COVID-19 Datasets Now Available on Databricks: How the Data Community Can Help
by Denny Lee
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Initially published April 14th, 2020; updated April 21st, 2020
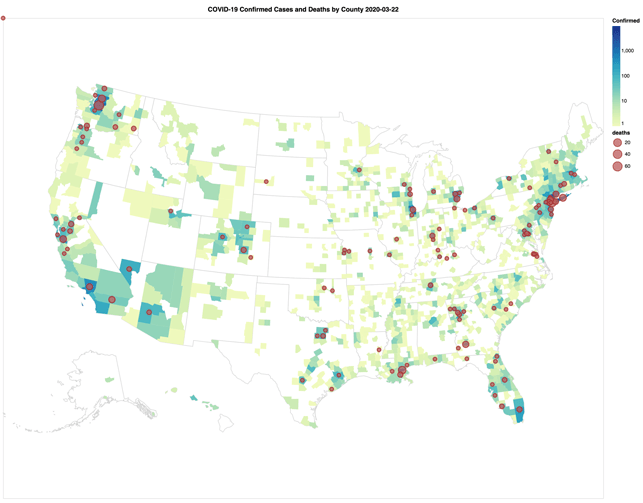
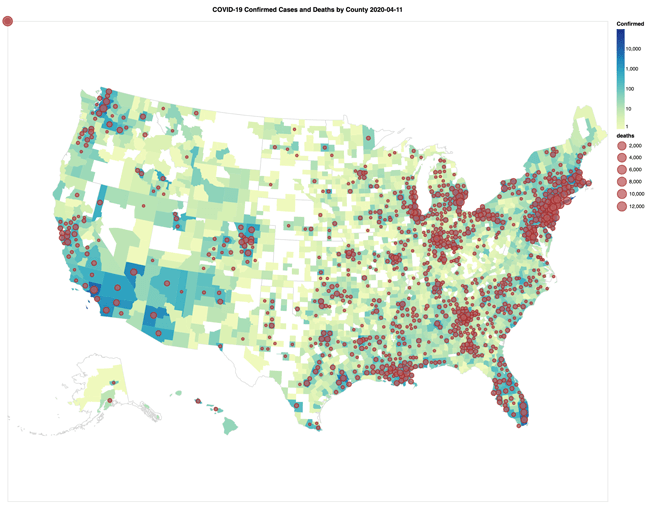
With the massive disruption of the current COVID-19 pandemic, many data engineers and data scientists are asking themselves “How can the data community help?" The data community is already doing some amazing work in a short amount of time including (but certainly not limited to) one of the most commonly used COVID-19 data sources: the 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE. The following animated GIF is a visual representation of the proportional number of confirmed cases (counties) and deaths (circles) spanning from March 22nd to April 14th.
https://www.youtube.com/watch?v=QjFZQyK2i2w
Other examples include Genomic epidemiology of novel coronavirus which provides real-time tracking of pathogen evolution (click to play the transmissions and phylogeny).
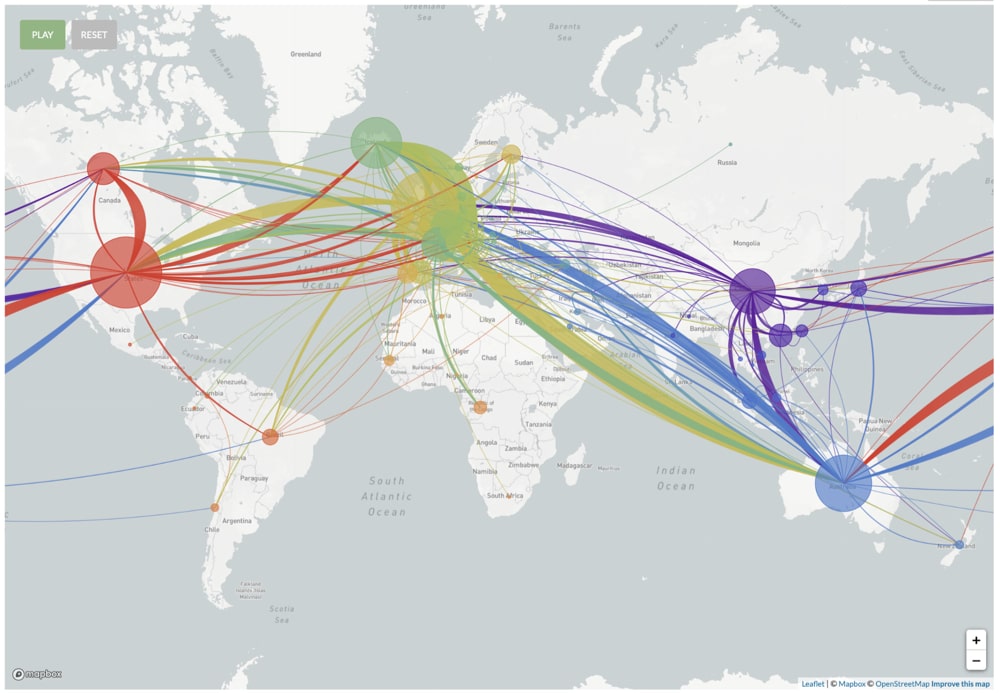
A powerful example of hospital resource utilization modeling includes the University of Washington’s Institute of Health and Metrics Evaluation (IHME) COVID-19 projections. The screenshot below provides the projected hospital resource utilization metrics, highlighting that peak resources were used on March 28th, 2020.
