Burning Through Electronic Health Records in Real Time With Smolder
by Ryan DeCosmo and Frank Austin Nothaft
Check out the solution accelerator to download the notebook referred throughout this blog.
In previous blogs, we looked at two separate workflows for working with patient data coming out of an electronic health record (EHR). In those workflows, we focused on a historical batch extract of EHR data. However, in the real world, data is continuously inputted into an EHR. For many of the important predictive healthcare analytics use cases, like sepsis prediction or ER overcrowding, we need to work with the clinical data as it flows through the EHR.
How does data actually flow through an EHR? Typically, there are several passes of refinement. In some EHR implementations, data first lands in a near-real-time fashion into a NoSQL style operational store. After a day, the new data in this NoSQL store moves from the operational store into normalized and dimensional SQL stores. Other EHR implementations have different database implementations, but still, there is typically a delay before a final “historical” record of EHR data is available for batch analysis. To analyze clinical data in real time, we need to access either push-based HL7 message feeds or pull-based FHIR API endpoints. These feeds and endpoints contain a variety of health information data. For instance, the Admission/Discharge/Transfer (ADT) messages can be used to track when a patient comes in or moves between units, while Order Entry (ORM) messages place/modify/cancel orders, such as giving oxygen to a patient or running a specific laboratory test. By combining feeds and resources together, we can get a comprehensive view of our patients and our hospital.
Healthcare teams and clinicians face a number of questions when building a real-time analytics system on top of EHR data: should I consume FHIR or HL7? How should I parse the records? How should I store and merge data? In this blog, we introduce Smolder, an open-source library for manipulating EHR data using Apache Spark™. Smolder provides Spark-native data loaders and APIs that transforms HL7 messages into Apache Spark™ SQL DataFrames. To simplify manipulating, validating, and remapping the content in messages, Smolder adds SQL functions for accessing message fields. Ultimately, this makes it possible to build streaming pipelines to ingest and analyze HL7 data in minutes while providing an easy-to-use declarative syntax that eliminates the need to learn low-level libraries like HAPI. These pipelines can achieve near-real-time latencies while achieving data unification across healthcare data sources by leveraging open source standards like Delta Lake
In the rest of this blog, we will use the Smolder library to analyze EHR data in near-real-time to identify patients with high care utilization. First, we will do a deep dive on the HL7v2 standard, how it works, and what it means. Then, we will discuss the design principles that guided our development of Smolder. Finally, we will show how to load the data into Delta Lake in real-time by using Apache Spark’s Structured Streaming APIs, and the Smolder library. We will use this data to drive a dashboard that helps us identify in real time where we have high-utilization patients across our hospital system.
Working with HL7 messages
HL7v2
HL7 stands for Health Level 7, an international standards body that defines interoperability standards for healthcare. They maintain multiple prominent standards, such as the emerging FHIR healthcare data exchange standard that defines REST APIs and JSON schemas for exchanging healthcare data, the XML-based (consolidated) Clinical Document Architecture (CDA and C-CDA) standard, and the original HL7v2 standard. These standards have different purposes: FHIR defines API endpoints that are useful for application development, C-CDA defines standards that are best used for exchanging historical information about a patient, and HL7v2 is a messaging dialect that captures real-time updates to the state and data that is present in an EHR. While there has been a lot of recent interest in FHIR for application development, HL7v2 is generally the most appropriate standard to use for analytics due to its widespread adoption. Most institutions have legacy systems currently leveraging HL7 feeds. As a result, it is easier to tap into a larger amount of data and create a richer base for analytics, without having to wait for every system to support FHIR. Also, HL7 feeds themselves are typically streams of data based on TCP/IP, which meshes very cleanly to event-based streaming architectures.
Code: This is an example HL7 message. This message is an ADT_A03 message, which provides information about a patient being discharged. We generated this message using the open-source Synthea medical record simulator.
Since we have settled on HL7v2, let’s start by looking at the contents of an HL7v2 message. The image above shows a single HL7v2 message, which is multiline, pipe delimited. There is also an XML version of the spec. FHIR is a JSON-based spec. The schema for each message type and segment type is specified by the HL7v2 spec. Each line of the message is a segment, and the first column is the “segment descriptor,” which tells us what the schema is for in that segment. When we parse the ADT_A03 message above, we have two segments; the “PID” segment identifier contains information about the patient’s identity and the “PV1” segment contains information about the patient’s visit that they are discharged from. In a patient identity segment, the second field is the ID for the patient, the fourth field is the name, and so on.
So, how can you work with this data? We have helped multiple customers ingest HL7 data into Databricks using Apache Spark’s streaming capabilities. Historically, we have seen customers build a conduit between their EHR and a streaming service like Apache Kafka™️, Kinesis or EventHubs. Then they connect one of these streaming busses up to Apache Spark, which yields a DataFrame of message text. Finally, they parse this text using either a handwritten parser or a low-level library like HAPI.
