Scaling Hyperopt to Tune Machine Learning Models in Python
by Joseph Bradley and Max Pumperla
Try the Hyperopt notebook to reproduce the steps outlined below and watch our on-demand webinar to learn more.
Hyperopt is one of the most popular open-source libraries for tuning Machine Learning models in Python. We’re excited to announce that Hyperopt 0.2.1 supports distributed tuning via Apache Spark. The new SparkTrials class allows you to scale out hyperparameter tuning across a Spark cluster, leading to faster tuning and better models. SparkTrials was contributed by Joseph Bradley, Hanyu Cui, Lu Wang, Weichen Xu, and Liang Zhang (Databricks), in collaboration with Max Pumperla (Konduit).
What is Hyperopt?
Hyperopt is an open-source hyperparameter tuning library written for Python. With 445,000+ PyPI downloads each month and 3800+ stars on Github as of October 2019, it has strong adoption and community support. For Data Scientists, Hyperopt provides a general API for searching over hyperparameters and model types. Hyperopt offers two tuning algorithms: Random Search and the Bayesian method Tree of Parzen Estimators.
For developers, Hyperopt provides pluggable APIs for its algorithms and compute backends. We took advantage of this pluggability to write a new compute backend powered by Apache Spark.
Scaling out Hyperopt with Spark
With the new class SparkTrials, you can tell Hyperopt to distribute a tuning job across a Spark cluster. Initially developed within Databricks, this API for hyperparameter tuning has enabled many Databricks customers to distribute computationally complex tuning jobs, and it has now been contributed to the open-source Hyperopt project, available in the latest release.
Hyperparameter tuning and model selection often involve training hundreds or thousands of models. SparkTrials runs batches of these training tasks in parallel, one on each Spark executor, allowing massive scale-out for tuning. To use SparkTrials with Hyperopt, simply pass the SparkTrials object to Hyperopt’s fmin() function:
For a full example with code, check out the Hyperopt documentation on SparkTrials.
