Delivering and Managing a Cloud-Scale Enterprise Data Platform with Ease
Data is growing exponentially and organizations are building products to harness the data and provide services to their customers. However, this exponential growth cannot be sustained by an exponential growth in infrastructure spend or human capital cost.
Today, there are over a hundred services available in each of the major clouds (AWS, Azure) that can be used to build your data platform. And there are hundreds of enterprise services that also need to integrate with your data platform. Data leaders and platform administrators are tasked with providing the right set of services and products to fulfill the data needs of their organization. These services need to be on-demand, at scale, reliable, policy-compliant and within budget.
Complexities administering an organization-wide data platform
Data is the lifeblood of any organization. As organizations become more and more data-driven, every team in every line of business is trying to leverage the power of data to innovate on their products and services. How do you create an enterprise-wide data, analytics and ML platform that is easy to use for users while having the right visibility and control for admins?
Heterogeneous teams have heterogenous operations
Product and services teams want ready-to-use analytic tools, so they can get to work on the meaty parts of the problems that they are trying to solve.
Data science teams use data sets to build analytic models to answer hard questions about the business. They use notebooks, connecting them to databases or data lakes, reading log files potentially stored in a cloud or on-premise data stores and event streams. They often use tools that are most easily available on their laptops and work on a representative set of data to validate their models.
Data engineering teams, on the other hand, are trying to take these models into production so the insights from the models and apps are available 24/7 to the business. They need infrastructure that can scale to their needs. They need the right set of testing and deployment infrastructure to test out their pipelines before deploying them for production use.
Disjointed solutions are hard-to-manage solutions
Various teams end up building bespoke solutions to solve their problems as fast as possible. They deploy infrastructure that may not be suited for the needs of their workloads and may result in either starvation for workloads (under-provisioning) or runaway costs (over-provisioning). The infrastructure and tools may not be configured correctly to meet the compliance, security and governance policies set by the organization and admin teams have no visibility into it. While these teams have the right expertise to do this for traditional application development, they may not have the right expertise or tools to do this in the rapidly changing data ecosystem. The end result is a potpourri of solutions sprinkled across the organization, that lack the visibility and control needed to scale across the entire organization.
A simple-to-administer data platform
So what would it take to build a platform for data platform leaders that allows them to provide data environments for the analytic needs of product and services teams while retaining the visibility, control, and scale that allows them to sleep well at night? We focused on visibility, control, and scale as the key pillars of this platform.
Visibility – Audit and analyze all the activity in your account for full transparency
