Time Series Data Analytics in Financial Services with Databricks and KX
by Josh Seidel and Connor Gervin
This is a guest co-authored post. We thank Connor Gervin, partner engineering lead, KX, for his contributions.
KX recently announced a partnership with Databricks making it possible to cover all the use cases for high-speed time-series data analytics. Today we’re going to explain the integration options available between both platforms for both streaming and batch time-series data and why this provides significant benefits to Financial Services companies.
Time-series data is used ubiquitously within Financial Services and we believe the new use-cases can bring both technologies and data to new frontiers. There are a number of tools in the market to capture, manage and process time-series data. Given the nature of financial services use cases, it is not only necessary to leverage the best of breed tools for data processing but to keep innovating. This was the leading force behind the partnership between Databricks and KX. Through this initiative we can combine the low-latency streaming capabilities of kdb+ and q language with the scalable data and AI platform that Databricks provides. Financial Service firms can unlock and accelerate innovation by taking advantage of the time-series data in the cloud rather than having it locked and siloed in on-premise instances of kdb+.
In one simple lakehouse platform, Databricks provides the best-in-class ETL and data science capabilities that are now available to KX users to perform ad hoc analysis and collaboratively build sophisticated machine learning models. This integration brings KX data that was previously out of reach, at the edge or on-prem, to now land into the cloud with Databricks for ML and AI use cases in a simple manner. In addition to a new world of use-cases on KX data, KX introduces Databricks to the world of low-latency streaming analytics where continuous intelligence and data-driven decision making can be performed in real-time. In this post we will now outline just a few of the options available today to users who would like to integrate Databricks and KX across a range of use-cases and deployment configurations.
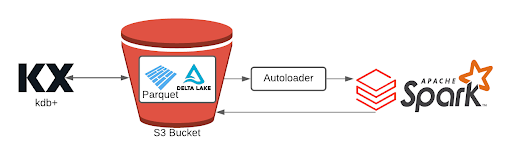
Option: kdb+ to blob store as Parquet or Delta
Within KX Insights, kdb+ has drivers to directly write data to the native blob and storage services on each of the cloud providers (e.g. S3, ADLS Gen2, GCS). Databricks provides an Autoloader mechanism to easily recognize new data in the cloud storage service and subsequently have the data loaded into Databricks to process. Databricks can then write out data to the native blob and storage services as Parquet or Delta Lake where new insights, analytics or machine learning objects can then be loaded into the kdb+ environment.
There are a number of financial use cases that this integration serves such as batch modeling, optimizations and machine learning on the data, leading to better risk calculations, pricing models, populating rates data, surveillance and even recommendations across portfolios. The ability to feed the calculations and values back into KX, allows the low-latency streaming and service use cases where kdb+ accelerates the business goals.
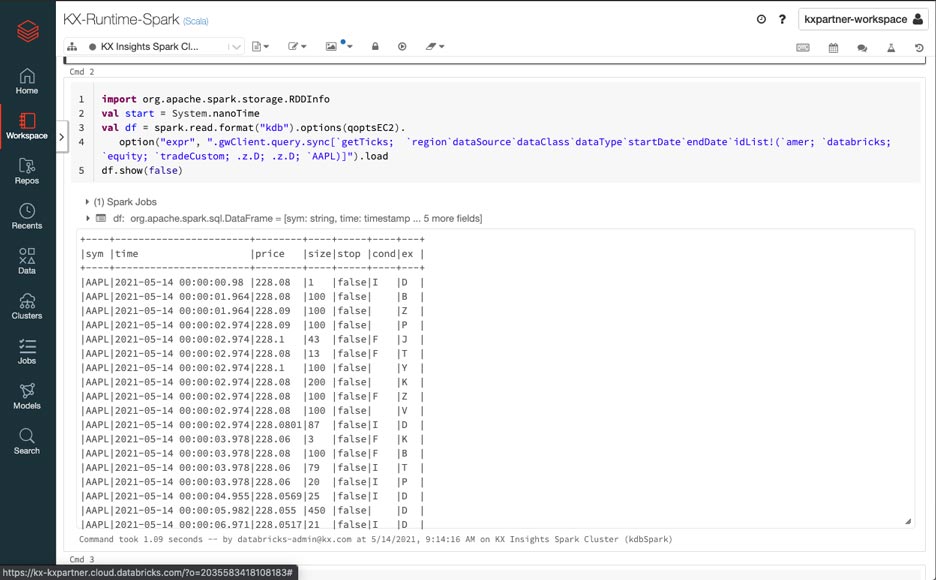
Option: KdbSpark Spark data source
KdbSpark is a Spark Data Source available directly on GitHub. It was originally developed by Hugh Hyndman, a well regarded kdb+ champion, two years ago. This interface provides the ability to directly send and receive data and queries between Databricks and kdb+ both on the same instance as well as across a network connection. KdbSpark provides the ability to directly connect Databricks to kdb+, execute ad-hoc queries or server-side functions with arguments and support additional speed enhancements such as predicate push-down. One of the many beneficial examples for the business would be the ability to access kdb+ over the data source thereby allowing quants and data modelers to leverage Databricks notebooks for exploratory data analysis for new strategies and insights directly with q and kdb+.
