Introducing the Next-Generation Data Science Workspace
At today’s Spark + AI Summit 2020, we unveiled the next generation of the Databricks Data Science Workspace: An open and unified experience for modern data teams.
Existing solutions make data teams choose from three bad options. Giving data scientists the freedom to use any open-source tools on their laptops doesn’t provide a clear path to production and governance and creates compliance risks. Simply hosting those same tools in the cloud may solve some of the data privacy and security issues but doesn’t provide a clear path to production, nor improve productivity and collaboration. Finally, the most robust and scalable DevOps production environments can hinder innovation and experimentation by slowing data scientists down.
The next-generation Data Science Workspace on Databricks navigates these trade-offs to provide an open and unified experience for modern data teams. Specifically, it will provide you with the following benefits:
- Open and collaborative notebooks on a secure and scalable platform: Databricks is built on the premise that developer environments need to be open and collaborative. Because Databricks is rooted in open source, your tools of choice are made available on an open and collaborative platform capable of running all your analytics workloads at massive big data scale while helping you meet security and compliance needs. With native support for the Jupyter notebook format, the next-generation Data Science Workspace eliminates the trade-off between open standards and collaborative features provided by Databricks.
- Best-of-breed developer environment for Git-based collaboration and reproducibility: The industry is already leveraging best practices for robust code management in complex settings, and they are Git based. So we further integrated our platform with the Git ecosystem to help bring those best practices to data engineering and data science, where reproducibility is becoming more and more important. To facilitate this integration, we’re introducing a new concept called Databricks Projects. This will allow data teams to keep all project dependencies in sync via Git repositories.
- Low-friction CI/CD pipelines from experimentation to production deployments: With a new API surface based on the aforementioned Git-based Projects functionality, we’re introducing new capabilities to more seamlessly integrate developer workflows with automated CI/CD pipelines. This will allow data teams to take data science and ML code from experimentation to production faster, leveraging scalable production jobs, MLflow Model Registry, and new model serving capabilities — all on an open and unified platform that can scale to meet any use case.
We’re very excited about bringing these innovations to the Unified Data Analytics Platform. Over the past few years, we continuously gathered feedback from thousands of users to help shape our road map and design these features. In order to enable this new experience, we’ll release new capabilities in phases, as described below.
