Using Bayesian Hierarchical Models to Infer the Disease Parameters of COVID-19
In a previous post, we looked at how to use PyMC3 to model the disease dynamics of COVID-19. This post builds on this use case and explores how to use Bayesian hierarchical models to infer COVID-19 disease parameters and the benefits compared to a pooled or an unpooled model. We fit an SIR model to synthetic data, generated from the Ordinary Differential Equation (ODE), in order to estimate the disease parameters such as R0. We then show how this framework can be applied to a real-life dataset (i.e. the number of infections per day for various countries). We conclude with the limitations of this model and outline the steps for improving the inference process.
I have also launched a series of courses on Coursera covering this topic of Bayesian modeling and inference, courses 2 and 3 are particularly relevant to this post. Check them out on the Coursera Databricks Computational Statistics course page.
The SIR model
The SIR model, as shown in our previous post to model COVID-19, includes the set of three Ordinary Differential Equations (ODEs). There are three compartments in this model: S, I and R.
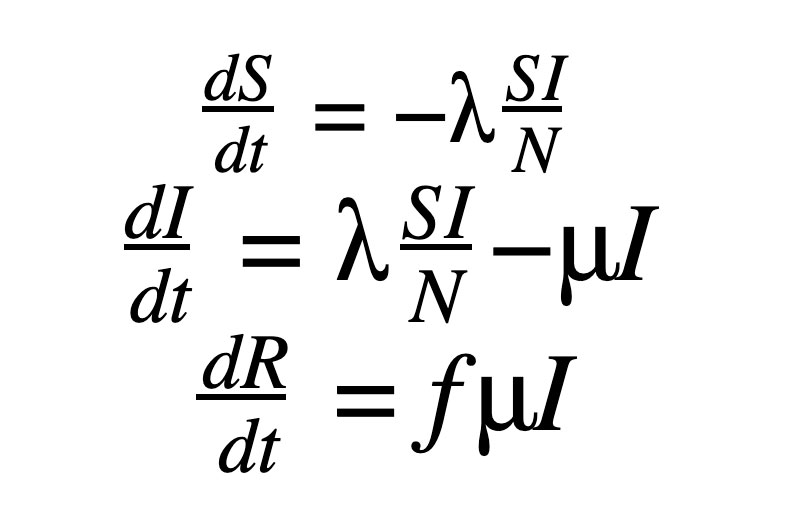
Here ‘S’, ‘I’ and ‘R’ refer to the susceptible, infected and recovered portions of the population of size ‘N’ such that
The assumption here is that once you have recovered from the disease, lifetime immunity is conferred on an individual. This is not the case for a lot of diseases and, hence, may not be a valid model.
λ is the rate of infection and μ is the rate of recovery from the disease. The fraction of people who recover from the infection is given by ‘f’ but for the purpose of this work, ‘f’ is set to 1 here. We end up with an Initial Value Problem (IVP) for our set of ODEs, where I(0) is assumed to be known from the case counts at the beginning of the pandemic and S(0) can be estimated as N - I(0). Here we make the assumption that the entire population is susceptible. Our goal is to accomplish the following:
- Use Bayesian Inference to make estimates about λ and μ
- Use the above parameters to estimate I(t) for any time ‘t’
- Compute R0
Pooled, unpooled and hierarchical models
Suppose you have information regarding the number of infections from various states in the United States. One way to use this data to infer the disease parameters of COVID-19 (e.g. R0) is to sum it all up to estimate a single parameter. This is called a pooled model. However, the problem with this approach is that fine-grained information that might be contained in these individual states or groups is lost. The other extreme would be to estimate an individual parameter R0 per state. This approach results in an unpooled model. However, considering that we are trying to estimate the parameters corresponding to the same virus, there has to be a way to perform this collectively, which brings us to the hierarchical model. This is particularly useful when there isn’t sufficient information in certain states to create accurate estimates. Hierarchical models allow us to share the information from other states using a shared ‘hyperprior’. Let us look at this formulation in more detail using the example for λ :
For a pooled model, we can draw λ from a single distribution with fixed parameters λμ, λσ.
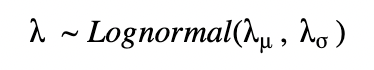
For an unpooled model, we can draw each λ with fixed parameters λμ, λι.