Typically, the data platform engineering team starts onboarding their workloads directly on the data platform they are managing. Initially, the euphoria of getting to a working state with these workloads overshadows the costs being incurred. However, as the number and scale of these workloads increase, so do resources and the cost of compute needed to process the data.
The conscientious administrators of the data platform look for ways to visualize the usage on the platform. They can visualize past usage and get an empirical understanding of the usage trends on the platform.
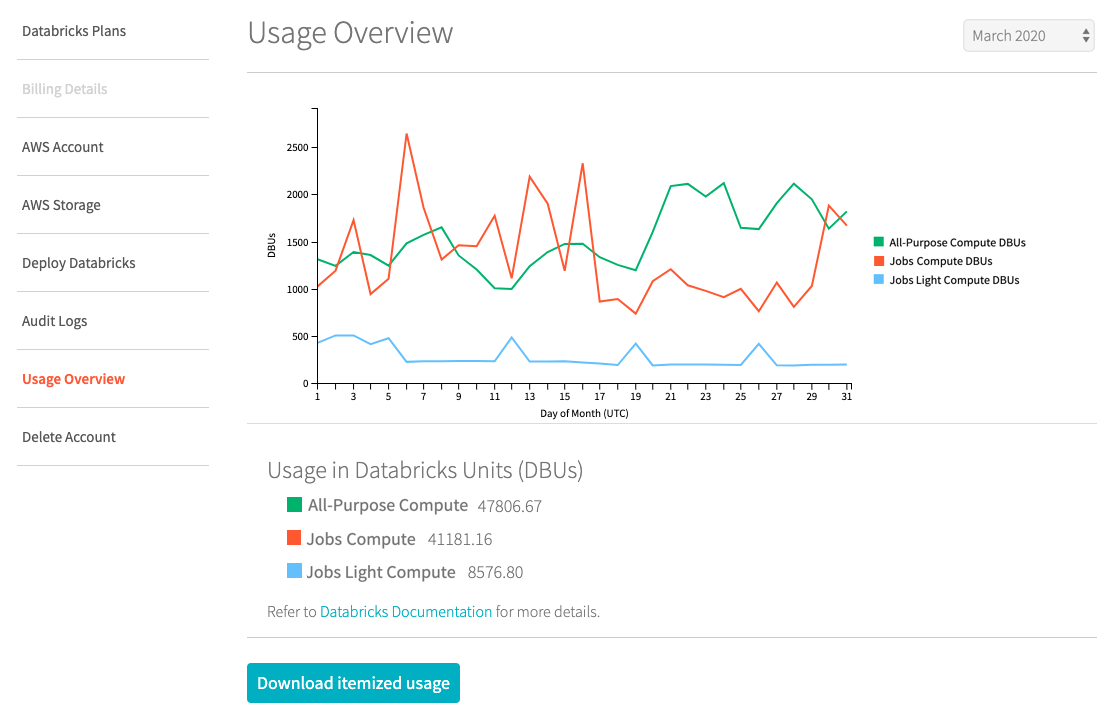
As more product and services teams are onboarded, the resulting explosion in usage quickly exceeds the allocated budget. The only viable way for the data platform administration team to run its business is to issue chargebacks to product teams for their usage. In order to do that, the admin needs access to the usage logs that are tagged with the right usage tags.
Over the course of operations during the year, there may be spikes in the usage of resources. It is hard to determine whether these spikes are expected changes in workloads or some unintended behavior — like a team running a job that has an error that causes unexpected use of resources. Detailed usage logs help identify the workloads and teams that caused the anomalous usage. Admin teams can then use detailed audit logs to analyze the events leading up to that usage. They can work with the respective team to get qualitative information about this usage and make a determination on the anomaly. In case it is a change in the usage patterns of the workloads they can set up automated means to classify this usage as ‘normal’ in the future. Similarly, if this usage is actually an anomaly, then they can set up monitoring and alerts to catch such anomalies in real-time in the future.
As data platform leaders plan budgets, detailed usage data from the past can be used to build out more accurate forecasts of costs, usage and return on investment.
Control – Set policies to administer users, control the budget and manage infrastructure
While visibility is great, when managing many teams, it is better to have proactive controls to ensure a policy-compliant use of the platform.
When new data scientists are unboarded, they may not have a good understanding of the underlying infrastructure that runs their models. They can be provided environments that are pre-provisioned with the right policy-mandated clusters, the right access controls, and the ability to view and analyze the results of their experiments.
Similarly, as part of automating data pipelines, data engineers create clusters on demand and kill them when not needed, so that infrastructure is used optimally. However, they may be creating clusters that are fairly large and do not conform to the IT policies of the organization. The admin can apply cluster policies for this team such that the clusters any users create will conform to the mandated IT policies. This allows the team to spin up the resources in a self-service and policy-compliant way, without any manual dependencies on admin.
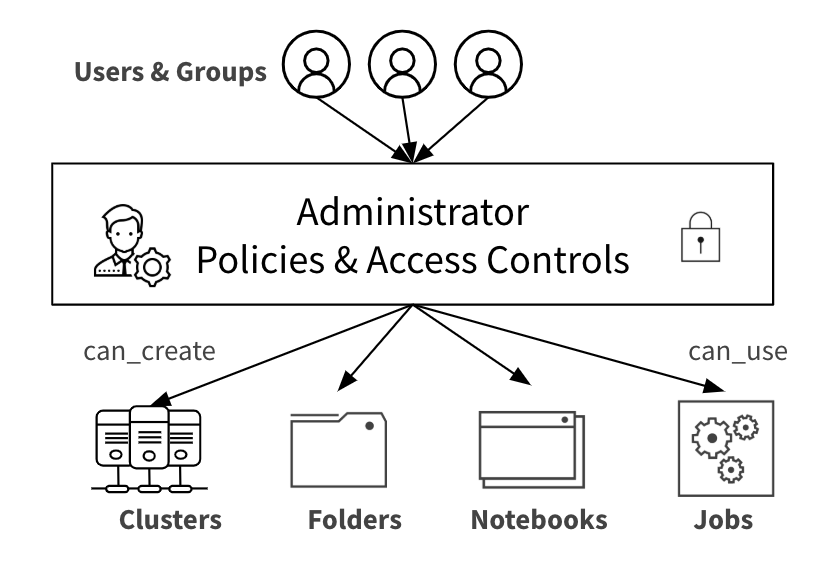
Furthermore, the admin can set bounds on the infrastructure being used by allocating pools of infrastructure that dynamically auto-scale for the team. This ensures that the team is only able to spin up resources from within the bounds of the pool. Additionally, the resources in the pool can be spun down when not in use, thereby optimizing the overall use of the infrastructure.