Watch Spark + AI Summit Keynotes here
Available in preview: Git-based Databricks Projects
First, we’re introducing a new Git-based capability named Databricks Projects to help data teams keep track of all project dependencies including notebooks, code, data files, parameters, and library dependencies via Git repositories (with support for Azure DevOps, GitHub and BitBucket as well as newly added support for GitLab and the on-premises enterprise/server offerings of these Git providers).
Databricks Projects allow practitioners to create new or clone existing Git repositories on Databricks to carry out their work, quickly experiment on the latest data, and easily access the scalable computing resources they need to get their job done while meeting security and compliance needs.
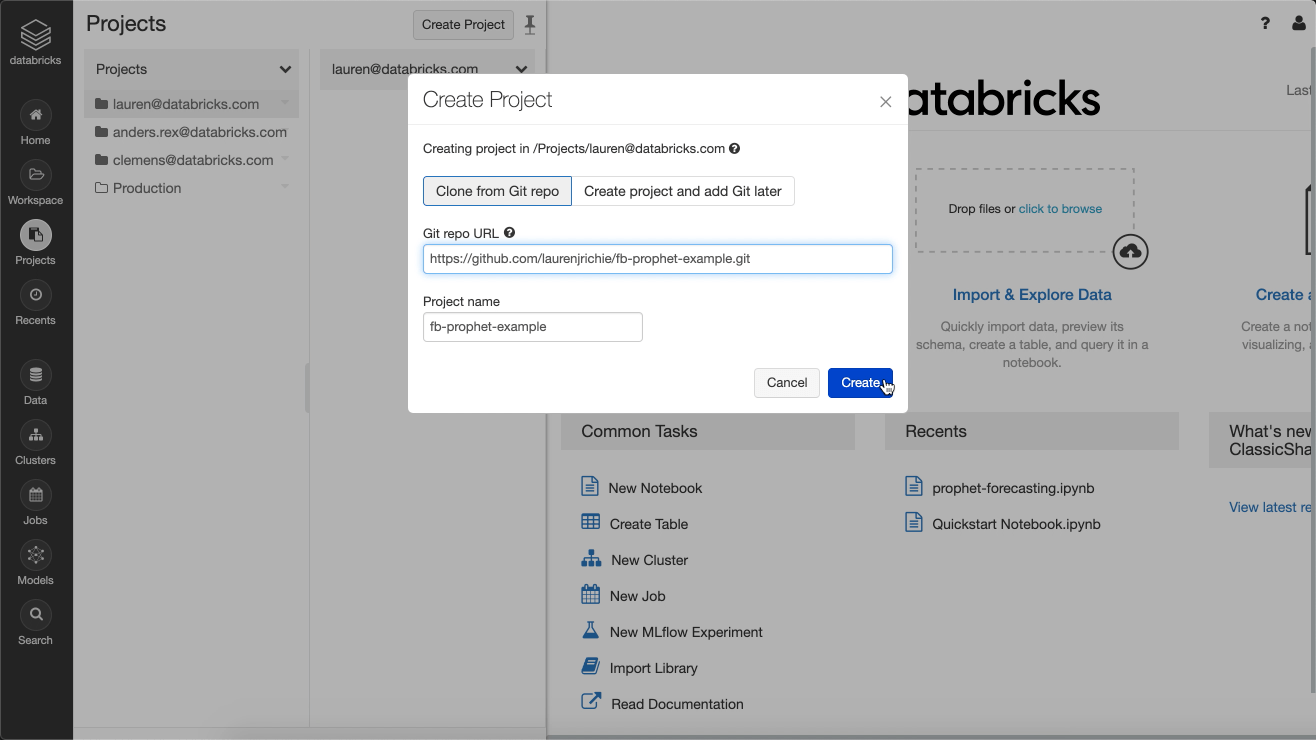
Figure 1: Databricks Projects allows data teams to quickly create or clone existing Git repositories as a project.
This also means that exploratory data analysis, modeling experiments and code reviews can be done in a robust, collaborative and reproducible way. Simply create a new branch, edit your code in open and collaborative notebooks, commit and push changes.
Figure 2: The new dialog for Databrick's Git-based Projects allows developers to switch between branches, create new branches, pull changes from a remote repository, stage files, and commit and push changes.
In addition, this will also help accelerate the path from experimentation to production by enabling data engineers and data scientists to follow best practices of code versioning and CI/CD. As part of the new Projects feature, a new set of APIs allows developers to set up robust automation to take data science and ML code from experimentation to production faster.
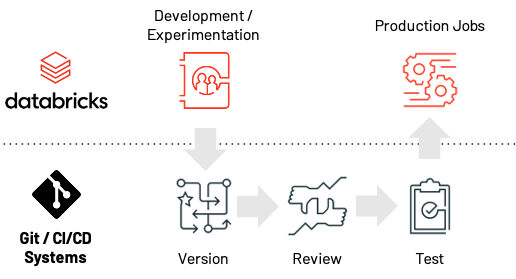
Figure 3: With Git-based Projects and associated APIs, the new Databricks Data Science Workspace makes the path from experimentation to production easier, faster and more reliable.
As a result, setting up CI/CD pipelines to manage data pipelines, keep critical dashboards up to date, or iteratively train and deploy new ML models to production has never been this seamless. Data engineers and data scientists using the Git-based Projects feature ensure that their code is delivered to repositories in an easy and timely manner, where Git automation can pick up and improve reliability and availability of production systems by performing tests before the code is deployed to production Projects on Databricks.
This enables a variety of use cases, from performing exploratory data analysis, to creating dashboards based on the most recent data sets, training ML models and deploying them for batch, streaming or real-time inference — all on an open and unified platform that can scale to meet demanding business needs.