Under the hood, fmin() will generate new hyperparameter settings to test and pass them toSparkTrials. The diagram below shows how SparkTrials runs these tasks asynchronously on a cluster: (A) Hyperopt’s primary logic runs on the Spark driver, computing new hyperparameter settings. (B) When a worker is ready for a new task, Hyperopt kicks off a single-task Spark job for that hyperparameter setting. (C) Within that task, which runs on one Spark executor, user code will be executed to train and evaluate a new ML model. (D) When done, the Spark task will return the results, including the loss, to the driver. These new results are used by Hyperopt to compute better hyperparameter settings for future tasks.
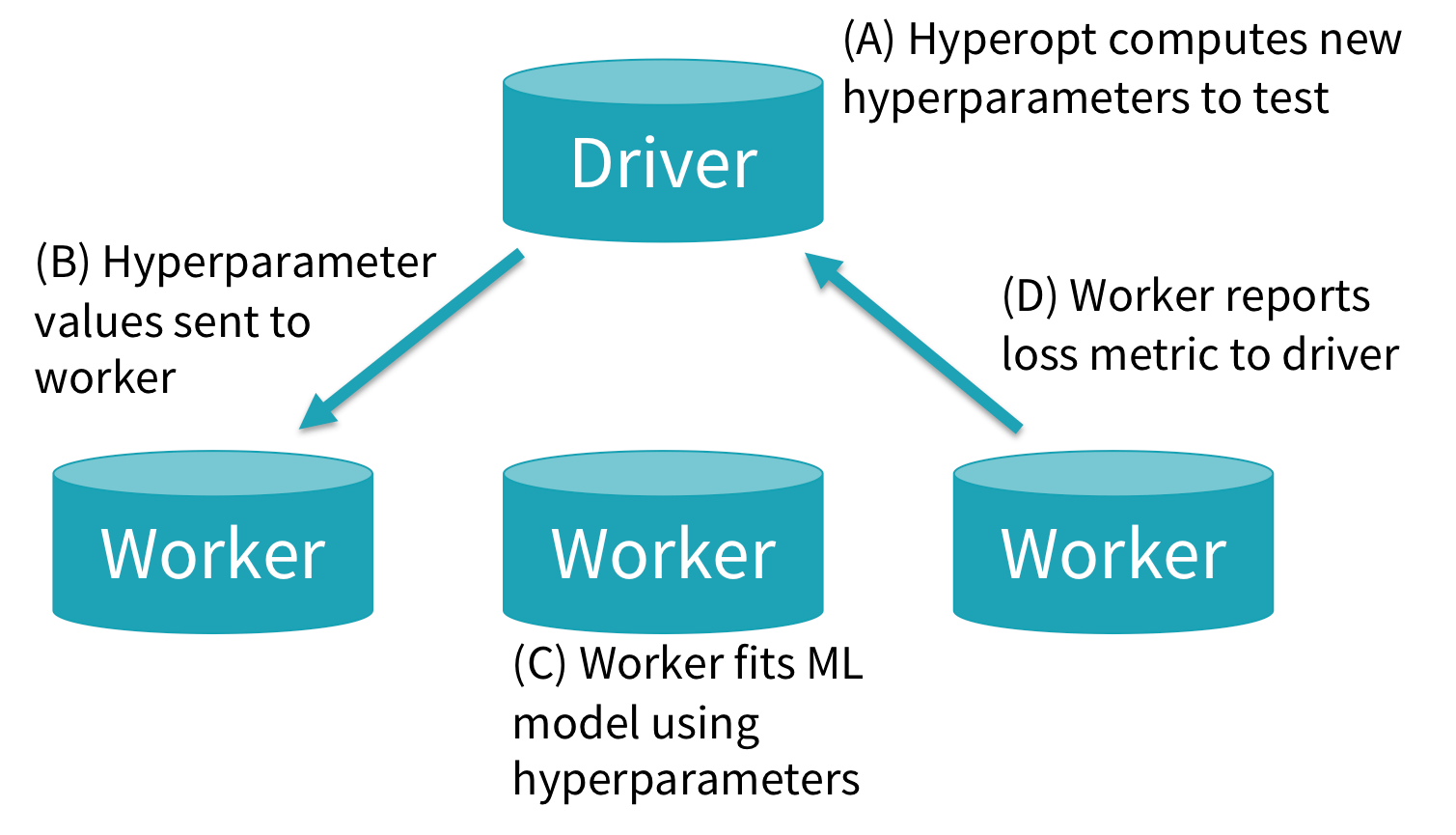
Since SparkTrials fits and evaluates each model on one Spark worker, it is limited to tuning single-machine ML models and workflows, such as scikit-learn or single-machine TensorFlow. For distributed ML algorithms such as Apache Spark MLlib or Horovod, you can use Hyperopt’s default Trials class.
Using SparkTrials in practice
SparkTrials takes 2 key parameters: parallelism (Maximum number of parallel trials to run, defaulting to the number of Spark executors) and timeout (Maximum time in seconds which fmin is allowed to take, defaulting to None). Timeout provides a budgeting mechanism, allowing a cap on how long tuning can take.
The parallelism parameter can be set in conjunction with the max_evals parameter for fmin() using the guideline described in the following diagram. Hyperopt will test max_evals total settings for your hyperparameters, in batches of size parallelism. If parallelism = max_evals, then Hyperopt will do Random Search: it will select all hyperparameter settings to test independently and then evaluate them in parallel. If parallelism = 1, then Hyperopt can make full use of adaptive algorithms like Tree of Parzen Estimators which iteratively explore the hyperparameter space: each new hyperparameter setting tested will be chosen based on previous results. Setting parallelism in between 1 and max_evals allows you to trade off scalability (getting results faster) and adaptiveness (sometimes getting better models). Good choices tend to be in the middle, such as sqrt(max_evals).

To illustrate the benefits of tuning, we ran Hyperopt with SparkTrials on the MNIST dataset using the PyTorch workflow from our recent webinar. Our workflow trained a basic Deep Learning model to predict handwritten digits, and we tuned 3 parameters: batch size, learning rate, and momentum. This was run on a Databricks cluster on AWS with p2.xlarge workers and Databricks Runtime 5.5 ML.