Figure 3: IHME COVID-19 projections for Italy
But how can I help?
We believe that overcoming COVID-19 is the world’s toughest problem at the moment, and to help make important decisions, it is important to understand the underlying data. So we’ve taken steps to enable anyone — from first-time data explorers to data professionals — to participate in the effort.
In late March, we began with a data analytics primer of COVID-19 datasets with our tech talk on Analyzing COVID-19: Can the Data Community Help? In this session, we performed exploratory data analysis and natural language processing (NLP) with various open source projects, including but not limited to Apache Spark™, Python, pandas, and BERT. We have also made these notebooks available for you to download and use in your own environment of choice, whether that is your own local Python virtual environment, cloud computing, or Databricks Community Edition.
For example, during this session we analyzed the COVID-19 Open Research Dataset Challenge (CORD-19) dataset and observed:
- There are thousands of JSON files, each containing the research paper text details including their references. The complexity of the JSON schema can make processing this data a complicated task. Fortunately, Apache Spark can quickly and automatically infer the schema of these JSON files and using this notebook, we save the thousands of JSON files into a few Parquet files to make it easier for the subsequent exploratory data analysis.
- As most of this text is unstructured, there are data quality issues including (but not limited to) correctly identifying the primary author’s country. In this notebook, we provide the steps to clean up this data and identify the ISO Alpha 3 country code so we can subsequently map the number of papers by primary author’s country.
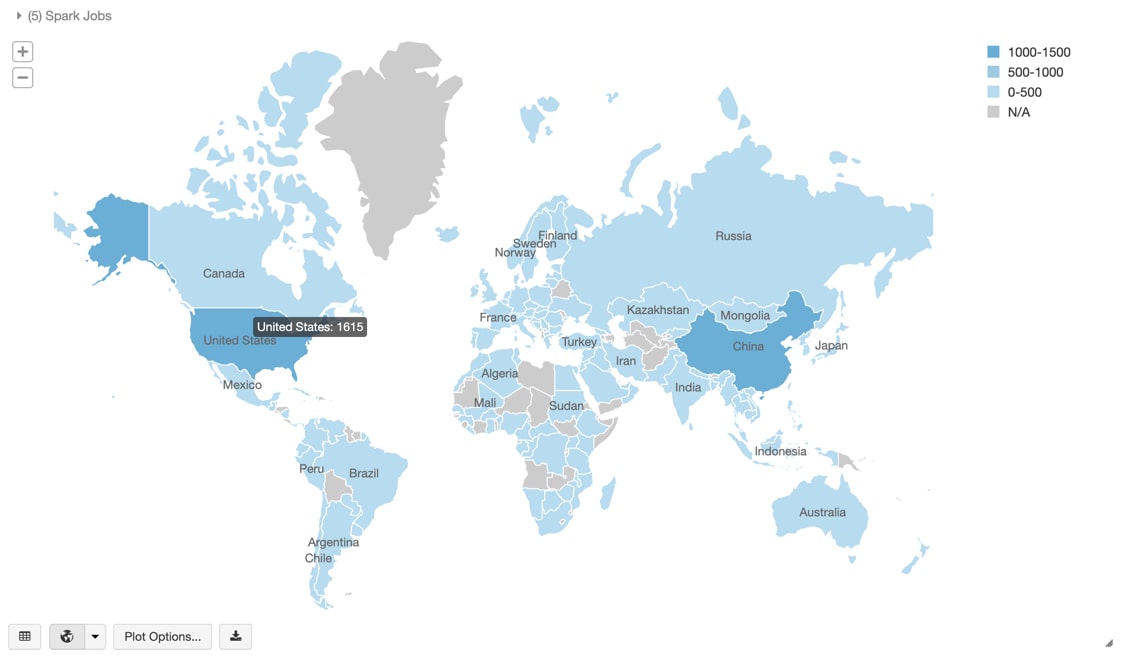
Figure 4: Number of COVID-19-related research papers by primary author’s country from Analyzing COVID-19: Can the Data Community Help?
