatibility with pip
We are therefore happy to announce that you can now get a runtime that is fully based on Conda. It is being released with the “Beta” label, as it is intended for experimental usage only, not yet for production workloads. This designation provides an opportunity for us to collect customer feedback. As Databricks Runtime with Conda matures, we intend to make Conda the default package manager for all Python users.
To get started, select the Databricks Runtime 5.4 with Conda (Beta) from the drop-down list when creating a new cluster in Databricks. Follow the instructions displayed when you hover over the question mark to select one of the two pre-configured environments: Standard (default) or Minimal.
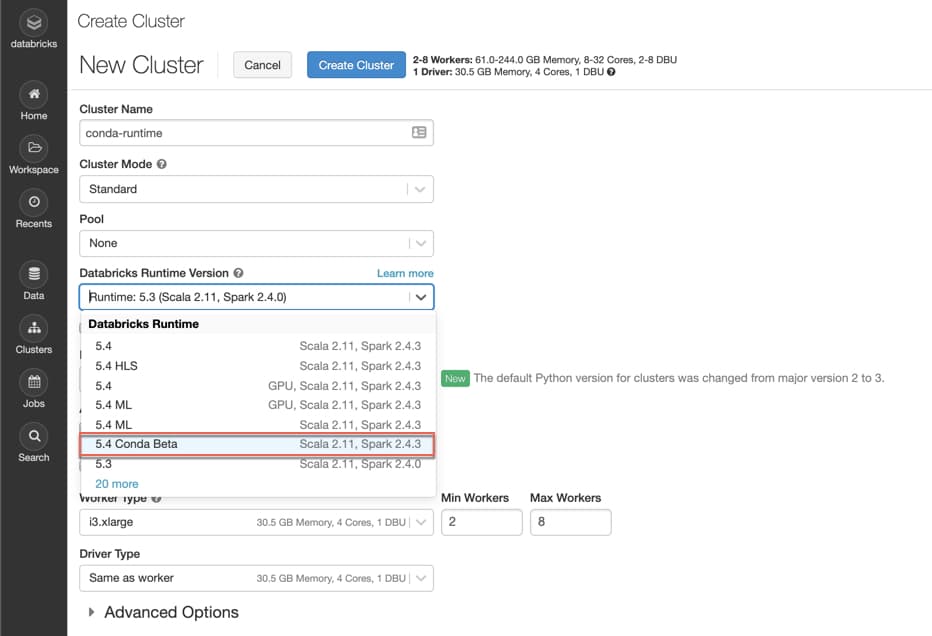
Why Databricks Runtime with Conda
Conda is an open source package & environment management system. Due to its extensive support and flexibility, Conda is becoming the standard among developers for managing Python packages. As an environment manager, it enables users to easily create, save, load, and switch between Python environments. We have been using Conda to manage Python libraries in Databricks Runtime for Machine Learning, and have received positive feedback. With Databricks Runtime with Conda (Beta), we extend Conda to serve more use cases.
For Python developers, creating an environment with desired libraries installed is the first step. In particular, the field of machine learning is evolving rapidly, and new tools and libraries in Python are emerging and are being updated frequently. Setting up a reliable environment poses challenges, such as version conflicts, dependency issues, and environment reproducibility. Conda was created to solve this very problem. By combining environments and installation into a single framework, developers can easily and reliably set up libraries in an isolated environment. Building-in first-class Conda support in Databricks Runtime significantly improves the productivity of developers and data scientists on your team.
Our Unified Analytics Platform serves a wide variety of users and experience levels. We enable users migrating from SAS or R to Python but are still new to Python to Python experts. Our intention is to make managing your Python environment as easy as possible. In service of this, we offer:
- Multiple robust pre-configured environments, each serving a different use case
- A simple way to customize environments
- The ease and flexibility to manage, share, and recreate environments at different levels of the Databricks product (Workspace, cluster, and notebook)
Not only do we want to make it very easy for you to get started in Databricks, but also very easy for you to migrate Python code developed somewhere else to Databricks. In Databricks Runtime 5.4 with Conda (Beta), you can take code, along with the requirements file (requirement.txt) from GitHub, Jupyter notebooks, or other data science IDE to Databricks. Everything should just work out of the box. As a developer, you can spend little time worrying about managing libraries, and focus your time on developing applications.
