Automating away engineering on-call workflows at Databricks
by Andrew Nitu
A Summer of Self-healing
This summer I interned with the Cloud Infrastructure team. The team is responsible for building scalable infrastructure to support Databricks’s multi-cloud product, while using cloud-agnostic technologies like Terraform and Kubernetes. My main focus was developing a new auto-remediation service, Healer, which automatically repairs our Kubernetes infrastructure to improve our service availability and reduce on-call burden.
Automatically Reducing Outages and Downtime
The Cloud Infra team at Databricks is responsible for underlying compute infrastructure for all of Databricks, managing thousands of VMs and database instances across clouds and regions. As components in a distributed system, these cloud-managed resources are expected to fail from time to time. On-call engineers sometimes perform repetitive tasks to fix these expected incidents. When a PagerDuty alert fires, the on-call engineer manually addresses the problem by following a documented playbook.
Though ideally we'd like to track down and fix the root cause of every issue, to do so would be prohibitively expensive. For this long tail of issues, we instead rely on playbooks that address the symptoms and keep them in check. And in some cases, the root cause is a known issue with one of the many open-source projects we work with (like Kubernetes, Prometheus, Envoy, Consul, Hashicorp Vault), so a workaround is the only feasible option.
On-call pages require careful attention from our engineers. Databricks engineering categorizes issues based on priority. Lower-priority issues will only page during business hours (i.e. engineers won't be woken up at night!). For example, if a Kubernetes node is corrupt in our dev environment, the on-call engineer will only be alerted the following morning to triage the issue. Since Databricks engineering is distributed worldwide (with offices in San Francisco, Toronto, and Amsterdam) and most teams are based out of a single office, an issue with the dev environment can impede certain engineers for hours, decreasing developer productivity.
We are always looking for ways to reduce our keeping-the-lights-on (KTLO) burden, so designing a system that responds to alerts without human intervention by executing engineer-defined playbooks makes a lot of sense to manage resources at our scale. We set out to design a system that would help us address these systemic concerns.
Self-healing Architecture
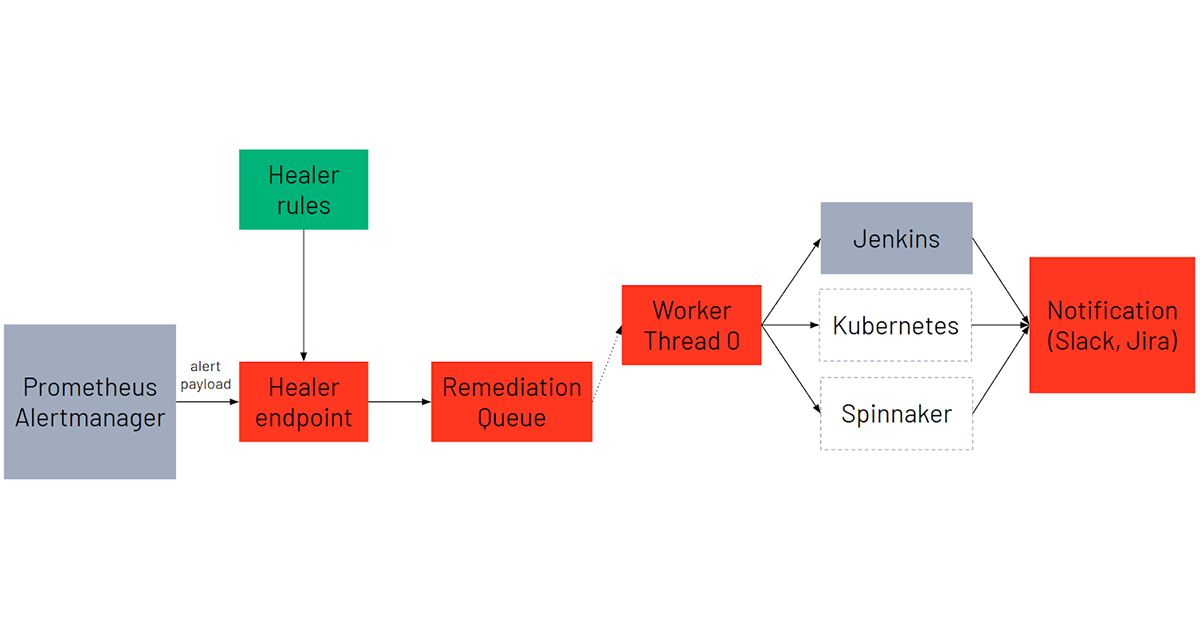
Healer is designed using an event-driven architecture that autonomously repairs the Kubernetes infrastructure. Our alerting system (Prometheus, Alertmanager) monitors our production infrastructure and fires alerts based on defined expressions. Healer runs as a backend service listening to HTTP requests from Alertmanager with alert payloads.