- Upon cleaning up the data, we can apply various NLP algorithms to it to gain some insight and intuition into this data. This notebook performs various tasks including generalizing paper abstracts (one paper went from 7800 to 1100 characters) as well as creating the following word cloud based on the titles of these research papers.
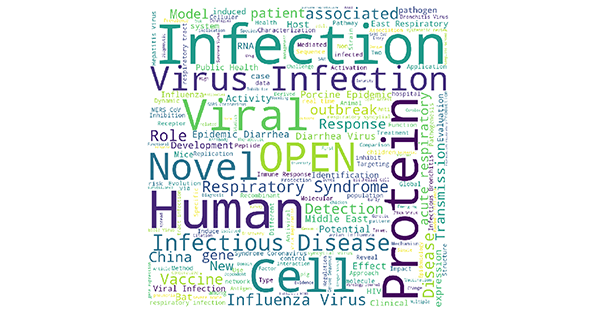
Word cloud based on COVID-19-related research paper titles from Analyzing COVID-19: Can the Data Community Help?
Show me the data!
As most data analysts, engineers, and scientists will attest, the quality of your data has a formidable affect on your exploratory data analysis. As noted in A Few Useful Things to Know about Machine Learning (October 2012):
"A dumb algorithm with lots and lots of data beats a clever one with modest amounts of it."
It is important to note that this quote is to emphasize the importance of having a large amount of high quality data as opposed to trivializing the many other important aspects of machine learning such as (but not limited to) the importance of feature engineering and data alone is not enough.
Many in the data community have been and are continuing to work expediently to provide various SARS-CoV-2 (the cause) and COVID-19 (the disease) datasets on Kaggle and GitHub including.
To make it easier for you to perform your analysis — if you’re using Databricks or Databricks Community Edition — we are periodically refreshing and making available various COVID-19 datasets for research (i.e. non-commercial) purposes. We are currently refreshing the following datasets and we plan to add more over time:
| /databricks-datasets/[location] | Resource |
| /../COVID/CORD-19/ | COVID-19 Open Research Dataset Challenge (CORD-19) |
| /../COVID/CSSEGISandData/ | 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE |
| /../COVID/ESRI_hospital_beds/ | Definitive Healthcare: USA Hospital Beds |
| /../COVID/IHME/ | IHME (UW) COVID-19 Projections |
| /../COVID/USAFacts/ | USA Facts: Confirmed | Deaths |
| /../COVID/coronavirusdataset/ | Data Science for COVID-19 (DS4C) (South Korea) |
| /../COVID/covid-19-data/ | NY Times COVID-19 Datasets |
Learn more with our exploratory data analysis workshops
Thanks to the positive feedback from our earlier tech talk, we are happy to announce that we are following up with a workshop series on exploratory data analysis in Python with COVID-19 datasets. The videos will be available on YouTube and the notebooks will be available at https://github.com/databricks/tech-talks for you to use in your environment of choice.
Intro to Python on Databricks
This workshop shows you the simple steps needed to program in Python using a notebook environment on the free Databricks Community Edition. Python is a popular programming language because of its wide range of applications, including data analysis, machine learning and web development. This workshop covers major foundational concepts to get you started coding in Python, with a focus on data analysis. You will learn about different types of variables, for loops, functions, and conditional statements. No prior programming knowledge is required.
Who should attend this workshop: Anyone and everyone, CS students and even non-technical folks are welcome to join. No prior programming knowledge is required. If you have taken Python courses in the past, this may be too basic for you.

Data Analysis with pandas
This workshop focuses on pandas, a powerful open-source Python package for data analysis and manipulation. In this workshop, you learn how to read data, compute summary statistics, check data distributions, conduct basic data cleaning and transformation, and plot simple data visualizations. We will be using the Johns Hopkins Center for Systems Science and Engineering (CSSE) Novel Coronavirus (COVID-19) dataset.
Who should attend this workshop: Anyone and everyone - CS students and even non-technical folks are welcome to join. Prior basic Python experience is recommended.
What you need: Although no prep work is required, we do recommend basic Python knowledge. If you’re new to Python, a great jump start is our Introduction to Python tutorial.

Machine Learning with scikit-learn
scikit-learn is one of the most popular open source machine learning libraries for data science practitioners. This workshop walks through the basics of machine learning, the different types of machine learning, and how to build a simple machine learning model. This workshop focuses on the techniques of applying and evaluating machine learning methods, rather than the statistical concepts behind them. We will be using data released by the Johns Hopkins Center for Systems Science and Engineering (CSSE) Novel Coronavirus (COVID-19).
Who should attend this workshop: Anyone and everyone - CS students and even non-technical folks are welcome to join. Prior basic Python and pandas experience is required. If you’re new to Python and pandas, watch the Introduction to Python tutorial and register for the Data Analysis with pandas tutorial.