What Databricks Runtime Conda 5.4 (Beta) Offers
Databricks Runtime 5.4 with Conda (Beta) improves flexibility in the following ways:
Enhance Pre-configured Environments
- We are committed to providing pre-configured environments with popular Python libraries installed. In Databricks Runtime 5.4 with Conda (Beta), we introduce two configured environments: Standard and Minimal (Azure | AWS). In both environments, we upgraded Python base libraries, compared to Databricks Runtime (Azure | AWS)
- Databricks Runtime 5.4 with Conda (Beta) allows you to use Conda to install Python packages. If you want to install libraries, you will benefit from the support Conda provides. Please refer to the User Guide (Azure | AWS) to learn how to use Conda to install packages
- We are leveraging Anaconda Distribution 5.3.1
- We upgraded to Python 3.7
Easy Customization of Environment
- Databricks Runtime 5.4 with Conda (Beta) allows you to easily customize your Python environments. You can define your environment needs in a requirements file (requirements.txt), upload it to DBFS, and then use
dbutils.library.installto build the customized environment in a notebook. You no longer need to install libraries one by one. - You can find sample requirements files and instructions to customize environments in User Guide (Azure | AWS)
Environment Reproducibility
- In Databricks Runtime 5.4 with Conda (Beta), each notebook can have an isolated Python environment, mitigating package conflicts across notebooks.
- You can use
requirements.txtto easily reproduce an environment to a notebook.
Which Runtime I Should Pick
In the future, the Databricks Runtime for Conda will be the standard runtime. However, as a Beta offering, Databricks Runtime with Conda is intended for experimental usage, not for production workloads. Here are some guidelines to help you choose a runtime:
Databricks Runtime: We encourage Databricks Runtime users who need stability to continue to use Databricks Runtime.
Databricks Runtime ML: We encourage Databricks Runtime ML users who don’t need to customize environments to continue to use Databricks Runtime ML.
Databricks Runtime with Conda: Databricks Runtime 5.4 with Conda (Beta) offers two Conda-based, preconfigured root environments -- Standard and Minimal -- that serve different use cases.
- Standard Environment: The default environment (Azure | AWS). At cluster creation, you select the Databricks Runtime 5.4 with Conda (Beta) in the Databricks Runtime Version drop-down list. Aimed to serve Databricks Runtime users, the Standard Environment provides a ready-to-use environment by pre-installing popular python packages based on usage. A number of base Python libraries are upgrade in the Standard Environment. We encourage users of Databricks Runtime who need these upgraded Python libraries to try out the Standard environment.
- Minimal Environment: Includes a minimal set of libraries to run Python notebooks and PySpark in Databricks (Azure | AWS). This light environment is designed for customization. We encourage Python users who need to customize their Python environment but run into dependency conflicts with the standard environment to try out the Minimal environment.
