Shrink Training Time and Cost Using NVIDIA GPU-Accelerated XGBoost and Apache Spark™ on Databricks
Guest Blog by Niranjan Nataraja and Karthikeyan Rajendran of Nvidia. Niranjan Nataraja is a lead data scientist at Nvidia and specializes in building big data pipelines for data science tasks and creating mathematical models for data center operations and cloud gaming services. Karthikeyan Rajendran is the lead product manager for NVIDIA’s Spark team.
This blog will show how to utilize XGBoost and Spark from Databricks notebooks and the setup steps necessary to take advantage of NVIDIA GPUs to significantly reduce training time and cost. We illustrate the benefits of GPU-acceleration with a real-world use case from NVIDIA’s GeForce NOW team and show you how to enable it in your own notebooks.
About XGBoost
XGBoost is an open source library that provides a gradient boosting framework usable from many programming languages (Python, Java, R, Scala, C++ and more). XGBoost can run on a single machine or on multiple machines under several different distributed processing frameworks (Apache Hadoop, Apache Spark, Apache Flink). XGBoost models can be trained on both CPUs and GPUs. However, data scientists on the GeForce NOW team run into significant challenges with cost and training time when using CPU-based XGBoost.
GeForce NOW Use Case
GeForce NOW is NVIDIA’s cloud-based, game-streaming service, delivering real-time gameplay straight from the cloud to laptops, desktops, SHIELD TVs, or Android devices. Network traffic latency issues can affect a gamer’s user experience. GeForce NOW uses an XGBoost model to predict the network quality of multiple internet transit providers so a gamer’s network traffic can be routed through a transit vendor with the highest predicted network quality. XGBoost models are trained using gaming session network metrics for each internet service provider. GeForce NOW generates billions of events per day for network traffic, consisting of structured and unstructured data. NVIDIA’s big data platform merges data from multiple sources and generates a network traffic data record for each gaming session which is used as training data.
As network traffic varies dramatically over the course of a day, the prediction model needs to be re-trained frequently with the latest GeForce NOW data. Given a myriad of features and large datasets, NVIDIA GeForce NOW data scientists rely upon hyperparameter searches to build highly accurate models. For a dataset of tens of million rows and a non-trivial number of features, CPU model training with Hyperopt takes more than 20 hours on a single AWS r5.4xlarge CPU instance. Even with a scale-out approach using 2 CPU server instances, the training latency requires 6 hours with spiraling infrastructure costs.
Unleashing the Power of NVIDIA GPU-accelerated XGBoost
A recent NVIDIA developer blog illustrated the significant benefits of GPU-accelerated XGBoost model training. NVIDIA data scientists followed a similar approach to achieve a 22x speed-up and 8x cost savings compared to CPU-based XGBoost. As illustrated in Figure 1, a GeForce NOW production network traffic data dataset with 40 million rows and 32 features took only 18 minutes on GPU for training when compared to 3.2 hours (191 minutes) on CPU. In addition, the right hand side of Figure 1 compares CPU cluster costs and GPU cluster costs that include both AWS instances and Databricks runtime costs.