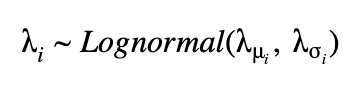
For a hierarchical model, we have a prior that is parameterized by non-constant parameters drawn from other distributions. Here, we draw λs for each state, however, they are connected through shared hyperprior distributions as shown below.
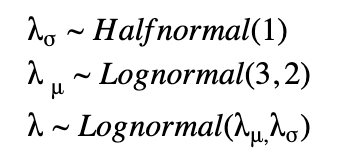
Check out course 3 Introduction to PyMC3 for Bayesian Modeling and Inference in the recently-launched Coursera specialization on hierarchical models.
Hierarchical models on synthetic data
To implement and illustrate the use of hierarchical models, we generate data using the set of ODEs that define the SIR model. These values are generated at preset timesteps; here the time interval is 0.25. We also select two groups for ease of illustration, however, one can have as many groups as needed. The values for λ and μ are set as [4.0, 3.0] and [1.0, 2.0] respectively for the two groups. The code to generate this along with the resulting time-series curves are shown below.
Generate synthetic data
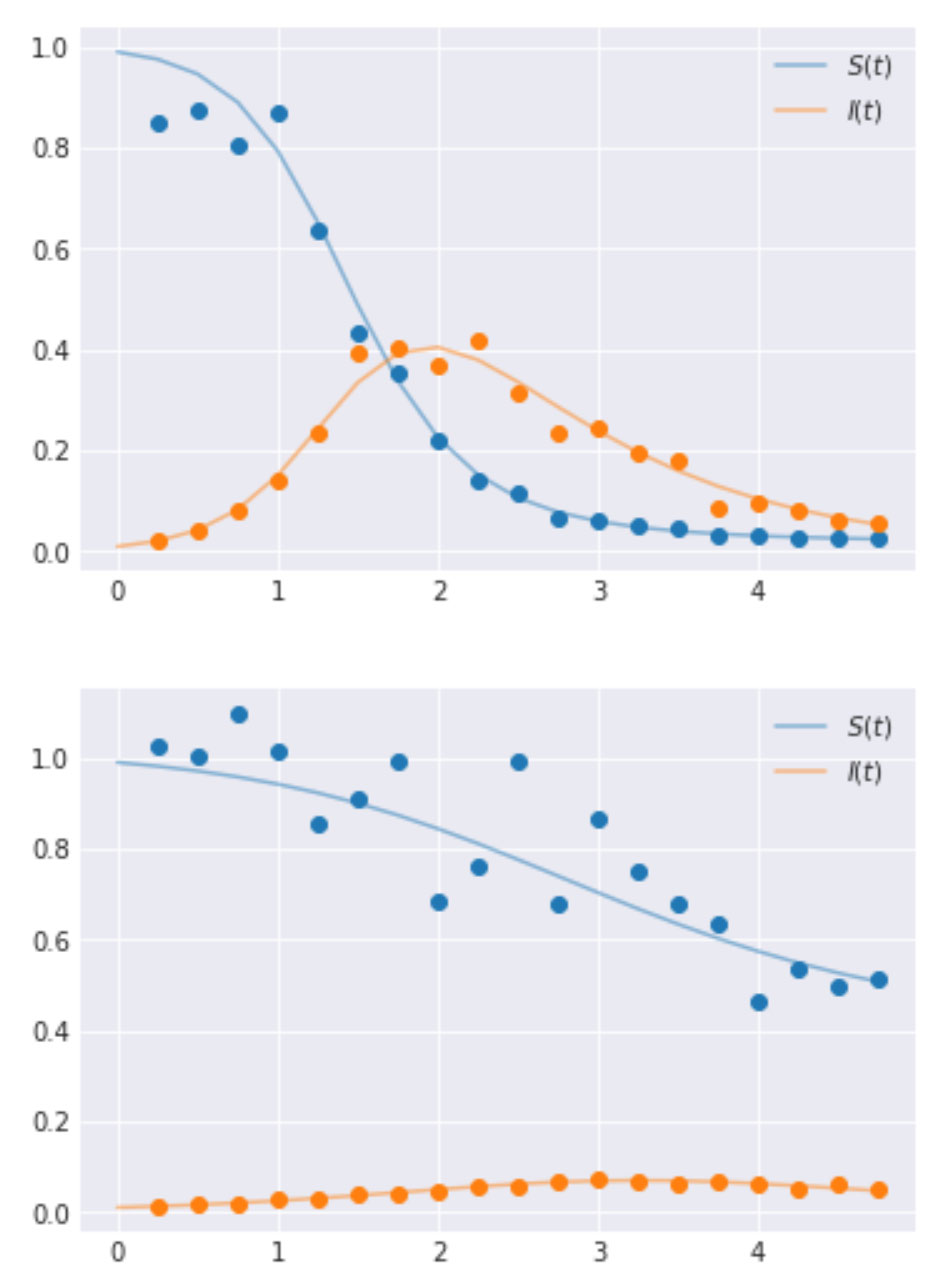
Performing inference using a hierarchical model
Real-life COVID-19 data
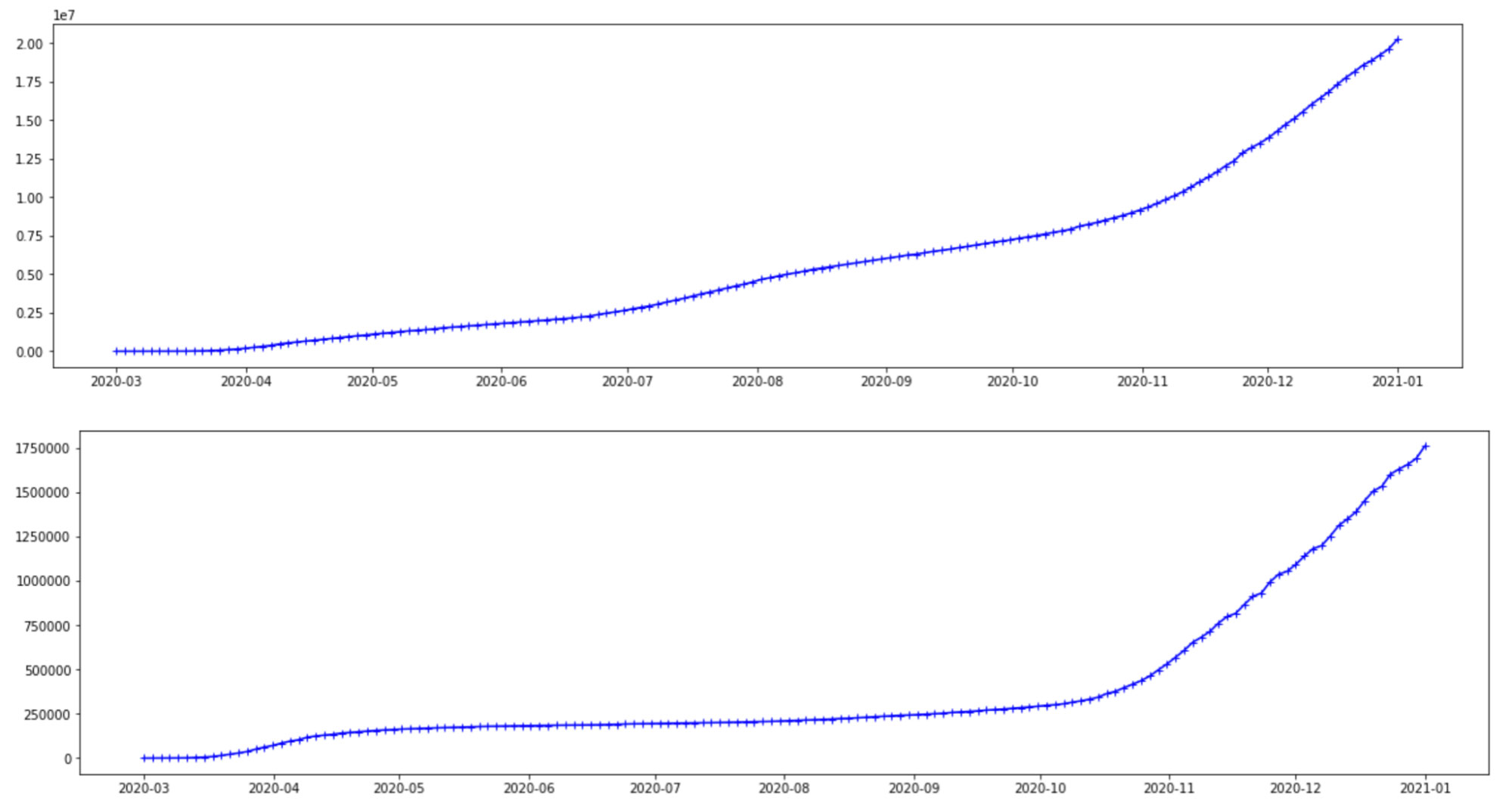
The data used here is obtained from the Johns Hopkins CSSE Github page where case counts are regularly updated. Here we plot and use the case count of infections-per-day for two countries, the United States and Brazil. However, there is no limitation on either the choice or number of countries that can be used in a hierarchical model. The cases below are from Mar 1, 2020 to Jan 1, 2021. The graphs seem to follow a similar trajectory, even though the scales on the y-axis are different for these countries. Considering that these cases are from the same COVID-19 virus, this is reasonable. However, there are differences to account for, such as the different variants, different geographical structures and social distancing rules, healthcare infrastructure and so on.