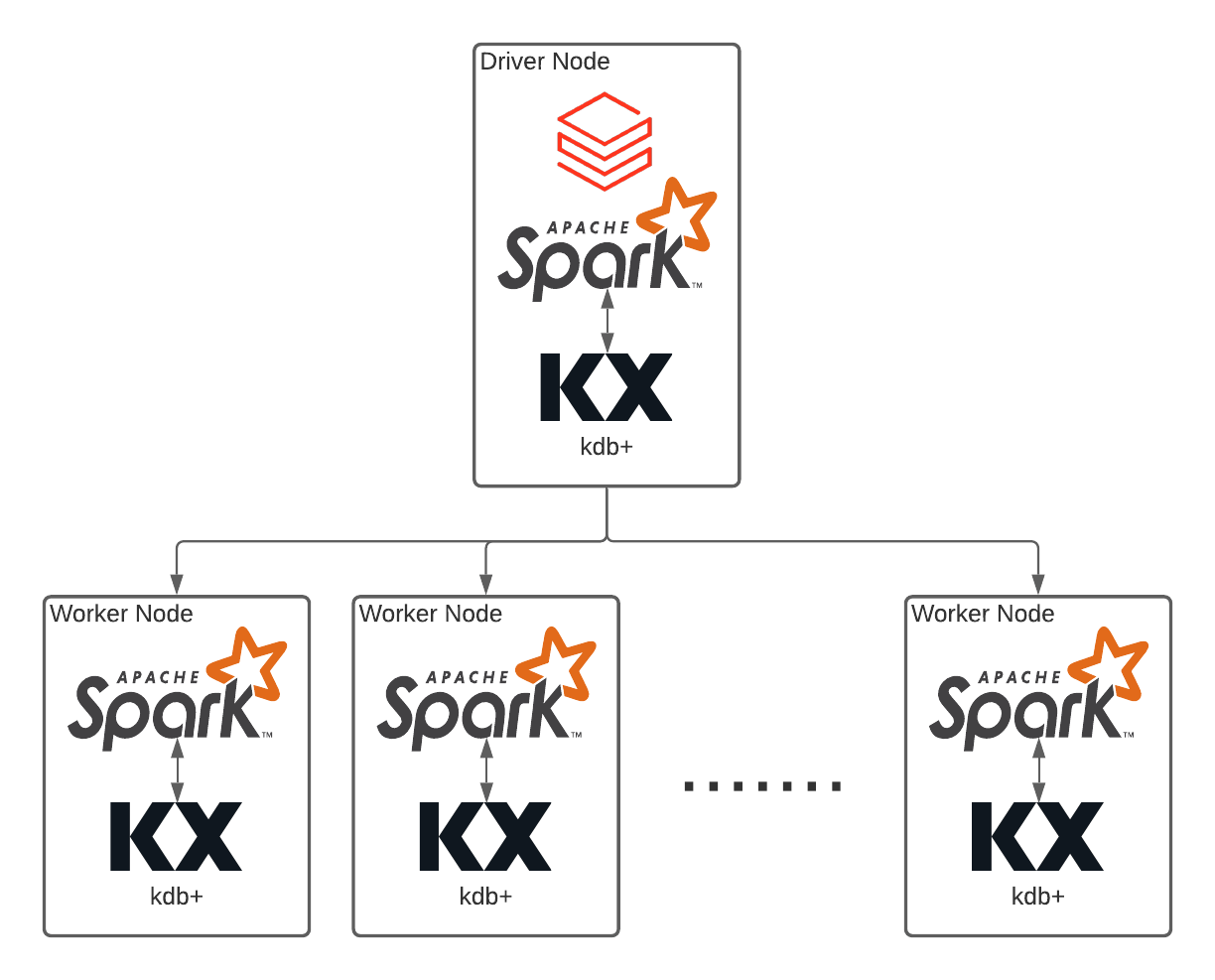
Option: KX Insights on a Databricks Cluster
Both KX and Databricks have worked together to build a containerized version of KX Cloud Edition that can be distributed and run across the Databricks cluster. By leveraging Databricks, kdb+ can easily scale in the cloud with the simple interface and mechanisms of Spark. By scaling kdb+, a number of workloads can be run in parallel against the data stored natively within kdb+ on Object Storage across all the cloud providers. This allows kdb+ scripts and models to horizontally scale on ephemeral cloud compute, for example Monte Carlo simulations, regressions, and various other models in a faster, easier, cheaper way, all the while increasing throughput and greatly reducing the time to actionable insights.