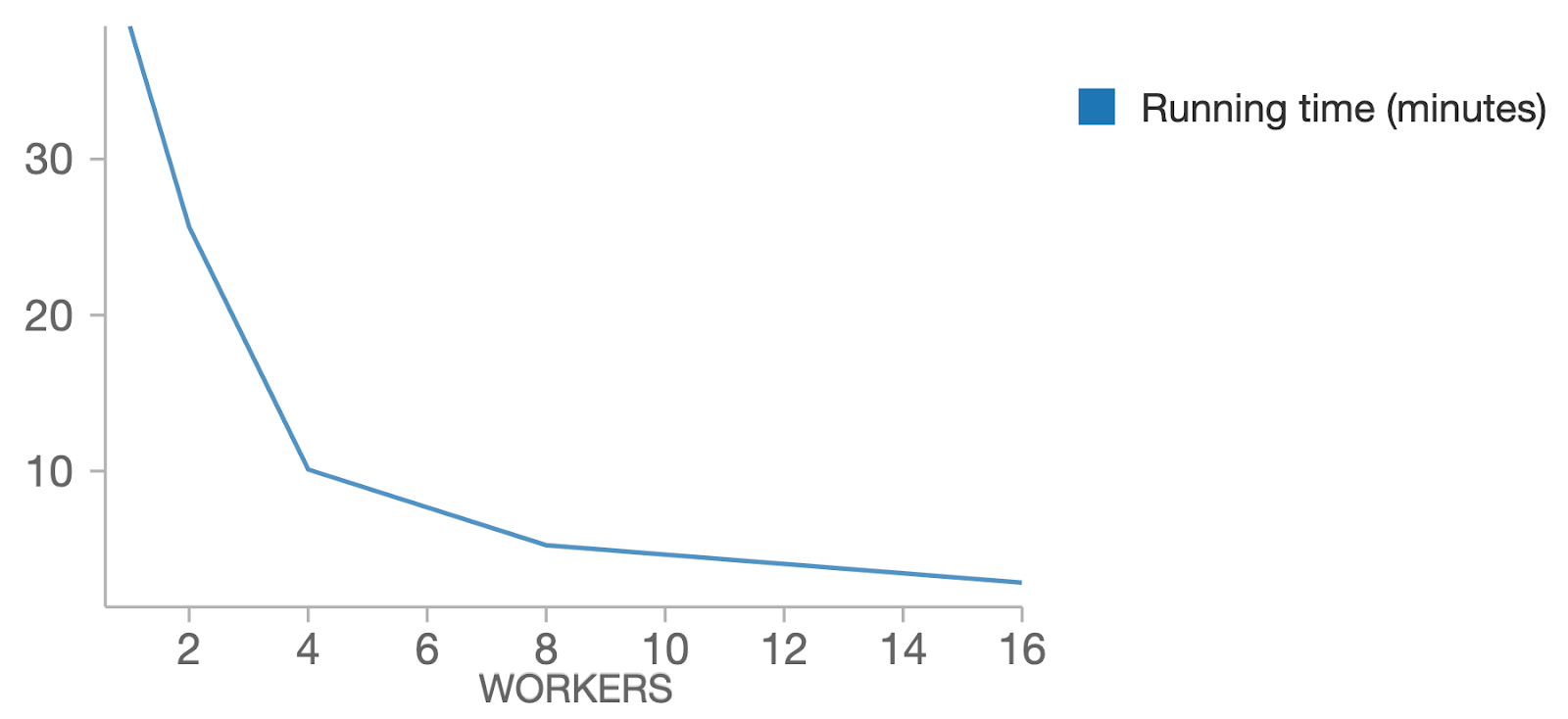
In the plot below, we fixed max_evals to 128 and varied the number of workers. As expected, more workers (greater parallelism) allow faster runtimes, with linear scale-out.
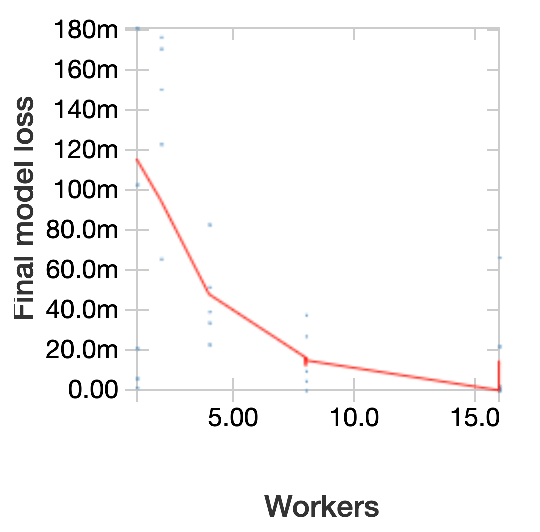
We then fixed the timeout at 4 minutes and varied the number of workers, repeating this experiment for several trials. The plot below shows the loss (negative log likelihood, where “180m” = “0.180”) vs. the number of workers; the blue points are individual trials, and the red line is a LOESS curve showing the trend. In general, model performance improves as we use greater parallelism since that allows us to test more hyperparameter settings. Notice that behavior varies across trials since Hyperopt uses randomization in its search.
Getting started with Hyperopt 0.2.1
SparkTrials is available now within Hyperopt 0.2.1 (available on the PyPi project page) and in the Databricks Runtime for Machine Learning (5.4 and later).
To learn more about Hyperopt and see examples and demos, check out:
- Documentation on the project Github.io page, including a full code example
Hyperopt can also combine with MLflow for tracking experimentals and models. Learn more about this integration in the open-source MLflow example and in our Hyperparameter Tuning blog post and webinar.
You can get involved via the Github project page:
- Report open-source issues on the Github Issues page
- Contribute to Hyperopt on Github
Related Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.