Introduction to Apache Spark
This workshop covers the fundamentals of Apache Spark, the most popular big data processing engine. In this workshop, you will learn how to ingest data with Spark, analyze the Spark UI, and gain a better understanding of distributed computing. We will be using data released by the NY Times. No prior knowledge of Spark is required, but Python experience is highly recommended.
Who should attend this workshop: Anyone and everyone - CS students and even non-technical folks are welcome to join. Prior basic Python and pandas experience is required. If you’re new to Python and pandas, watch the Introduction to Python tutorial.

Gaining some insight into COVID-19 datasets
To help you jumpstart your analysis of COVID-19 datasets, we have also included additional notebooks in the tech-talks/samples folder for both the New York Times COVID-19 dataset and 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE (both available and regularly refreshed in /databricks-datasets/COVID).
The NY Times COVID-19 Analysis notebook includes the analysis of COVID-19 cases and deaths by county.
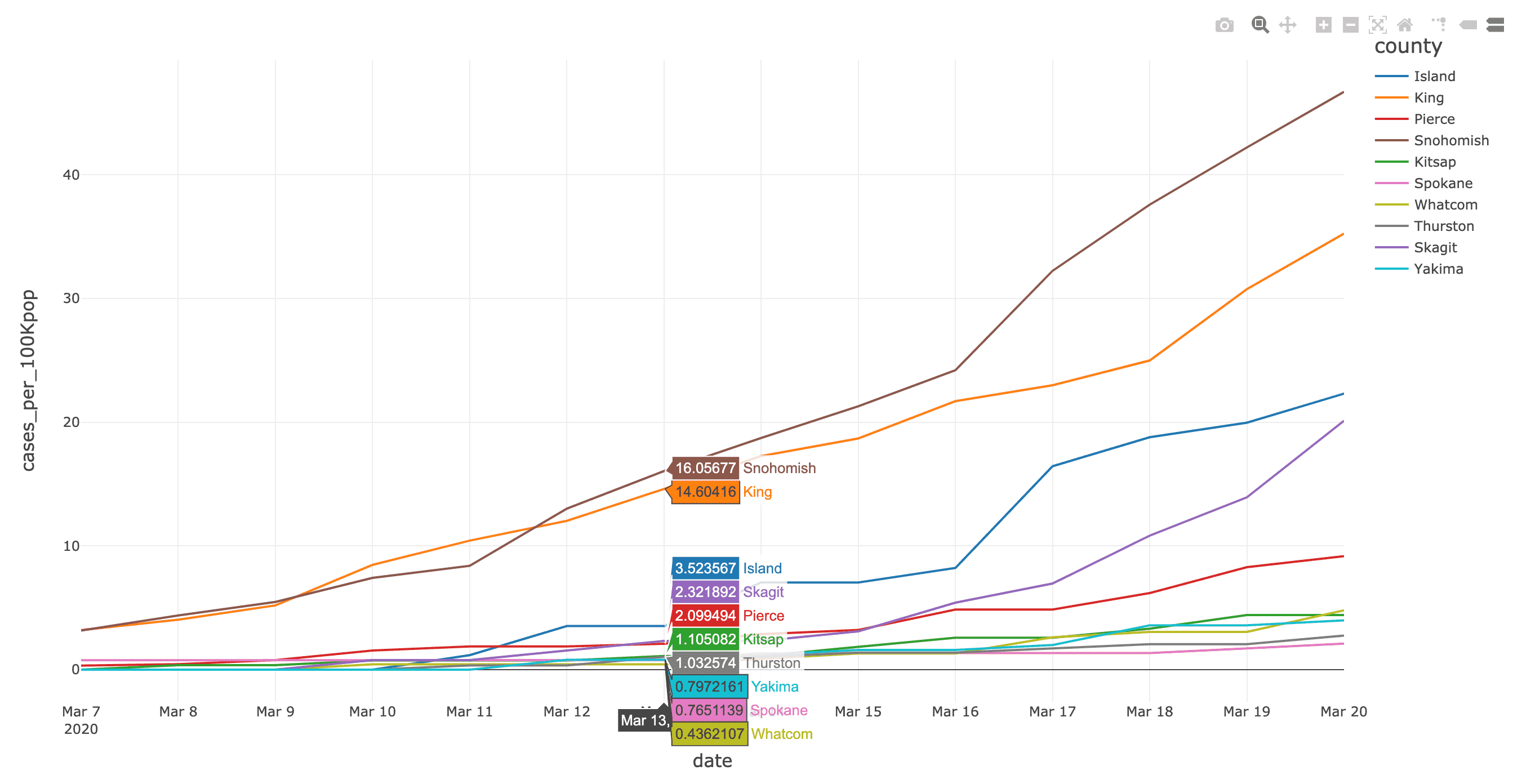
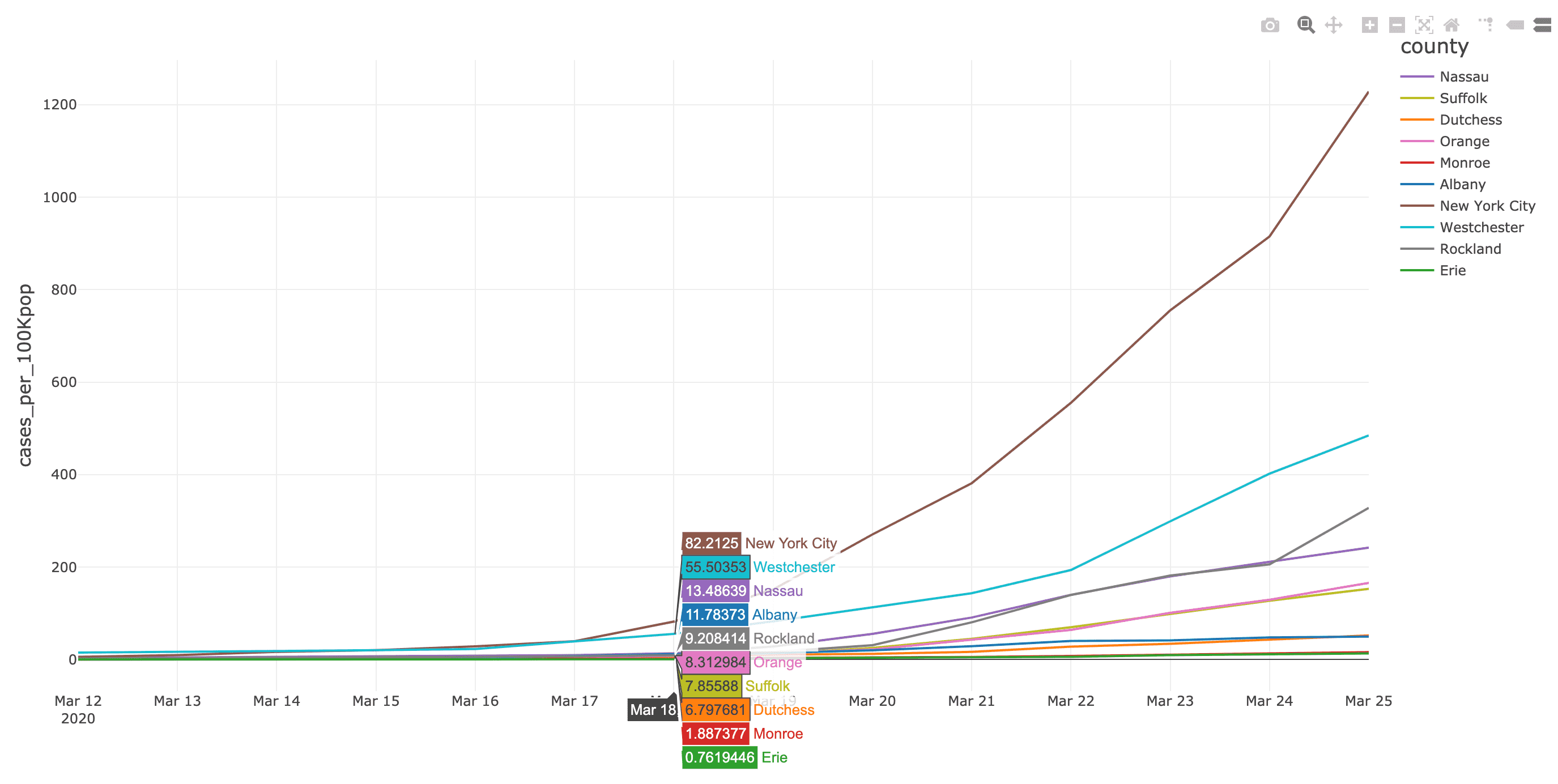
Some observations based on the JHU COVID-19 Analysis notebook include:
- As of April 11th, 2020, the schema of the JHU COVID-19 daily reports has changed three times. The preceding notebook includes a script that loops through each file, extracts the filename (to obtain the date), and merges the three different schemas together.
- It includes Altair visualizations to visualize the exponential growth of the number of cases and deaths related to COVID-19 in the United States both statically and dynamically via a slider bar.
As well, the NYT COVID-19 Analysis notebook includes county choropleth maps and bar graphs the COVID-19 confirmed cases and deaths (actual and proportional to the population respectively) for a two-week window around when educational facilities were closed for Washington (March 13th, 2020) and New York (March 18th, 2020) states.