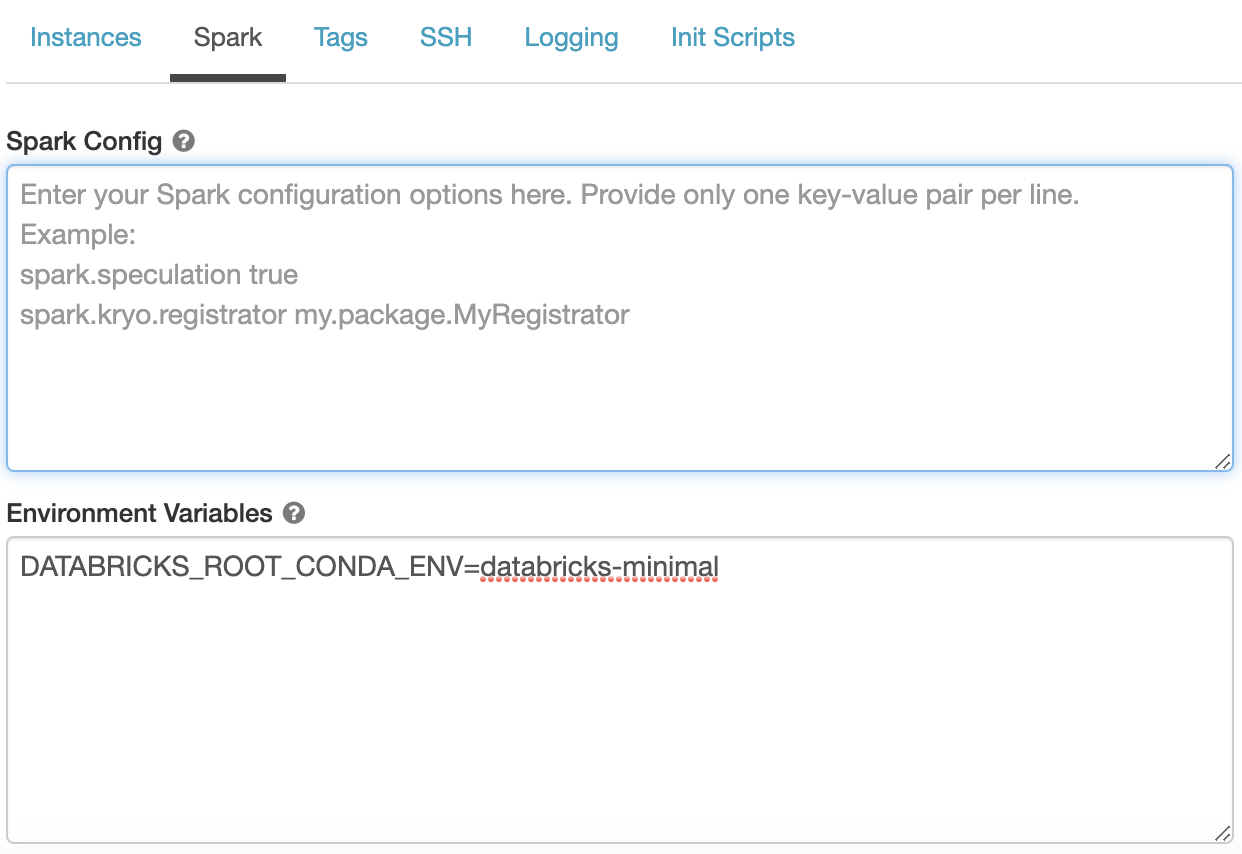
To use the Minimal environment, you select Databricks Runtime 5.4 with Conda in the Databricks Runtime Version drop-down list. Then follow the instructions to copy and paste DATABRICKS_ROOT_CONDA_ENV=databricks-minimal to Advanced Options > Spark > Environment Variables, which can be found at the bottom of the Create Cluster Page (see below). In the upcoming releases, we will simplify this step and let you choose the MInimal environment from a drop-down list.
What to Expect in Upcoming Releases
In the coming releases, we plan to keep improving the three key use cases Databricks Runtime with Conda serves.
Enhance Pre-configured Environments
Our ultimate goal is to unify cluster creation for all three runtimes (Databricks Runtime, Databricks Runtime ML, Databricks Runtime with Conda) in a seamless experience. At full product maturity, we expect to have multiple pre-configured environments serving different use cases, including environments for Machine Learning. In addition, we plan to improve the user experience by allowing you to choose a pre-configured environment in Databricks Runtime with Conda from a drop-down list. Finally, we will continue to update Python packages as well as Anaconda distribution.
Easy Customization of Environments
We plan to add support for using environment.yml (environment file used by conda with Libraries Utilities in notebooks. We also plan to support conda package installation in Library Utilities in notebooks and in cluster-installed libraries. Currently both use PyPI.
Easy Reproducibility of Environments
We plan to make it very easy to view, modify, and share environment parameters across users. You can save an environment file in Workspace, and easily switch between environments so that the same environment can be replicated to a cluster at cluster creation.
Upgraded Python Libraries in Databricks Runtime 5.4 with Conda (Beta)
Please find the list of pre-installed packages in Databricks Runtime with Conda (Beta) in our release notes (Azure | AWS).
Read More
- Databricks Runtime 5.4 with Conda (Beta) release notes (Azure | AWS)
- Databricks Runtime 5.4 with Conda (Beta) User Guide (Azure | AWS)
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.