Scale - Extend and scale the platform to all your users, customers and partners
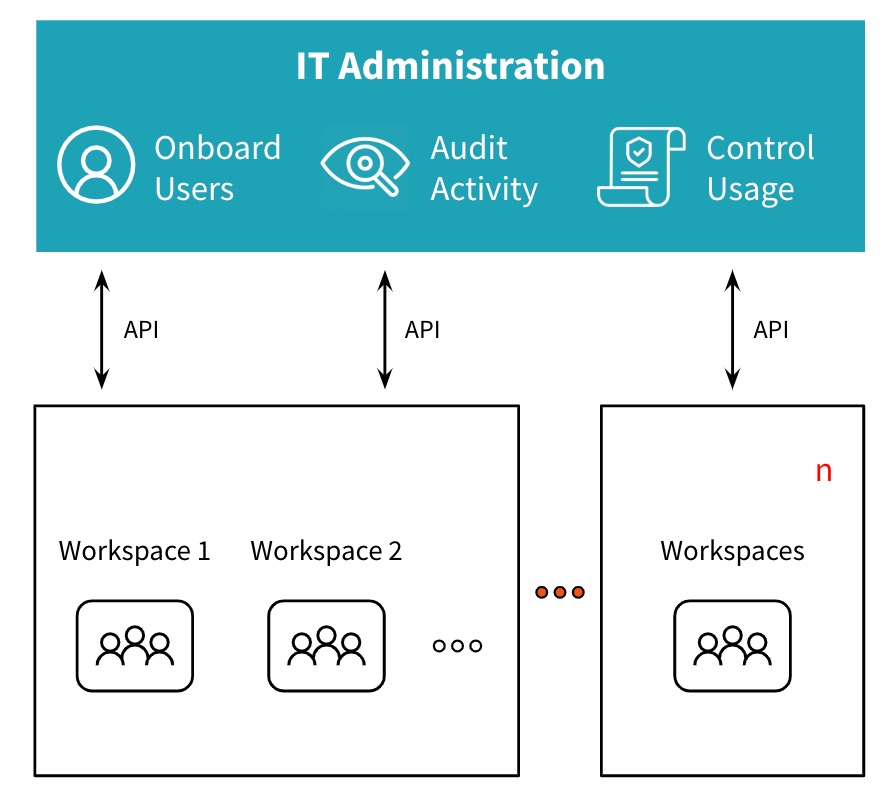
As hundreds of teams are onboarded to the data platform, team workspaces are needed to isolate teams soh that they can work collaboratively within their team without being distracted or affected by other teams working on the platform. The workspace can be fully configured for the team’s use, with notebooks, data sources, infrastructure, runtimes and integration with DevOps tools. With user provisioning and entitlements for users managed by trusted Identity Providers (IdPs) the Admin can ensure that the right set of users can access the right workspaces by using enterprise-wide Single Sign-On capabilities. This isolation and access mechanism ensures that hundreds of teams can co-exist on the same data platform in a systematic manner, allowing the admin to manage them easily and scale the platform across the organization worldwide.
All of the above mentioned capabilities of the platform should be available to admins both in an easy to use UI as well via a rich set of REST APIs. The APIs enable the admin to automate and make onboarding teams efficient and fast.
Use Databricks to effortlessly manage users and infrastructure
The Databricks platform has a number of these capabilities that help you provide a global-scale data platform to various product and services teams in your organization. The heterogeneity and scale of customers on the platform poses new challenges every day. We are building more into the Databricks platform so you can press the ‘easy button’ and enable consistent, compliant data environments across your organization on-demand.
Learn more about other steps in your journey to create a simple, scalable and production-ready data platform, ready the following blogs
Enabling Massive Data Transformation Across Your Organization
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.