Use Databricks Pools to Speed up your Data Pipelines and Scale Clusters Quickly
Reduce the time to get your instances by 4x with new Databricks Pools
by Chris Stevens and David Meyer
Data Engineering teams deploy short, automated jobs on Databricks. They expect their clusters to start quickly, execute the job, and terminate. Data Analytics teams run large auto-scaling, interactive clusters on Databricks. They expect these clusters to adapt to increased load and scale up quickly in order to minimize query latency. Databricks is pleased to announce Databricks Pools, a managed cache of virtual machine instances that enables clusters to start and scale 4 times faster.
Cluster lifecycles before Databricks Pools
Without Pools, Databricks acquires virtual machine (VM) instances from the cloud provider upon request. This is cost-effective but slow. There are no idle VM instances to pay for, but with each cluster create and auto-scaling event, Databricks must request VMs from the cloud and wait for them to initialize. The below diagram shows the typical lifecycle for Data Engineering job clusters and interactive Data Analytics clusters.
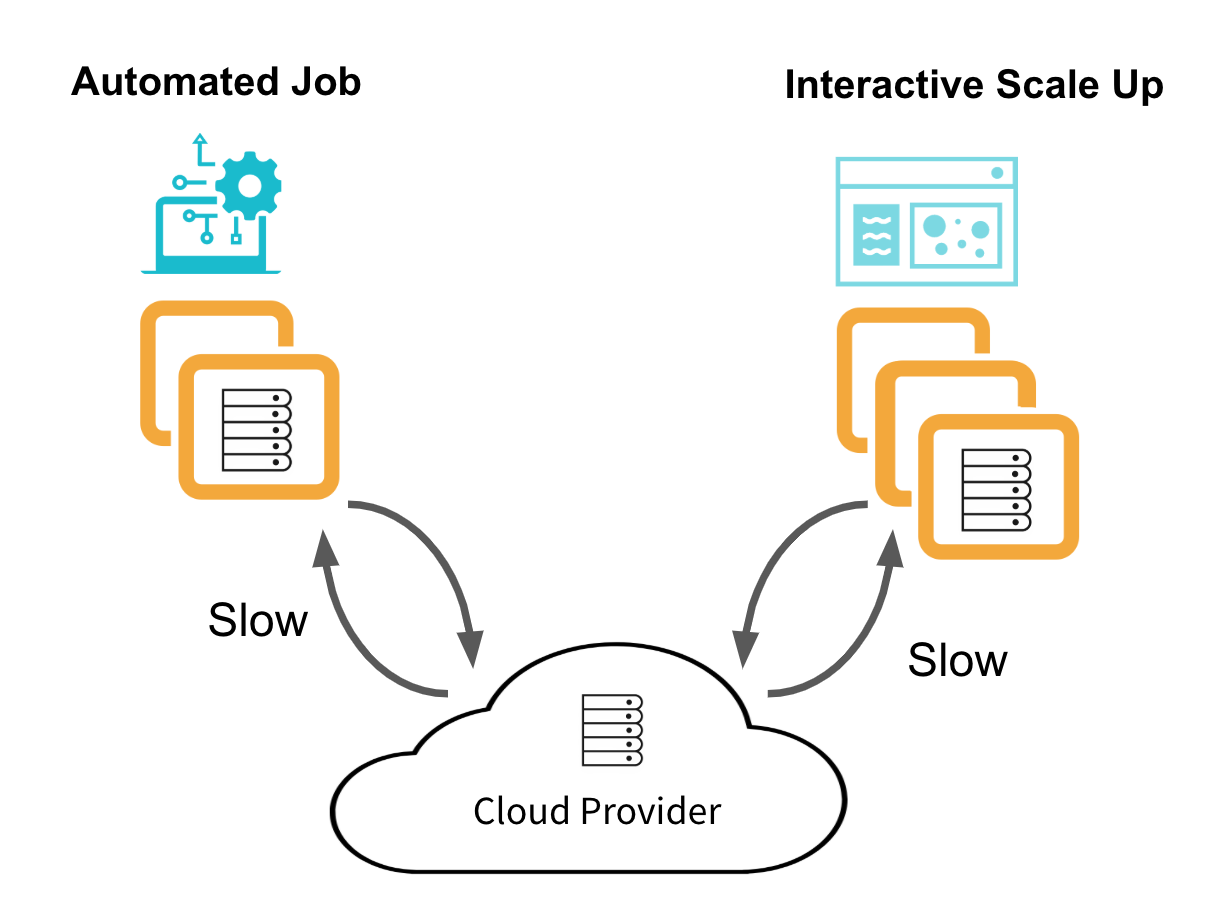
This is not sufficient for Data Engineers running short jobs. The cluster start time can dominate the job's total execution time. Nor is it sufficient for Data Analysts. Waiting for a cluster to scale up when running a large query slows down productivity.