While this approach has worked for some customers, having to hand-code parsing libraries--or rely on libraries like HAPI that have overhead--can cause challenges. One of the key benefits of data lakes is to be able to delay validation in a pipeline. We typically talk about this being the bronze layer, which is the data that is ingested and stored in its raw form. This gives you the flexibility to maintain the observed historical data without having to make any choices about the size and shape of your data yet.
This is particularly useful when you need to do historical validation and analysis before embarking on a business-facing use case. For example, consider the case of validating the primary care provider (PCP) field. If you discover a healthcare system was swapping the PCP with a different physician on the care team, you would want to be able to retroactively correct the error in all those records. Smolder by design, subscribes to this paradigm.
Unlike HAPI, Smolder breaks messages down into structs that make no attempt at validation beyond it being a valid HL7 message. This allows us to capture the observed data, while still making it accessible to query and populate our silver layer.
Designing Smolder, an open-source library for working with HL7 in Apache Spark
We started developing Smolder to provide an easy-to-use system that can achieve near-real-time latencies for processing HL7v2 messages and make this data accessible to a large ecosystem of tools for data science and visualization. To do this, we took the following approach:
- Turn HL7 messages into DataFrames with a single line of code: DataFrames are widely used across data science—whether through Pandas, R, or Spark—and can be used through widely-accessible declarative programming frameworks like SQL. If we can load HL7 messages into a DataFrame with a single line of code, we have dramatically increased the number of downstream places we can work with HL7 messages.
- Use simple, declarative APIs to extract data from messages: While libraries like HAPI provide APIs for working with HL7v2 messages, these APIs are complex, deeply object-oriented, and require a lot of knowledge about the HL7v2 messaging format. If we can instead give people one-line SQL-like functions, they can make sense of the data in HL7 messages without needing to learn a new and complex API.
- Have a consistent schema and semantics for HL7 messages, no matter the source: Smolder supports both the direct ingestion of HL7v2 messages, as well as the ingestion of HL7v2 message text that has come from another streaming source, whether an open-source tool like Apache Kafka or cloud-specific services like AWS’ Kinesis or Azure’s EventHubs. No matter the source, the messages always are parsed into the same schema. When coupled with Apache Spark’s Structured Streaming semantics, we achieve portable, platform-neutral code that can easily be validated and runs equivalently during batch or streaming data processing.
Ultimately, this approach makes Smolder a lightweight library that is easy to learn and use, which can support demanding SLAs on large volumes of HL7 messages. Now we will dive into Smolder’s APIs and how to build a dashboard that analyzes hospital admission patterns.
Parsing HL7 messages using Smolder
Apache Spark™’s Structured Streaming API allows a user to process streaming data by using an extension of the Spark SQL APIs. When coupled with the Smolder library, you can load HL7v2 messages into a DataFrame, either using Smolder to read batches of raw HL7v2 messages, or by using Smolder to parse out HL7v2 message text that comes in from another streaming source. For instance, if you have a batch of messages to load, you simply invoke the hl7 reader:
The schema returned contains the message header in the message column. The message segments are nested in the segments column, which is an array that contains two nested fields: the string id for the segment (e.g., PID for a patient identification segment) and an array of segment fields.
Smolder can also be used to parse raw message text. This might happen if you had an HL7 message feed land in an intermediate source first (e.g., a Kafka stream). To do this, we can use Smolder's parse_hl7_message helper function. First, we start with a DataFrame containing HL7 message text:
Then, we can import the parse_hl7_message message from the com.databricks.labs.smolder.functions object and apply that to the column we want to parse:
This yields the same schema as our hl7 data source.