Inference of parameters
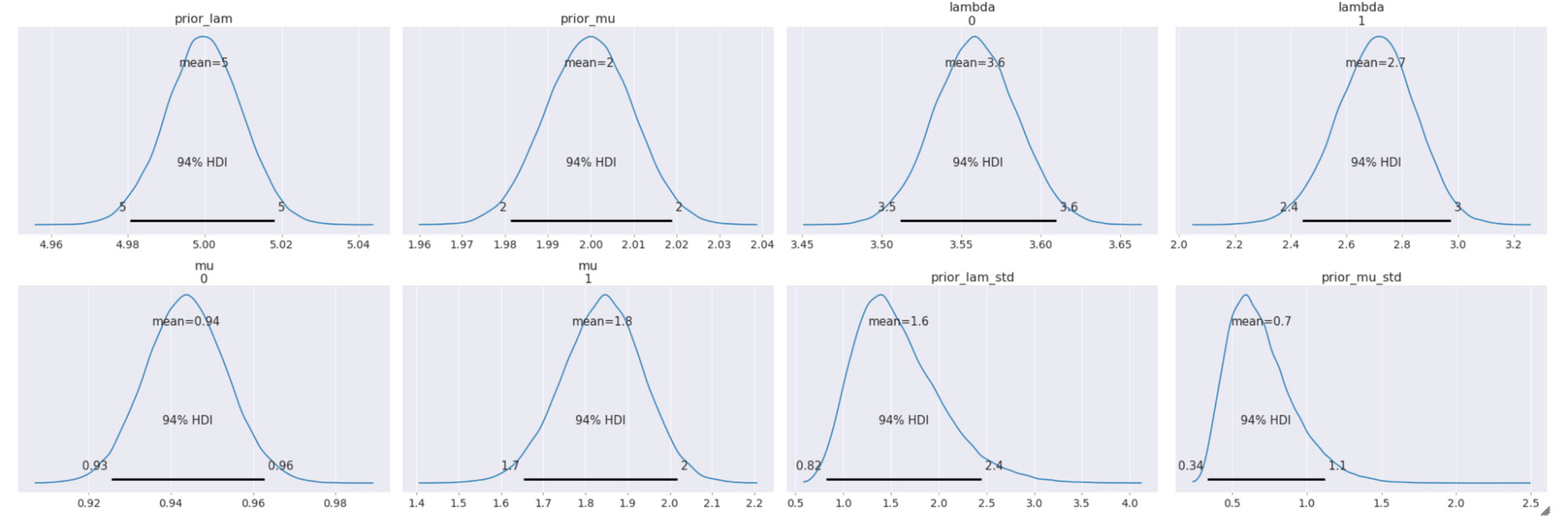
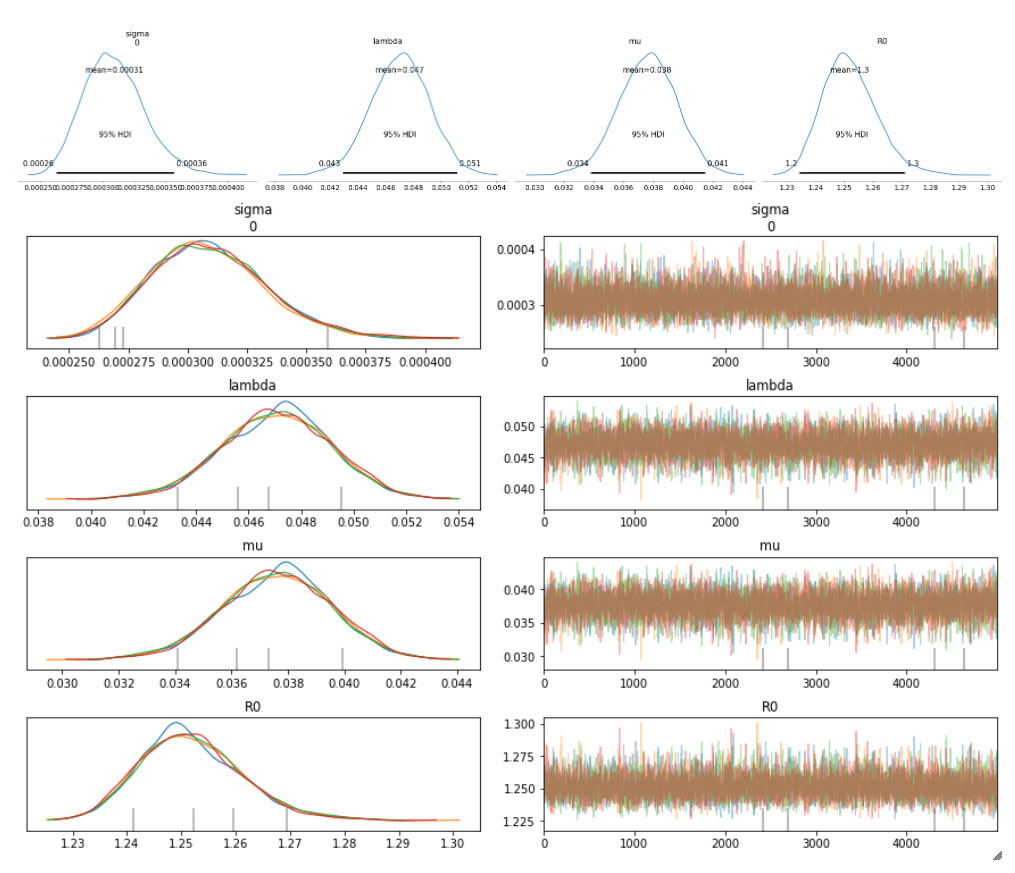
The sampled posterior distributions are shown