MLflow 1.12 Features Extended PyTorch Integration
MLflow 1.12 features include extended PyTorch integration, SHAP model explainability, autologging MLflow entities for supported model flavors, and a number of UI and document improvements. Now available on PyPI and the docs online, you can install this new release with pip install mlflow==1.12.0 as described in the MLflow quickstart guide.
In this blog, we briefly explain the key features, in particular extended PyTorch integration, and how to use them. For a comprehensive list of additional features, changes and bug fixes read the MLflow 1.12 Changelog.
Support for PyTorch Autologging, TorchScript Models and TorchServing
At the PyTorch Developer Day, Facebook's AI and PyTorch engineering team, in collaboration with Databricks’ MLflow team and community, announced an extended PyTorch and MLflow integration as part of the MLflow release 1.12. This joint engineering investment and integration with MLflow offer PyTorch developers an “end-to-end exploration to production platform for PyTorch.” We briefly cover three areas of integration:
- Autologging for PyTorch models
- Supporting TorchScript models
- Deploying PyTorch models onto TorchServe
Autologging PyTorch pl.LightningModule Models
As part of the universal autologging feature introduced in this release (see autologging section below), you can automatically log (and track) parameters and metrics from PyTorch Lightning models.
Aside from customized entities to log and track, the PyTorch autolog tracking functionality will log the model’s optimizer names and learning rates; metrics like training loss, validation loss, accuracies; and models as artifacts and checkpoints. For early stopping, model checkpoints, early stopping parameters and metrics are logged too.
Converting PyTorch models to TorchScript
TorchScript is a way to create serializable and optimizable models from PyTorch code. As such any MLflow-logged PyTorch model can be converted into a TorchScript, saved and loaded (or deployed to) a high-performance, independent process, where there is no Python dependency. The process entails following steps:
- Create an MLflow Python model
- Compile the model using JIT and convert to TorchScript model
- Log or save the TorchScript model
- Load or deploy the TorchScript model
For brevity, we have not included all the code here, but you can examine the example code—IrisClassification and MNIST—in the GitHub mlflow/examples/pytorch/torchscript directory.
One thing you can do with a scripted (fitted or logged) model is use the mflow fluent and mlflow.pytorch APIs to access the model and its properties, as shown in the GitHub examples. Another thing you can do with the scripted model is deploy it to a TorchServe server using TorchServer MLflow Plugin.
Deploying PyTorch models with TorchServe MLflow Plugin
TorchServe offers a flexible, easy tool for serving PyTorch models. Through the TorchServe MLflow deployment plugin, you can deploy any MLflow-logged and fitted PyTorch model. This extended integration completes the PyTorch MLOps lifecycle—from developing, tracking and saving to deploying and serving PyTorch models.

For demonstration, two PyTorch examples—BertNewsClassifcation and MNIST—enumerate steps in how you can use the TorchServe MLflow deployment plugin to deploy a PyTorch saved model to an existing TorcheServe server. Any MLflow-logged and fitted PyTorch model can easily be deployed using mlflow deployments commands. For example:
mlflow deployments create -t torchserve -m models:/my_pytorch_model/production -n my_pytorch_model
Once deployed, you can just easily use mlflow deployments predict command for inference.
mlflow deployments predict --name my_pytorch_model --target torchserve --input-path sample.json --output-path output.json.
SHAP API Offers Model Explainability
As more and more machine learning models are deployed in production as part of business applications that offer suggestive hints or make decisive predictions, machine learning engineers are obliged to explain how a model was trained and what features contributed to its output. One common technique used to answer these questions is SHAP (SHapley Additive exPlanations), a theoretical approach to explain an output of any machine learning model.
