Network performance regressions from TCP SACK vulnerability fixes
Update on Aug 2, 2019: Added to the end explaining our kernel patch and additional details we found.
On June 17, three vulnerabilities in Linux’s networking stack were published. The most severe one could allow remote attackers to impact the system’s availability. We believe in offering the most secure image available to our customers, so we quickly applied a kernel patch to address the issues.
Since the kernel patch was applied, we have observed certain workloads experiencing unexpected, nondeterministic performance regressions on the Amazon Web Services (AWS) platform, manifesting in the form of lengthy or hung writes to S3. We have not observed any performance regressions on Microsoft Azure. Even though these regressions can be observed in less than 0.2% of cases, we wanted to share with you what we have found so far and a mitigation strategy.
Symptom
The behavior can manifest in any Databricks Runtime / Apache Spark version. Affected customers will see Spark jobs running on Databricks clusters slow down and potentially “hang” for 15 minutes, or fail entirely due to timeout, when writing to Amazon S3. Customers may see a stack trace similar to this in Databricks cluster logs:
Customers can also look at the Spark web UI and see one or more tasks taking an abnormally long time compared with most other tasks of the same stage.
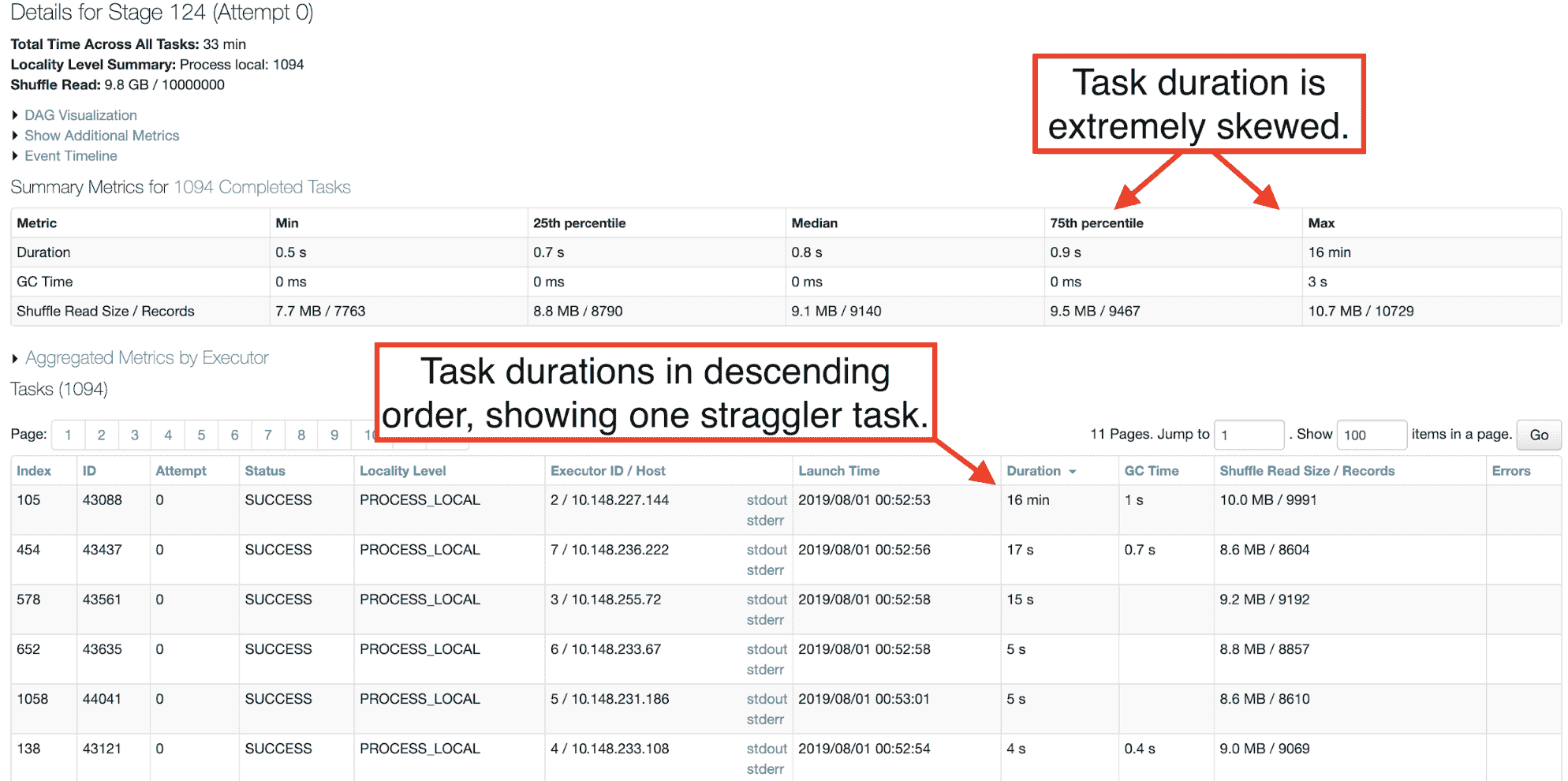
Since the security patch was applied to the Databricks platform on June 24th, any change in performance would coincide precisely with that date. Jobs that performed normally on (or after) June 24th and later experienced a performance regression would be unrelated to this issue.