Extracting data from HL7v2 message segments using Smolder
While Smolder provides an easy-to-use schema for HL7 messages, we also provide helper functions in com.databricks.labs.smolder.functions to extract subfields of a message segment. For instance, let's say we want to get the patient's name, which is the 5th field in the patient ID (PID) segment. We can extract this with the segment_field function:
If we then wanted to get the patient's first name, we can use the subfield function:
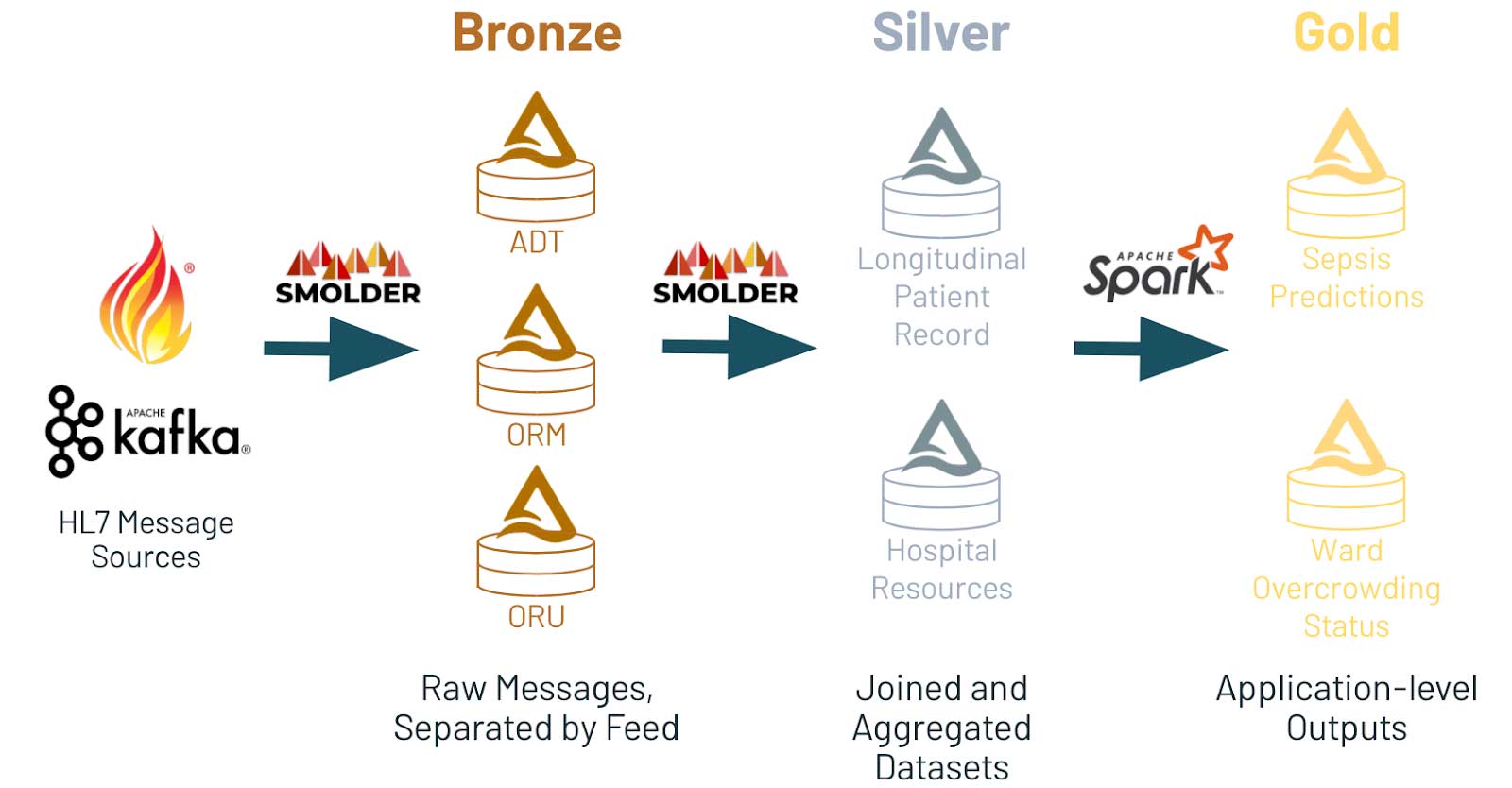
- The bronze layer contains raw message feeds (e.g., a table per feed of ADT, ORM, ORU, etc)
- The silver layer aggregates this information into tables that are useful for downstream applications (e.g., a longitudinal patient record, aggregates about hospital resources)
- The gold layer contains application-level data (e.g., for a hospital overcrowding alerting system, occupancy per ward per hospital)
Why build on top of Delta Lake? First of all, Delta is an open format that ensures that data is easily accessible from many analytical systems, whether its a data science ecosystem through Apache Spark or through data warehouse systems like Synapse. Additionally, Delta Lake is designed to support cascading streams, meaning that data can stream through the bronze layer, into the silver, and finally gold layers. Additionally, Delta Lake provides numerous ways to optimize our tables to improve query performance. For instance, we probably want to query rapidly across both patient ID and date of an encounter, since those are common fields to query over: as we discussed in our previous blog, we can use Z-ordering. Delta Lake supports Z-ordering to do multi-dimensional data clustering and provide good performance on both of these query patterns.
Get started building a health Delta Lake with Smolder
In this blog, we introduced Smolder, an Apache 2 licensed library for loading patient data from an EHR. You can get started by reading our project docs, or create a fork of the repository to start contributing code today. To learn more about using Delta Lake to store and process clinical datasets, download our free eBook on working with real-world clinical datasets. You can also start a free trial today using the notebooks from this solution accelerator.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.