A new architecture with Databricks Pools
Databricks introduces Pools, a managed cache of VM instances, to achieve this reduction in cluster start and auto-scaling times.
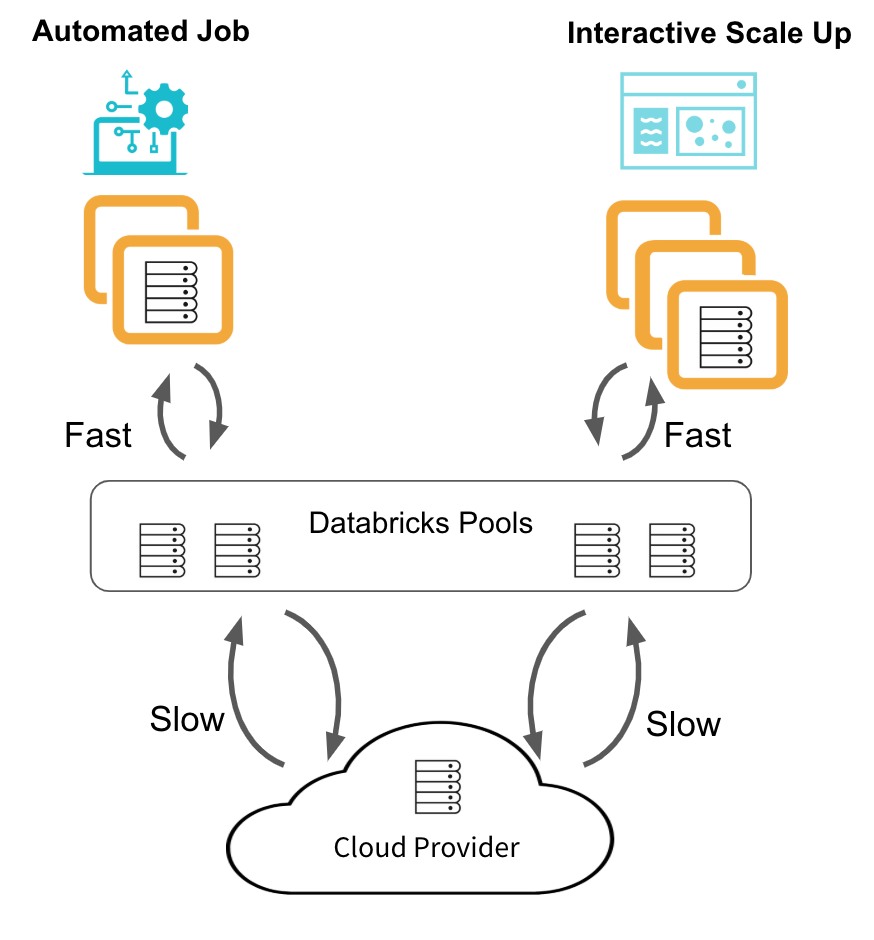
When a cluster attached to a pool needs VM instances, rather than requesting new ones from the cloud provider, it checks the pool. If there are enough idle instances in the pool, the cluster acquires them and starts or scales quickly. If there are not enough idle instances, the pool expands by allocating new instances from the cloud provider to satisfy the cluster's request. This will slow down the request, so it is important to maintain enough idle instances in the pool. When a pool cluster releases instances, they return to the pool and are free for other clusters to use. Only clusters attached to a pool can use that pool's idle instances.
The below diagram shows the typical lifecycle for Data Engineering job clusters and interactive Data Analytics clusters using Databricks Pools.
Cost control with Databricks Pools
Keeping idle VM instances in a Databricks Pool is great for performance, but not free. Databricks does not charge DBUs for idle instances not in use by a Databricks cluster, but cloud provider infrastructure costs do apply.