below, along with their 94% Highest Density Interval (HDI).
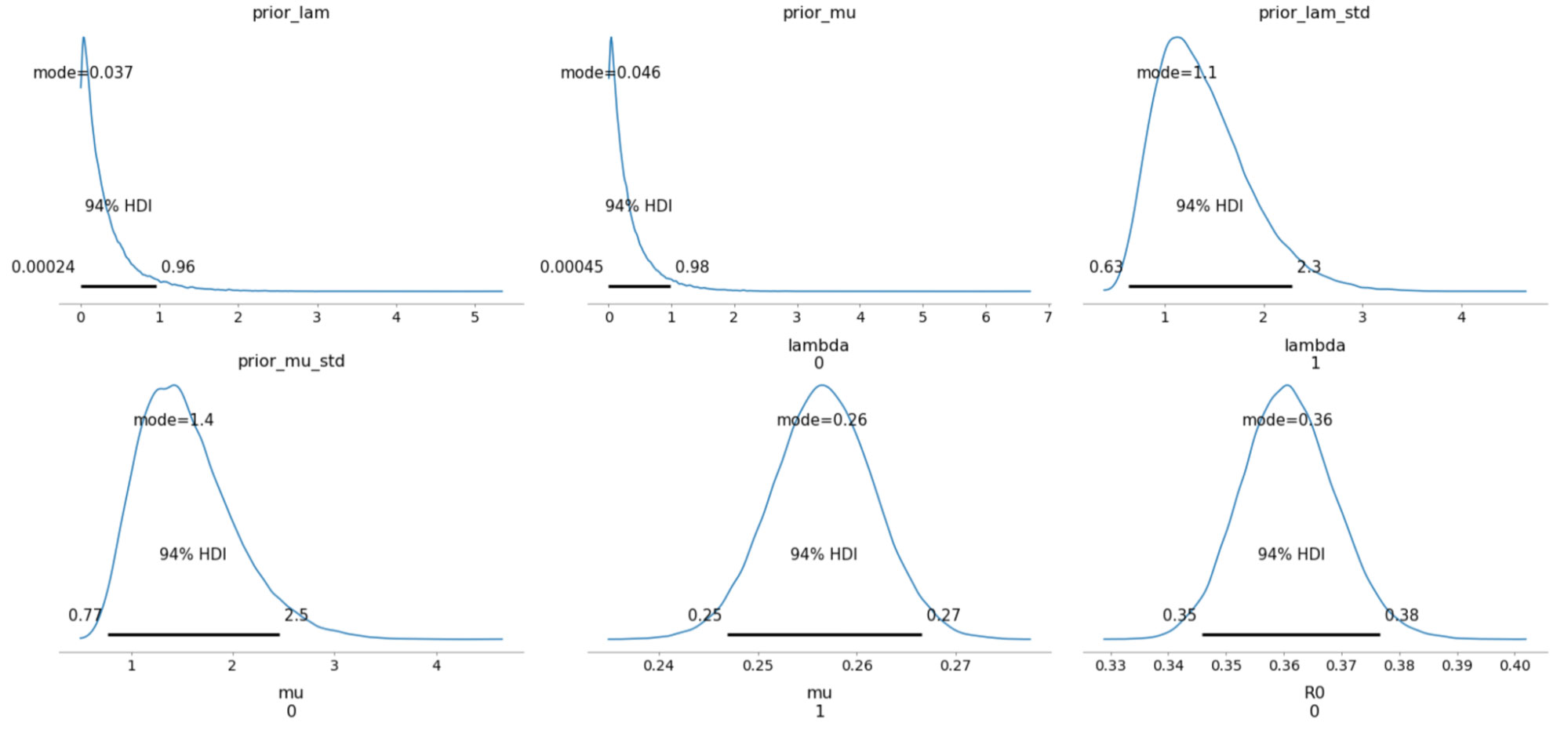
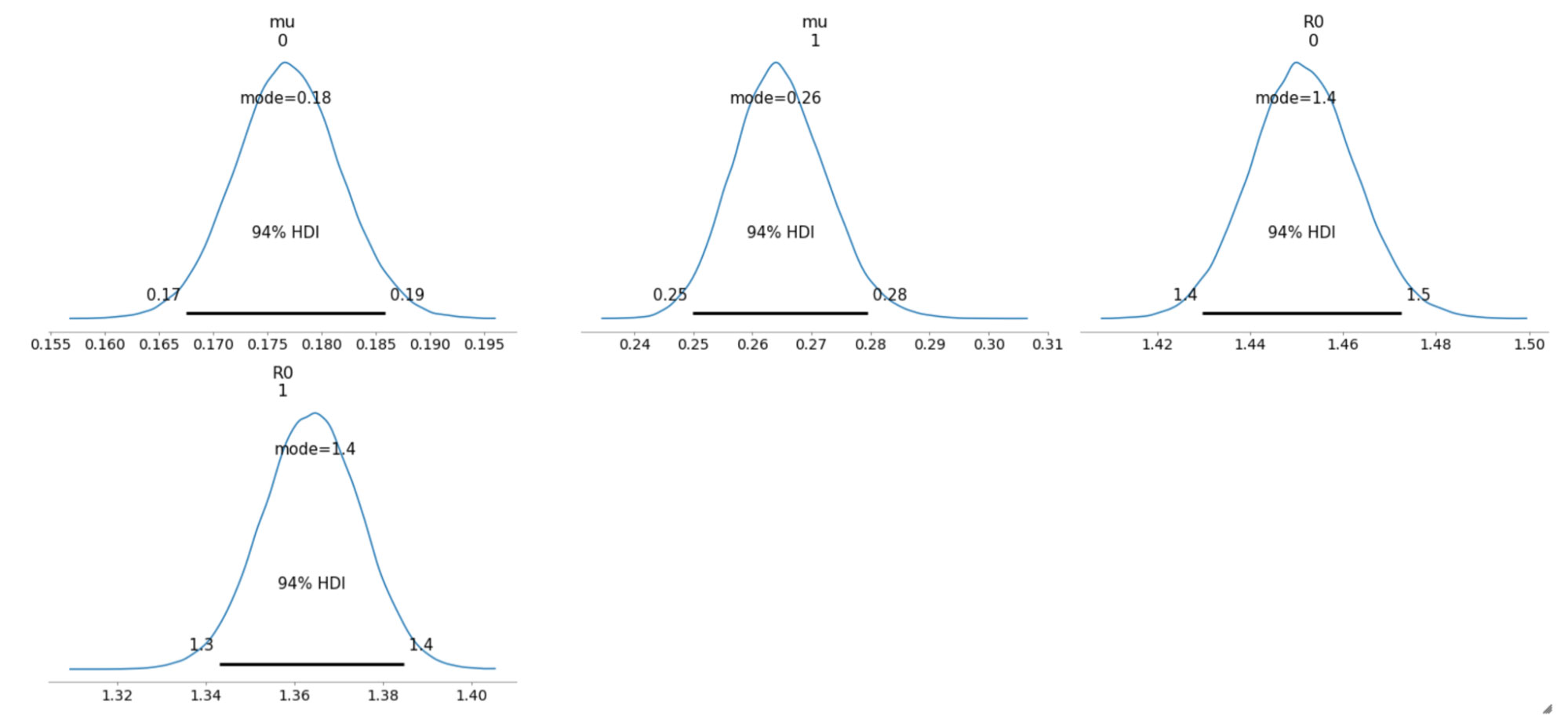