Using the alert metadata, Healer constructs the appropriate remediation based on the alert type and the alert labels. A remediation dictates what the remediation action will be as well as any parameters needed.
Each remediation is scheduled onto a worker execution thread pool. The worker thread will run the respective remediation by making calls to the appropriate service and then monitor the remediation for completion. In practice, this could be kicking off a Jenkins, Kubernetes, or Spinnaker job that automates the manual script workflow. We choose to support these frameworks, because they provide Databricks engineers with a wide ability to customize actions in reaction to the alerts.
Once the remediation completes, JIRA and Slack notifications are sent to the corresponding team confirming remediation task completion.
Healer can be easily extended with new kinds of remediations. Engineering teams outside of Cloud Infra can onboard remediations jobs that integrate with their service alerts, taking needed actions to recover from incidents, reducing on-call load generally across engineering.
Example Use Case
One use case for Healer is for remediating low disk space on our Kubernetes nodes. The on-call engineer is notified of this problem by an alert called “NodeDiskPressure”. To remedy NodeDiskPressure, an on-call engineer would connect to the appropriate node and execute a docker image prune command.
To automate this, we first develop an action to be triggered by Healer; we define a Jenkins job called DockerPruneNode, which automates the manual steps equivalent to connecting to a node and executing docker image prune. We then configure a Healer remediation to resolve NodeDiskPressure alerts automatically by defining a Healer rule that binds an exact remedy (DockerPruneNode) given an alert and its parameters.
Below is an example of how a NodeDiskPressure alert gets translated into a specific remediation including the job to be run and all the needed parameters. The final remediation object has three “translated” params taken from the alert as well as one “static” hard-coded param.
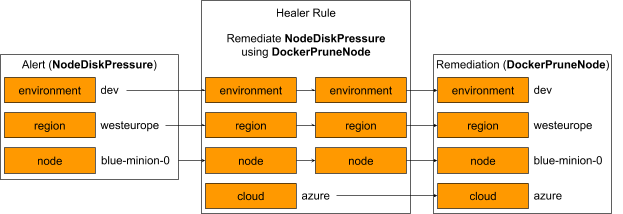
The configuration also has a few other parameters which engineers can configure to tune the exact behavior of the remediation. They are omitted here for brevity.
After defining this rule, the underlying issue is fully automated away, allowing on-call engineers can focus on other more important matters!
Future Steps
Currently Healer is up, running, and improving availability of our development infrastructure. What do next steps for the service look like?
Initially, we plan to onboard more of the Cloud Infra team’s use cases. Specifically, we are looking at the following use cases:
- Support fine-grained auto-scaling to our clusters by leveraging existing system usage alerts (CPU, memory) to trigger a remediation that will increase cluster capacity.
- Terminate and reprovision Kubernetes nodes that are identified as unhealthy.
- Rotate service TLS certifications when they are close to expiring.
Furthermore, we want to continue to push adoption of this tool within the engineering organization and help other teams to onboard their use cases. This general framework can be extended to other teams to reduce their on-call load as well.
I am looking forward to seeing what other incidents Healer can help remediate for Databricks in the future!
Special thanks for a great internship experience to my mentor Ziheng Liao, managers Nanxi Kang and Eric Wang, as well as the rest of the cloud team here at Databricks!
I really enjoyed my summer at Databricks and encourage anyone looking for a challenging and rewarding career in platform engineering to join the team. If you are interested in contributing to our self-healing architecture, check out our open job opportunities!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.