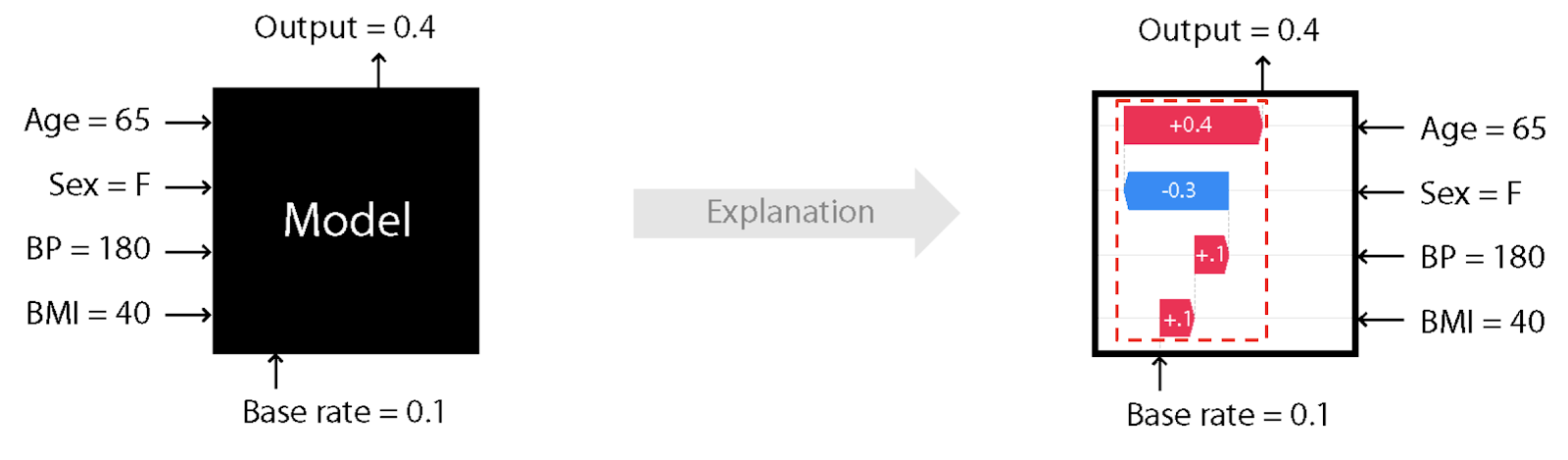
To that end, this release includes an mlflow.shap module with a single method mlflow.shap.log_explanation() to generate an illustrative figure that can be logged
as a model artifact and inspected in the UI.
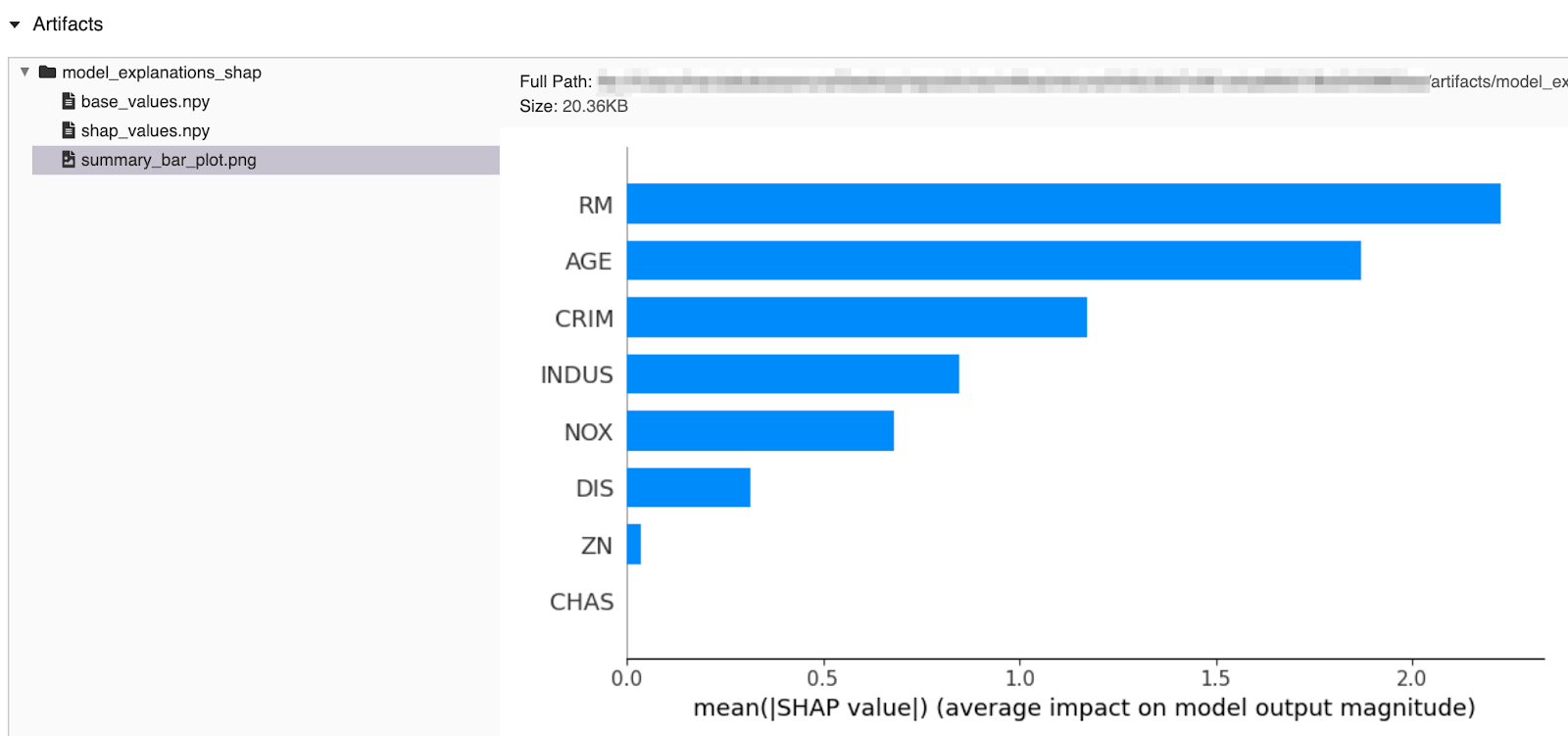
You can view the example code in the docs page and try other examples of models with SHAP explanations in the MLflow GitHub mlflow/examples/shap directory.
