Analyzing Your MLflow Data with DataFrames

Max Allen interned with Databricks Engineering in the Summer of 2019. This blog post, written by Max, highlights the great work he did while on the team.
Introduction to MLflow and the Machine Learning Development Lifecycle
MLflow is an open source platform for the machine learning lifecycle, and many Databricks customers have been using it to develop and deploy models that detect financial fraud, find sales trends, and power ride-hailing. A critical part of the machine learning development life cycle is testing out different models, each of which could be constructed using different algorithms, hyperparameters and datasets. The MLflow Tracking component allows for all these parameters and attributes of the model to be tracked, as well as key metrics such as accuracy, loss, and AUC. Luckily, since we introduced auto-logging in MLflow 1.1, much of this tracking work will be taken care of for you.
The next step in the process is to understand which machine learning model performs the best based on the outcome metrics. When you just have a handful of runs to compare, the MLflow UI’s compare runs feature works well. You can view the metrics of the runs lined up next to each other and create scatter, line, and parallel coordinate plots.
Two New APIs for Analyzing Your MLflow Data
However, as the number of runs and models in an experiment grows (particularly after running an AutoML or hyperparameter search algorithm), it becomes cumbersome to do this analysis in the UI. In some cases, you’ll want direct access to the experiment data to create your own plots, do additional data-engineering, or use the data in a multi-step workflow. This is why we’ve created two new APIs that allow users to access their MLflow data as a DataFrame. The first is an API accessible from the MLflow Python client that returns a pandas DataFrame. The second is an Apache Spark Data Source API that loads data from MLflow experiments into a Spark DataFrame. Once you have your run data accessible in a DataFrame, there are many different types of analyses that can be done to help you choose the best machine learning models for your application.
pandas DataFrame Search API
Note: The pandas DataFrame Search API is available in MLflow open source versions 1.1.0 or greater. It is also pre-installed on Databricks Runtime 6.0 ML and greater.
Since pandas is such a commonly used library for data scientists, we decided to create a mlflow.search_runs() API that returns your MLflow runs in a pandas DataFrame. This API takes in similar arguments as the mlflow.tracking.search_runs() API, except for the page_token parameter. This API automatically paginates through all your runs and adds them to the DataFrame. Using it is extremely simple:
If you don’t provide an experiment ID, the API tries to find the MLflow experiment associated with your notebook. This will work in the case when you’ve previously created MLflow runs in this notebook. Otherwise, to get the ID for a particular experiment, you can either find it in the MLflow UI:
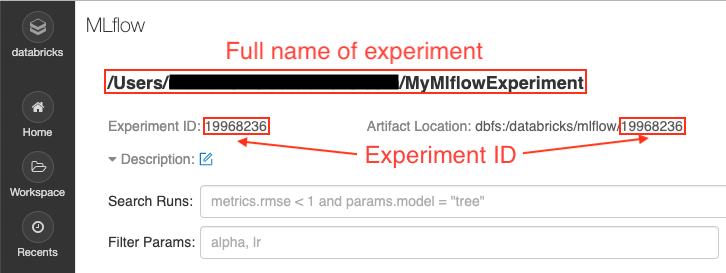
Or you can get it programmatically if you know the full name of the experiment:
The search API also takes in optional parameters such as a filter string, which follows the search syntax described in the MLflow search docs. Loading the models with metric “accuracy” greater than 85% would look like the following query:
MLflow Experiment as a Spark Data Source
Note: Available only for Databricks customers using Databricks Runtime 6.0 ML and above
Apache Spark comes ready with the ability to read from many data sources (S3, HDFS, MySQL, etc.) and from many data formats (Parquet, CSV, JSON, ORC, etc). In Databricks Runtime 6.0 ML, we added an MLflow experiment Spark data source so that Spark applications can read MLflow experiment data just as if it were any other dataset.You can load a Spark DataFrame from this data source as follows:
An example output would look like the following (truncated columns on the right):
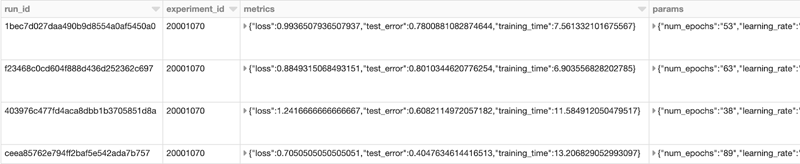
To get the ID of an experiment by its name using Scala, see the below code:
Once you have your run data in a Spark DataFrame, there are plenty of analyses you can do. You can use the Spark Dataframe APIs, the Databricks notebook native plotting capabilities, Spark UDFs, or register the DataFrame as a table using createOrReplaceTempView.
Next Steps for Building Up Your Machine Language Muscles
Having laid this foundation, there are plenty of opportunities to build upon these features. In fact, we have already had contributions to MLflow adding additional metadata to the pandas schema, and CSV export functionality for the MLflow CLI. If you’re interested in contributing to MLflow, check out our MLflow contribution guide on Github and submit a PR!
Read More
- Documentation for the pandas Search API can be found here.
- Documentation on pandas DataFrame can be found on the pandas website.
- Check out open source data visualization libraries such as Plotly and Matplotlib.