There are a few recommended ways to manage this cost. First, manually edit the size of your pool to meet your needs. If you're only running interactive workloads during business hours, make sure the pool's "Min Idle" instance count is set to zero after hours. Or if your automated data pipeline runs for a few hours at night, set the "Min Idle" count a few minutes before the pipeline starts and then revert it to zero afterwards. Alternatively, always keep a "Min Idle" of zero, but set the "Idle Instance Auto Termination" timeout to meet your needs. The first job run on the pool will start slowly, but subsequent jobs run within the timeout period will start quickly. When the jobs are done, all instance in the pool will terminate after the idle timeout period, avoiding cloud provider costs.
Optionally, you can also budget VM resources by setting a maximum capacity for the pool. This limits the sum of all idle instances and instances used by clusters attached to the pool.
Deploying a managed cache of VM instances via Databricks Pools
Getting started with Databricks Pools is easy. Click the Clusters icon ![]() in the sidebar, select the pools tab and click the "Create Pool" button.
in the sidebar, select the pools tab and click the "Create Pool" button.
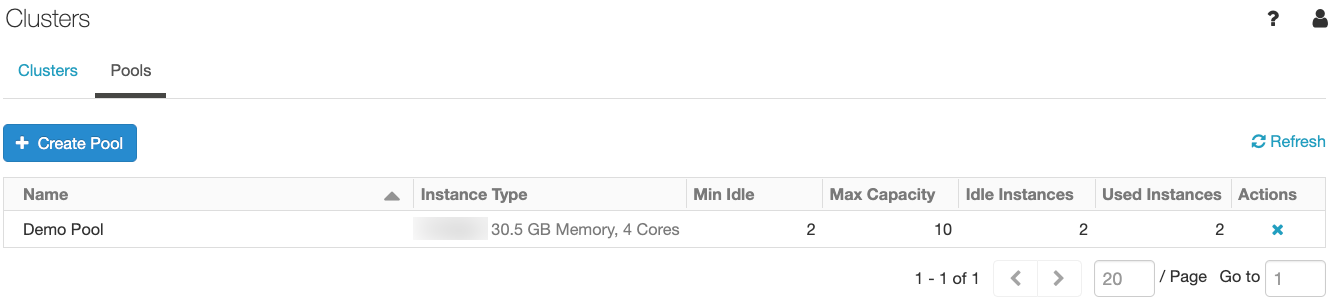
After you've created the pool, you can see the number of instances that are in use by clusters, idle and ready for use, and pending (i.e. idle, but not yet ready).

In order to use the idle instances in the pool, select the pool from the dropdown in the cluster create template. This works both for interactive clusters and automated jobs clusters. With a pool selected, the cluster will use the pool's instance type for both the driver and worker nodes.
Assuming there are enough idle instances warm in the pool - set via the "Min Idle" field during pool creation - the cluster will use them to accelerate its launch time. While the cluster is running, the pool will backfill more idle instances in order to maintain the minimum idle instance count. Once the cluster is done using the instances, they will return to the pool to be used by the next cluster. Idle instances above the minimum idle count are terminated after being idle for the "Idle Instance Auto Termination" timeout period (defaults to 60 minutes).
Conclusion
Databricks Pools increase the productivity of both Data Engineers and Data Analysts. With Pools, Databricks customers eliminate slow cluster start and auto-scaling times. Data Engineers can reduce the time it takes to run short jobs in their data pipeline, thereby providing better SLAs to their downstream teams. Data Analytics teams can scale out clusters faster to decrease query execution time, increasing the recency of downstream reporting. Pools allow teams to rapidly iterate and innovate and move them one step closer to real-time analytics. All of this is possible while reducing Databricks licensing costs, making the feature a no brainer to deploy.
Get started with Databricks Pools
To learn how to deploy the feature, please read Databricks Pools documentation here. If you already don't have Databricks, start a trial here and use the quick start guide here.
Related Resources
https://docs.databricks.com/clusters/instance-pools/index.html
https://www.databricks.com/glossary/what-is-databricks-runtime
https://docs.databricks.com/clusters/index.html
https://www.databricks.com/session/virtualizing-apache-spark
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.