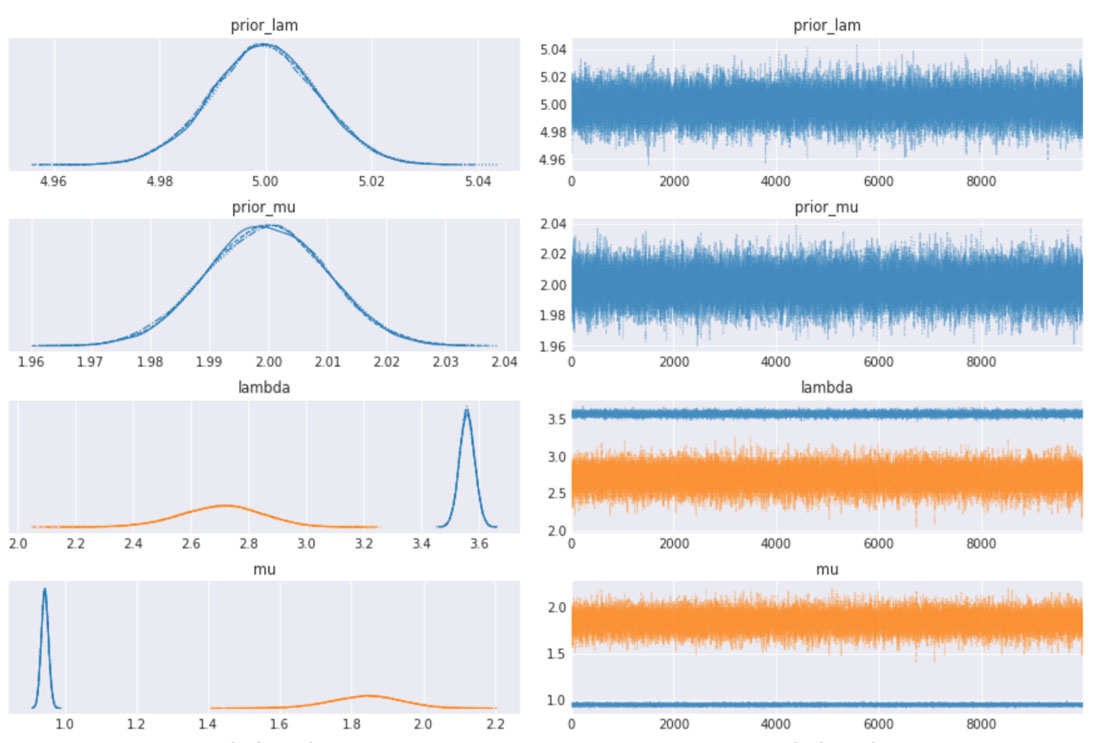
We can also inspect the traceplots for convergence, which shows good mixing in all the variables – a good sign that the sampler has explored the space well. There is good agreement between all the traces. This behavior can be confirmed with the fairly narrow HDI intervals in the plots above.