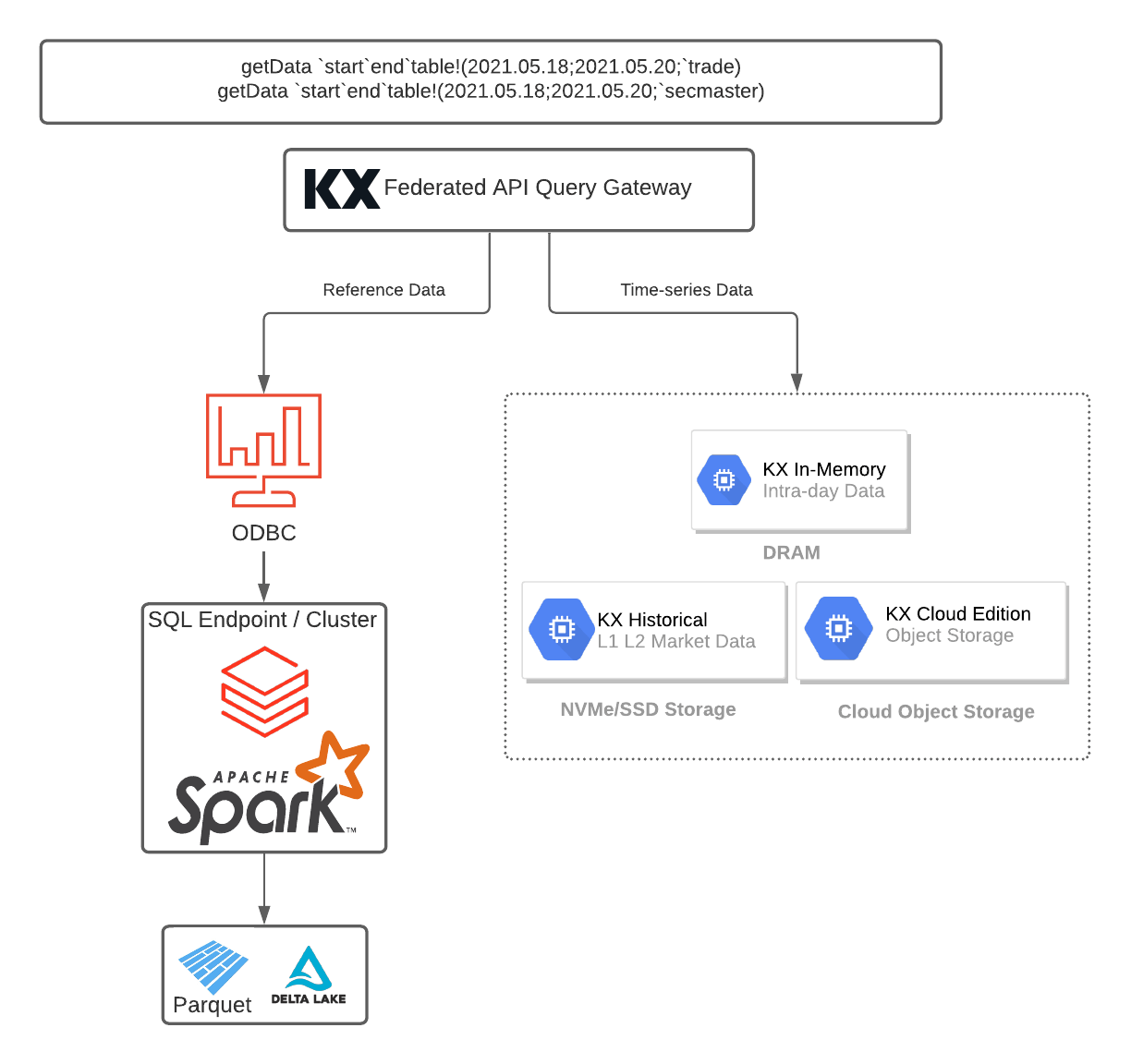
Option: Federated Queries via ODBC/JDBC/REST API
There’s more. KX Insights provides a mechanism to federate queries across multiple data sources via a single interface, providing the ability to decompose a query between kdb+ and Databricks so that each respective system storing data can then be queried, aggregated and analysed. For analysts, focused on BI workload or correlating time-series with fundamental data, it is preferred to have a single pane of glass access layer to various real-time and historical data sources.
Option: Databricks APIs
KX has developed a series of interfaces that enables access to Databricks RESTful APIs from within kdb+/q. All of the exposed features of Databricks are available in a programmable way, including Databricks Workspace APIs, SQL End Points and MLflow. MLflow APIs are now very exciting because kdb+ and q can support the ability to connect to both the open-source and managed versions of MLflow, and enable MLflow to manage the modeling and machine learning lifecycle via kdb+.
Option: Full kdb+ Python runtime (PyQ)
As part of the Fusion for kdb+ interface collection, PyQ brings the Python programming language to the kdb+ database allowing developers to integrate Python and q code seamlessly in one application. When using the Python Runtime within a Spark Session, PyQ brings a full interactive kdb+ environment right inside the Python process by simply installing via pip. Databricks and kdb+ together via Python is an integration ideal for executing or porting your Data Science and Machine Learning models into Databricks to be trained and executed on the cloud.
In summary, there are a number of ways that Databricks and KX integrate. With the collaboration of strong technical skill sets on both sides, Databricks and KX have partnered to deliver best-of-industry features to their mutual customers. Please reach out to your respective contact at either organization to see more of how Databricks and KX technologies integrate and democratize time-series data for new use cases and building business value.
Or come hear KX speak at the Databricks Financial Services Industry Forum on Unlocking New Insights on Real-time Financial Data with ML.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.