Autologging Simplifies Tracking Experiments
The mlflow.autolog() method is a universal tracking API that simplifies training code by automatically logging all relevant model entities—parameters, metrics, artifacts such as models and model summaries—with a single call, without the need to explicitly call each separate method to log respective model’s entities.
As a universal single method, under the hood, it detects which supported autologging model flavor is used—in our case scikit-learn—and tracks all its respective entities to log. After the run, when viewed in the MLflow UI, you can inspect all automatically logged entities.
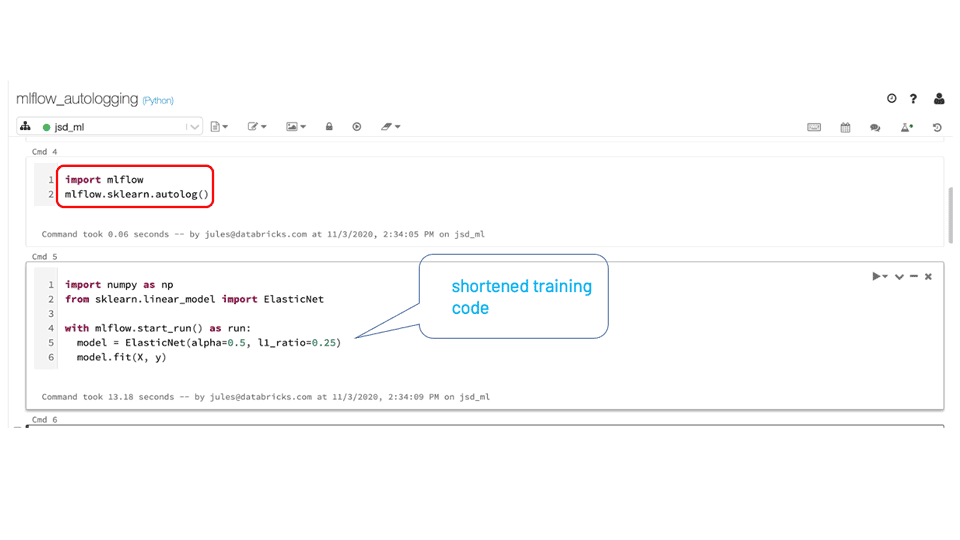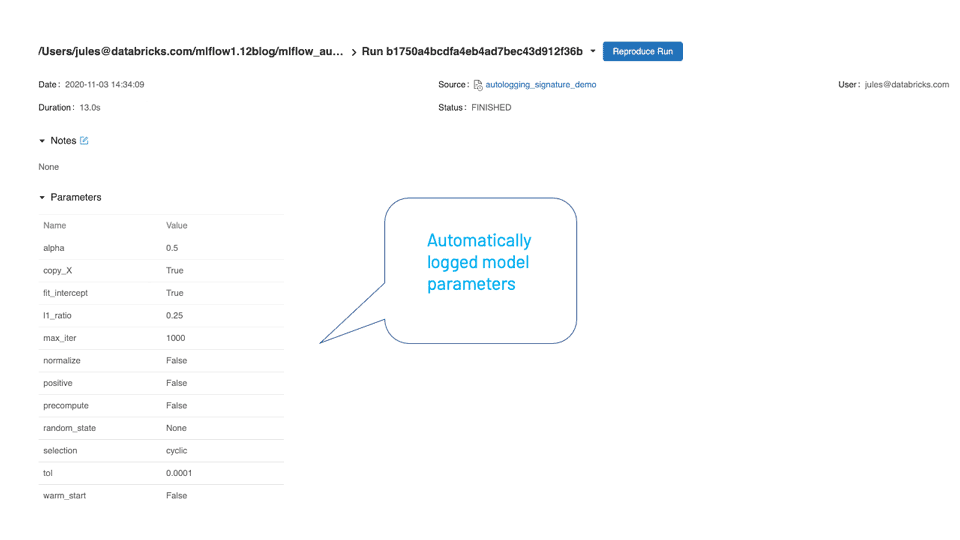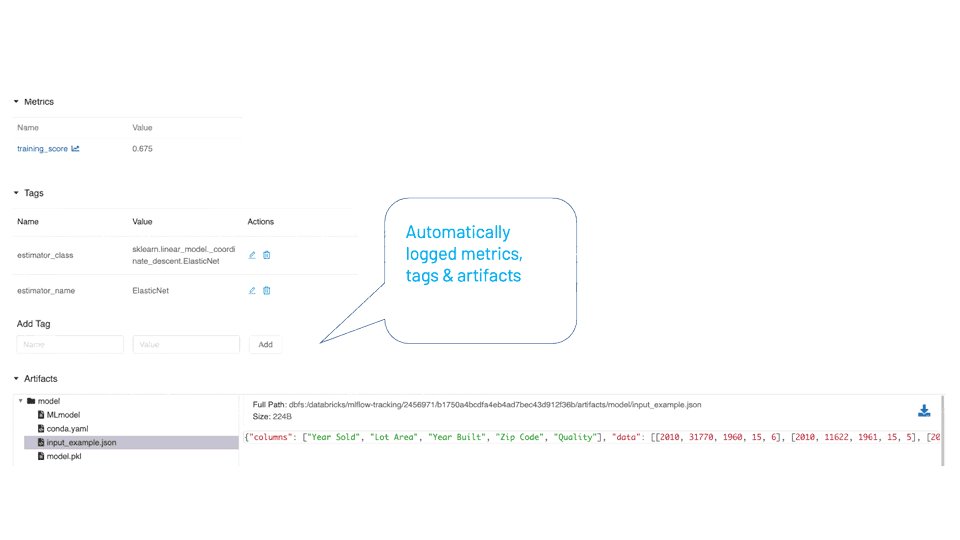
What’s next
Learn more about PyTorch integration at the Data + AI Summit Europe next week, with a keynote from Facebook AI Engineering Director Lin Qiao and a session on Reproducible AI Using PyTorch and MLflow from Facebook’s Geeta Chauhan.
Stay tuned for additional PyTorch and MLflow detailed blogs. For now you can:
- Read MLflow and PyTorch — Where Cutting Edge AI meets MLOps