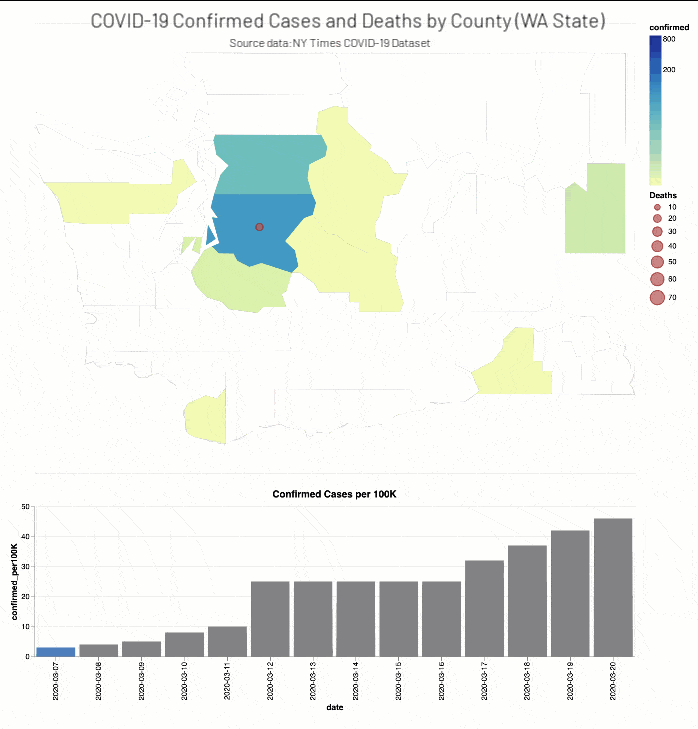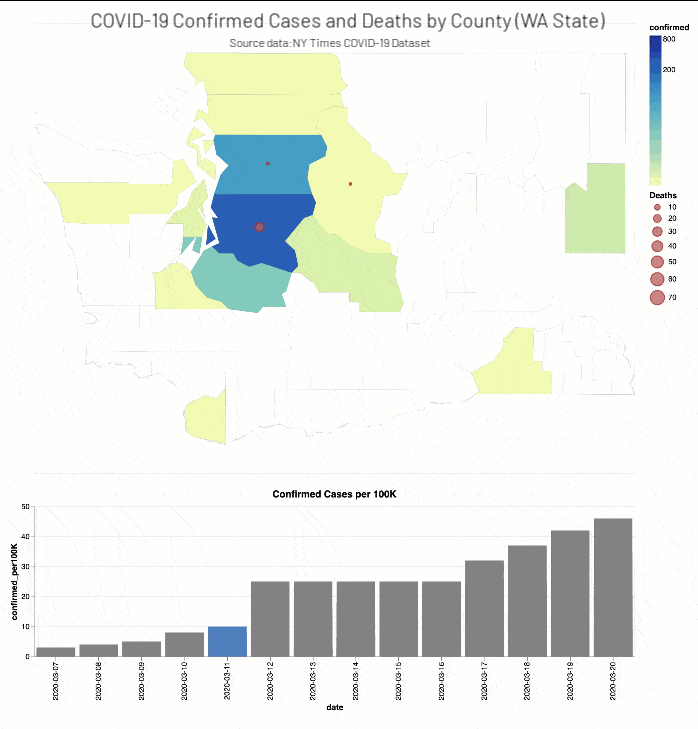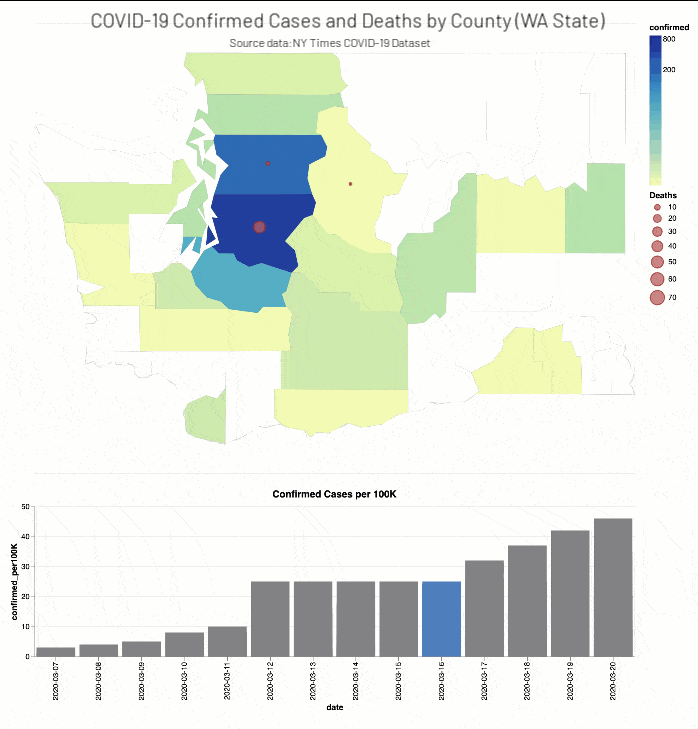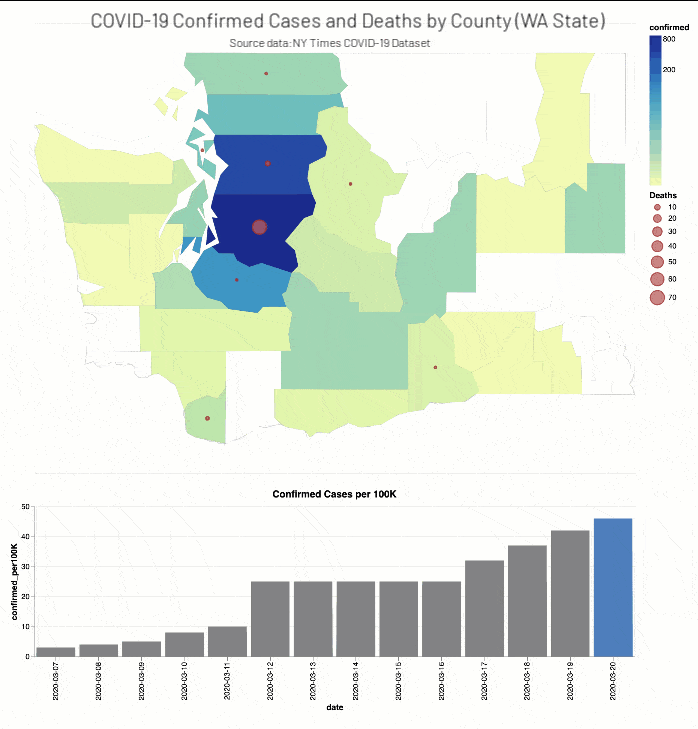
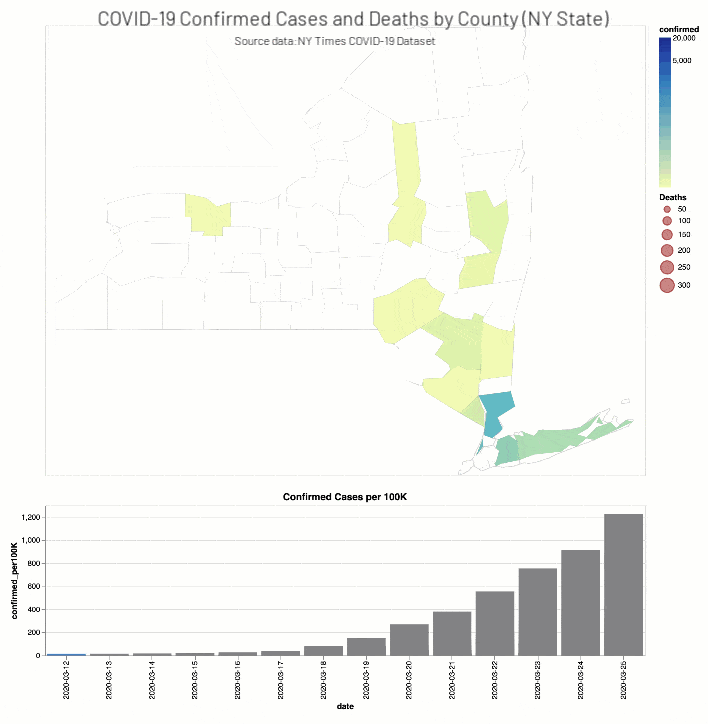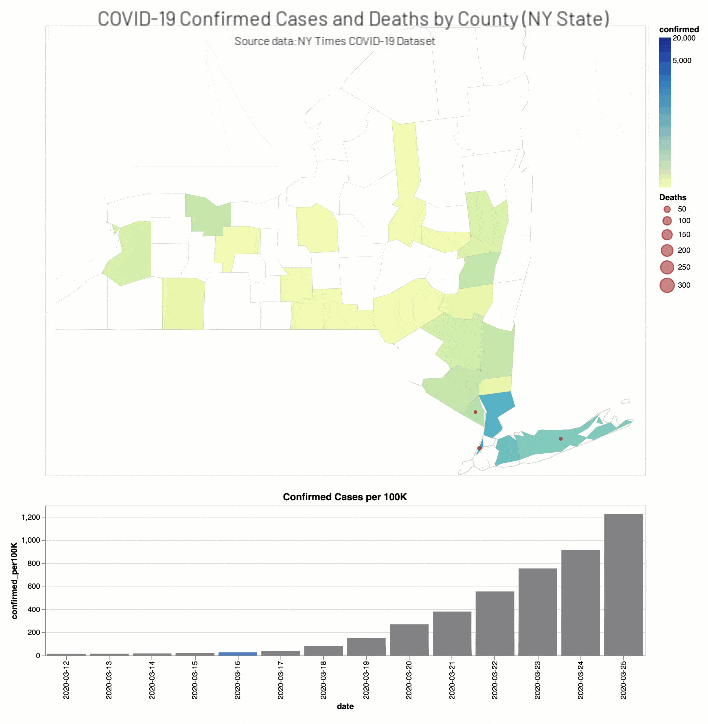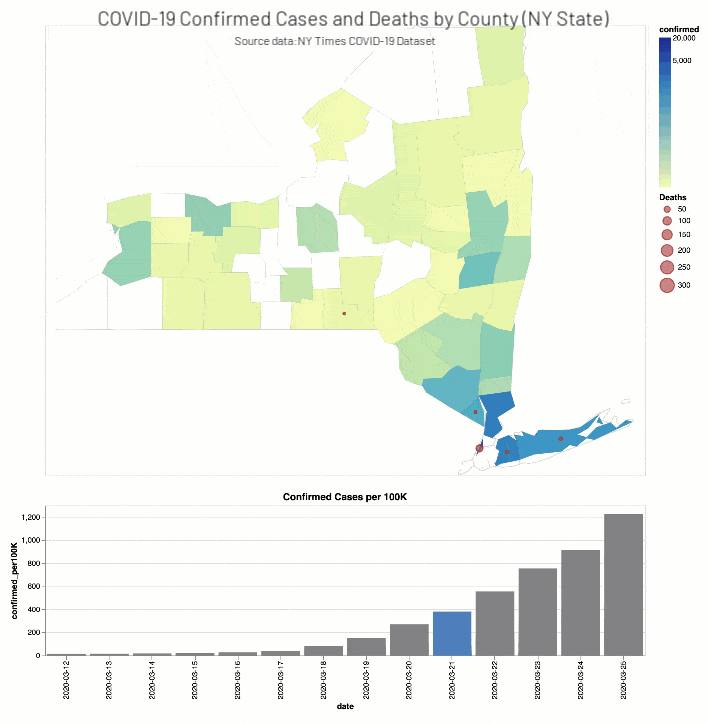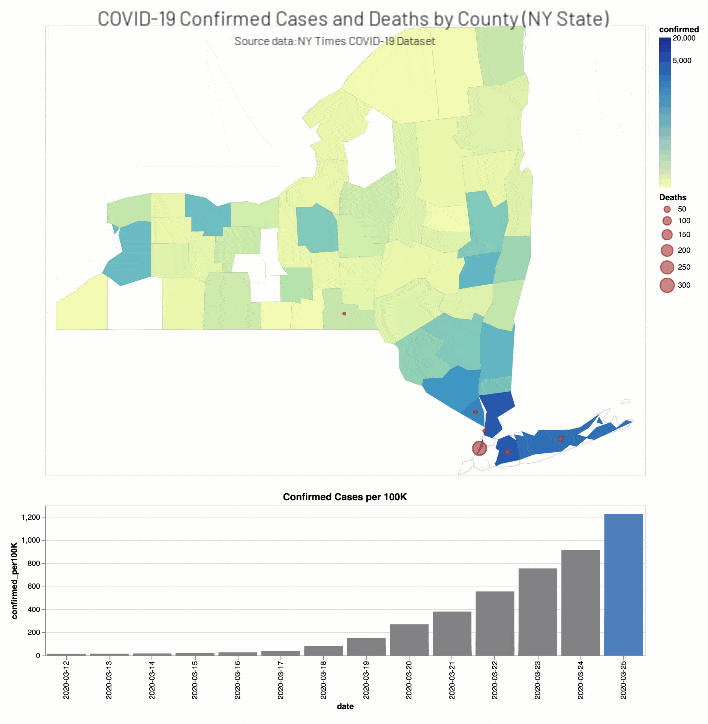
Discussion
The data community can help during this pandemic by providing crucial insight on the patterns behind the data: rate of growth of confirmed cases and deaths in each county, the impact to that growth where states applied social distancing earlier, understanding how we are flattening the curve by social distancing, etc. While at its core, COVID-19 is a medical problem — i.e. how do we save patients' lives — it is also an epidemiological problem where understanding the data will help the medical community make better decisions — e.g. how can we use data to make better public health policies to keep people from becoming patients.

O'Reilly Learning Spark Book
Free 2nd Edition includes updates on Spark 3.0, including the new Python type hints for Pandas UDFs, new date/time implementation, etc.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.