Root Cause
The TCP SACK DoS vulnerability was disclosed on June 17, 2019. It enables a remote attacker to trigger a kernel panic on a server that is accepting traffic on a port.
Our Infrastructure Security Team immediately triaged the issue and decided to ship the patch to this CVE in our regular security release train. We shipped this update in the form of a new Amazon Machine Image (AMI), which forms the base image for the operating system on which we run LXC containers containing the Databricks Runtime.
Shortly after rolling out the patch, we identified nondeterministic abnormalities in a very small subset of our internal benchmarks and in some customer jobs. For example, short 5-minute data processing jobs that write to Amazon S3 were taking up to an hour to finish.
Using the reproduction from our internal benchmarks, we analyzed network traffic between Databricks clusters and Amazon S3. Clusters without the patch exhibited the expected behavior when writing to Amazon S3, consistently completing writes in less than 90 seconds:
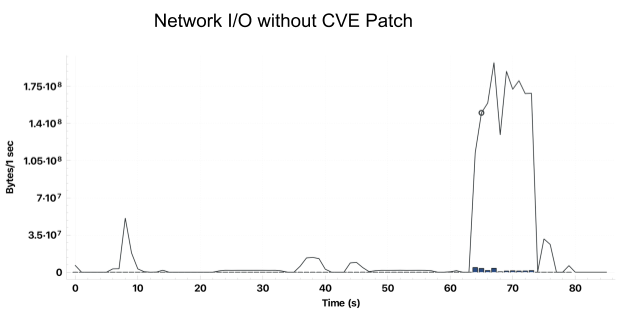
However, the same code running on clusters with the security patch experienced short periods of data transfer to Amazon S3 followed by long periods of inactivity. Here is an example job that took over 15 minutes to complete:
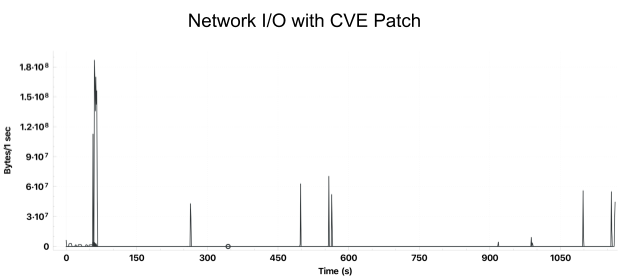
Mitigation Strategy
We are still actively investigating the issue in order to determine the root cause. Fixing this non-deterministic performance regression might require another OS-level patch. In the meantime, security is our default and we will continue to ship the most secure kernel we can offer. We will share with you updates as soon as we have them.
Fortunately, Spark and Databricks’ platform have been designed from the beginning to mitigate these types of long-tail distributed system problems. Customers can turn on task speculation in Apache Spark by setting “spark.speculation” to “true” in their cluster configuration to mitigate this issue. This capability was designed initially to mitigate stragglers, in the case of machine slowdowns. When speculation is turned on, Spark will launch a replica of the long-running slow task and retry it, with a high likelihood that the replica task will finish quickly without hitting the performance regression.
For customers that do not want to leverage task speculation and can accept a different security threat model, our support team can work with you to provide alternate mitigation strategies. Please contact your Account Manager or help@databricks.com if you are affected and require assistance identifying a workaround.
Update on Aug 2, 2019
Our AMIs use an unmodified Ubuntu 16.04 image for the OS, which is backed by the Linux 4.4.0 kernel. Our sockets use TCP SACKs by default (S3 servers do as well), so we patched the TCP SACKs vulnerability by updating from 4.4.0-1084-aws #94-Ubuntu to 4.4.0-1085-aws #96-Ubuntu. As we continued to track the issue, we learned that 4.4.0-1087-aws #98-Ubuntu included three more TCP SACKs related patches. One of those patches was meant to fix the performance of sockets with low SO_SNDBUF. While we use the default SO_SNDBUF of 16KB, we applied the updates but did not see any improvements. An additional upstream patch was made on July 19 to fix another corner case for low SO_SNDBUF sockets. As it has not yet been incorporated into Ubuntu 16.04, but we built a custom image with that patch and it resolved the networking performance issues. We will follow up with a more detailed analysis.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.