- Checkout out the PyTorch and MLFlow mlflow/examples/pytorch/
- Examine SHAP GitHub mlflow/examples/shap/
pip install mlflow==1.12.0and have a go at it.
Community Credits
We want to thank the following contributors for updates, doc changes, and contributions to MLflow release 1.12. In particular, we want to thank the Facebook AI and PyTorch engineering team for their extended PyTorch integration contribution and all MLflow community contributors:
Andy Chow, Andrea Kress, Andrew Nitu, Ankit Mathur, Apurva Koti, Arjun DCunha, Avesh Singh, Axel Vivien, Corey Zumar, Fabian Höring, Geeta Chauhan, Harutaka Kawamura, Jean-Denis Lesage, Joseph Berry, Jules S. Damji, Juntai Zheng, Lorenz Walthert, Poruri Sai Rahul, Mark Andersen, Matei Zaharia, Martynov Maxim, Olivier Bondu, Sean Naren, Shrinath Suresh, Siddharth Murching, Sue Ann Hong, Tomas Nykodym, Yitao Li, Zhidong Qu, @abawchen, @cafeal, @bramrodenburg, @danielvdende, @edgan8, @emptalk, @ghisvail, @jgc128 @karthik-77, @kzm4269, @magnus-m, @sbrugman, @simonhessner, @shivp950, @willzhan-db
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.