Coming soon: Project-scoped environment configuration with Conda
At the intersection of Git-based Projects and environment management is the ability to store your environment configuration alongside your code. We’ll integrate the Databricks Runtime for Machine Learning with Projects to automatically detect the presence of environment configuration files (e.g., requirements.txt or conda.yml) and activate an environment scoped to your project. This means, you’ll no longer have to worry about installing library dependencies, such as NumPy, yourself.
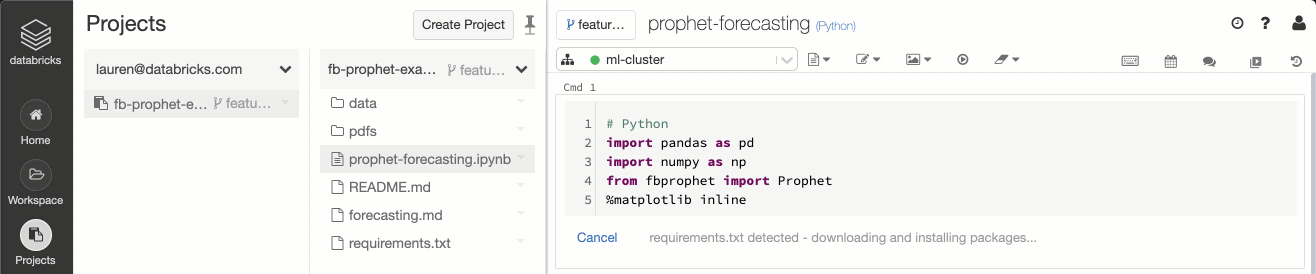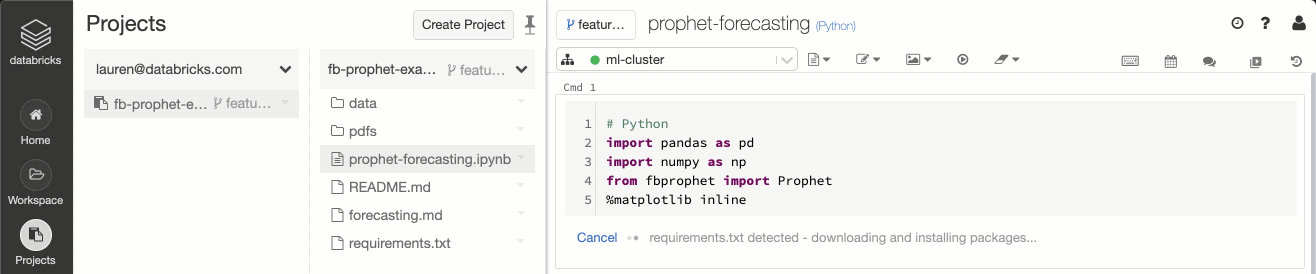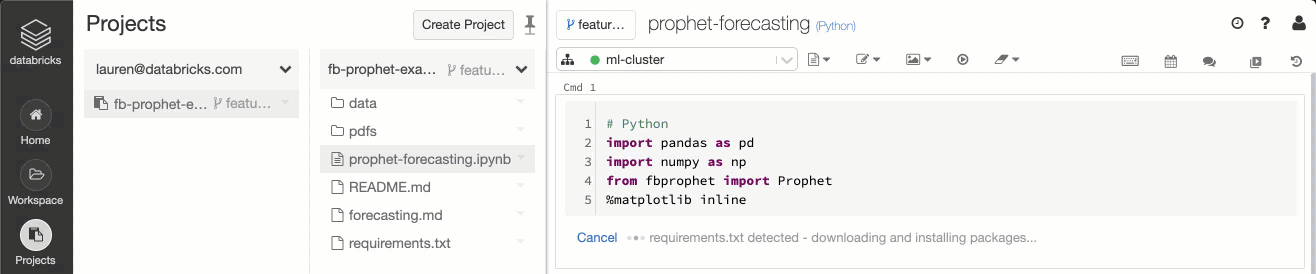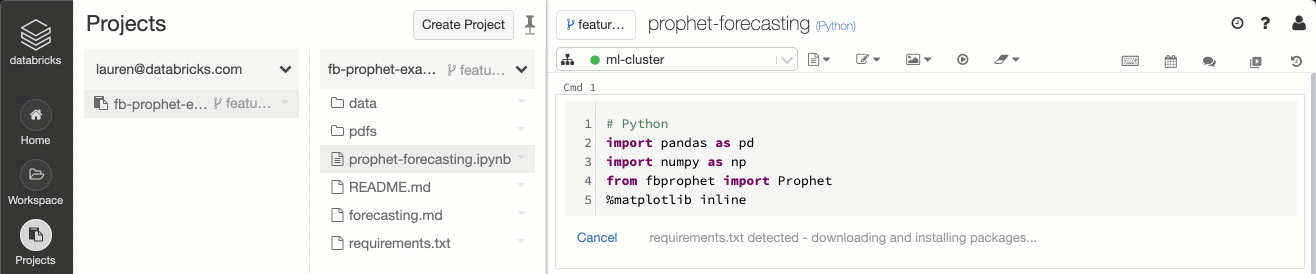
Figure 4: Integration between Databricks Runtime and Projects allows data teams to automatically detect the presence of environment specification files (e.g. requirements.txt) and install the library dependencies.