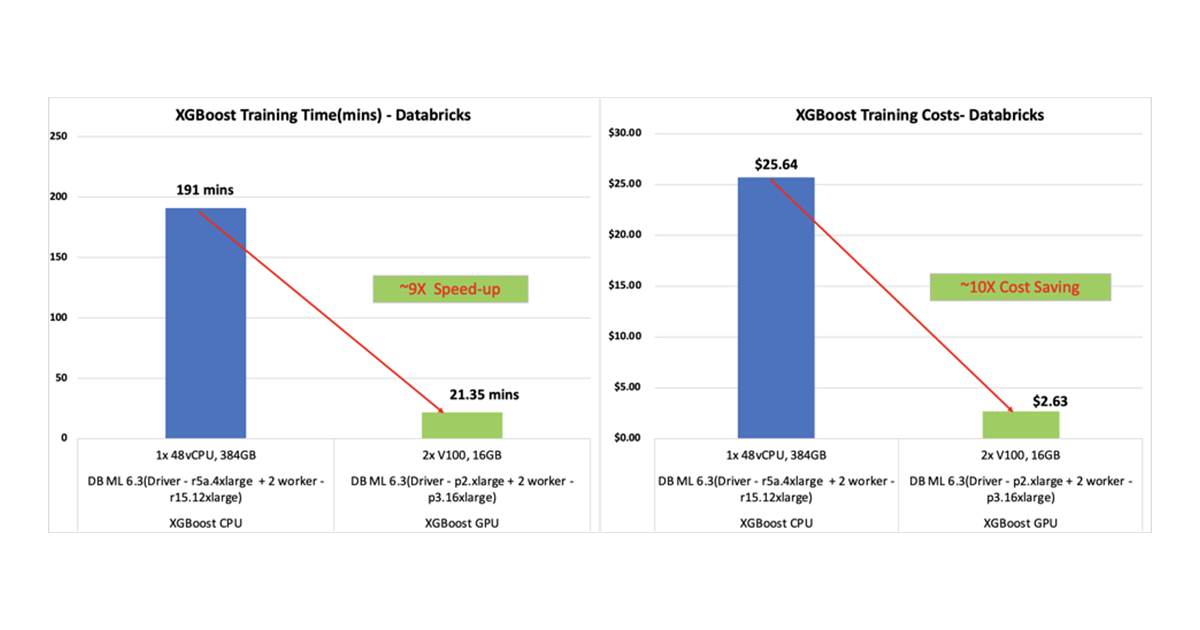
Figure 1: Network quality prediction training on GPU vs. CPU
As for model performance, the trained XGBoost models were compared on four different metrics.
- Root mean squared error
- Mean absolute error
- Mean absolute percentage error
- Correlation coefficient
The NVIDIA GPU-based XGBoost model has similar accuracy in all these metrics.
Now that we have seen the performance and cost savings, next we will discuss the setup and best practices to run a sample XGBoost notebook on a Databricks GPU cluster.
Quick Start on NVIDIA GPU-accelerated XGBoost on Databricks
Databricks supports XGBoost on several ML runtimes. Here is a well-written user guide for running XGBoost on single node and multiple nodes.
To run XGBoost on GPU, you only need to make the following adjustments:
- Set up a Spark cluster with GPU instances (instead of CPU instances)
- Modify your XGBoost training code to switch `tree_method` parameter from `hist` to `gpu_hist`
- Set up data loading
Set Up NVIDIA GPU Cluster for XGBoost Training
To conduct NVIDIA GPU-based XGBoost training, you need to set up your Spark cluster with GPUs and the proper Databricks ML runtime.
- We used a p2.xlarge (61.0 GB memory, 1 GPU, 1.22 DBU) instance for the driver node and two p3.2xlarge (61.0 GB memory, 1 GPU, 4.15 DBU) instances for the worker nodes.
- We chose 6.3 ML (includes Apache Spark 2.4.4, GPU, Scala 2.11) as our Databricks runtime version. Any Databricks ML runtime with GPUs should work for running XGBoost on Databricks.
Code Change on `tree_method` Parameter
After starting the cluster, in your XGBoost notebook you need to change the treemethod parameter from hist to gpu_hist.
For CPU-based training:
For GPU-based training:
Getting Started with GPU Model Training
NVIDIA’s GPU-accelerated XGBoost helped GeForce NOW meet the service-level objective of training the model every eight hours, and reduced costs significantly. Switching from CPU-based XGBoost to a GPU-accelerated version was very straightforward. If you’re also struggling with accelerating your training time or reducing your training costs, we encourage you to try it!
Watch this space to learn about new Data Science use-cases to leverage GPUs and Apache Spark 3.0 version on Databrick 7.x ML runtimes.
You can find the GeForce NOW PySpark notebook hosted on GitHub. The notebook uses hyperopt for hyperparameter search and DBFS's local file interface to load onto worker nodes.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.