To go beyond what you are used to on your laptop, Databricks makes sure that, once an environment is created for your Project, all workers of an autoscaling cluster consistently have the exact same environment enabled.
Coming soon: Databricks Notebook Editor support for Jupyter notebooks
The Databricks Notebook Editor already provides collaborative features like co-presence, co-editing and commenting, all in a cloud-native developer environment with access control management and the highest security standards. To unify data teams, the Databricks Notebooks Editor also supports switching between the programming languages Python, R, SQL and Scala, all within the same notebook. Today, the Databricks Notebook Editor is used by tens of thousands of data engineers, data scientists and machine learning engineers daily.
To bring the real-world benefits of the Databricks Notebook Editor to a broader audience, we’ll support Jupyter notebooks in their native format on Databricks, providing you with the ability to edit Jupyter notebooks directly in the Databricks Notebook Editor. As a result, you’ll no longer have to make the trade-off between collaborative features and open-source standards like Jupyter.
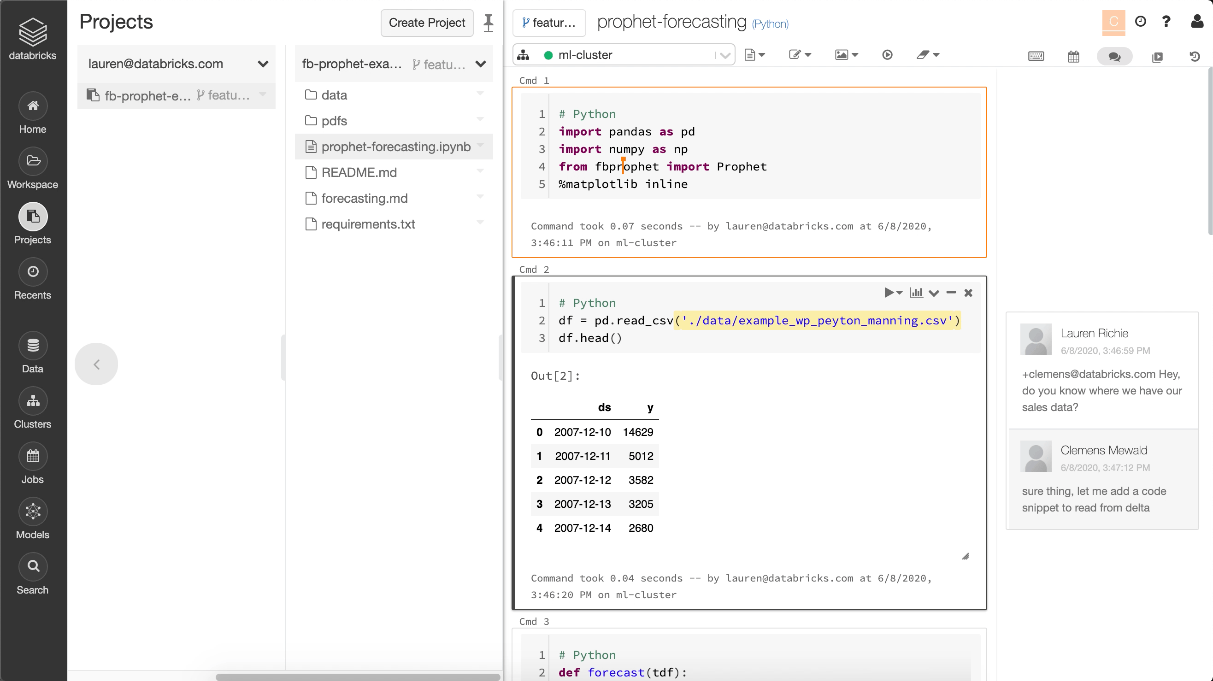
Figure 5: Support for opening Jupyter notebooks with the Databricks Notebook Editor provides data teams with collaborative features for standard file formats.
However, if your tool of choice is Jupyter, you’ll still be able to edit the same notebook using Jupyter embedded directly in Databricks, as shown below.
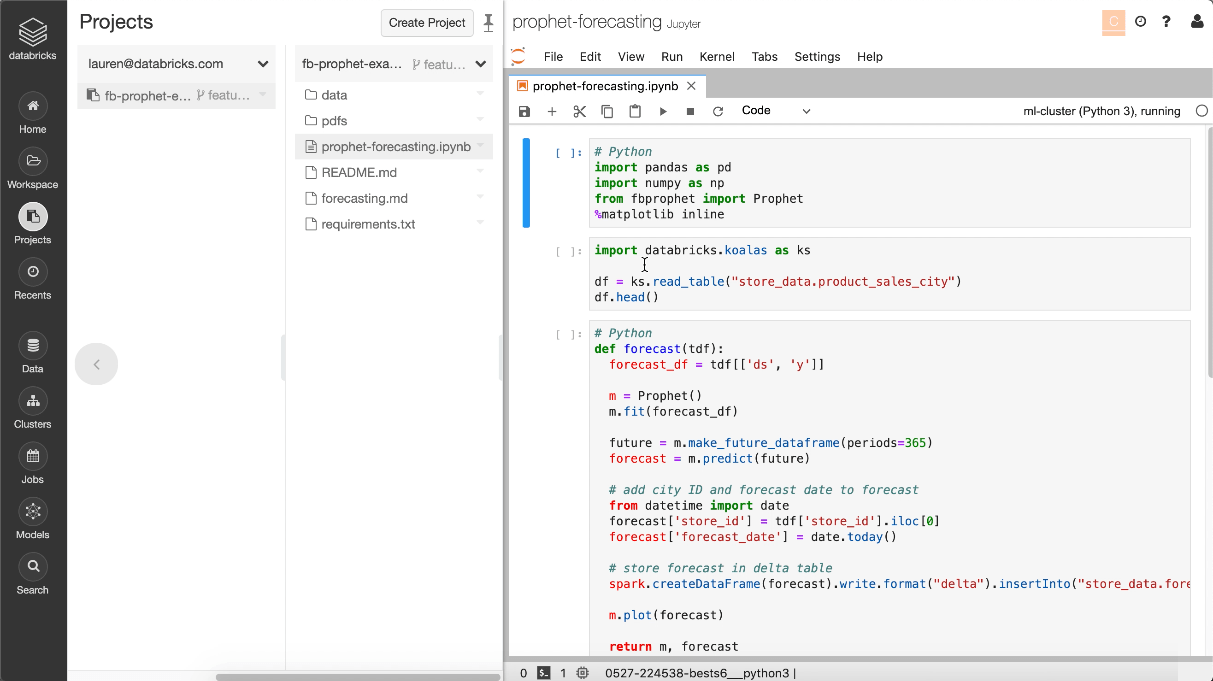
Figure 6: Support for opening Jupyter notebooks with JupyterLab is embedded within the Databricks Workspace.
Next steps
You can watch the official announcement and demo by Clemens Mewald and Lauren Richie at Spark + AI Summit:
As shared in our keynote today, we’ve been testing these capabilities in private preview for a while and are now excited to open up access to existing customers in preview. Sign up here to request access. We look forward to your feedback!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.