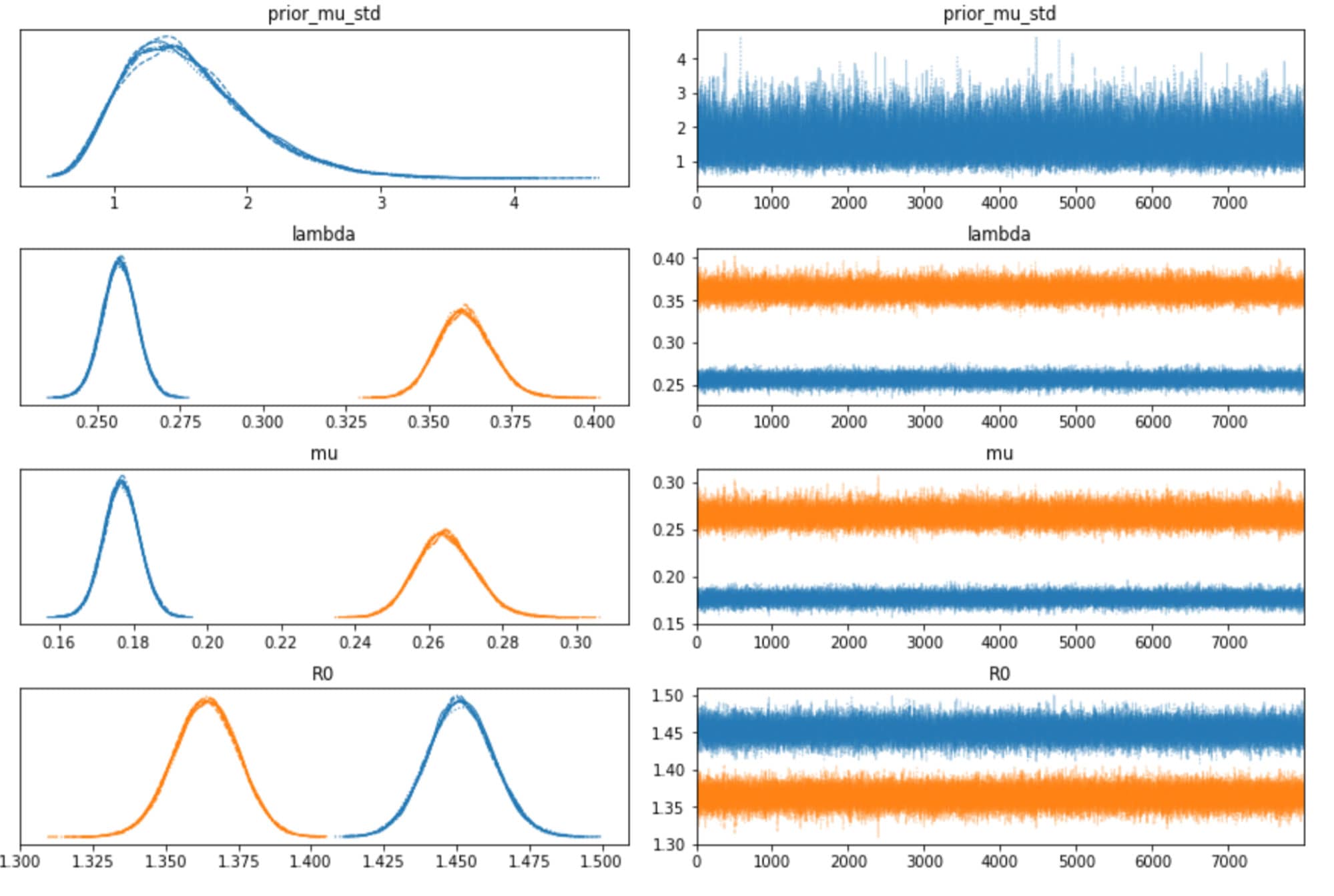
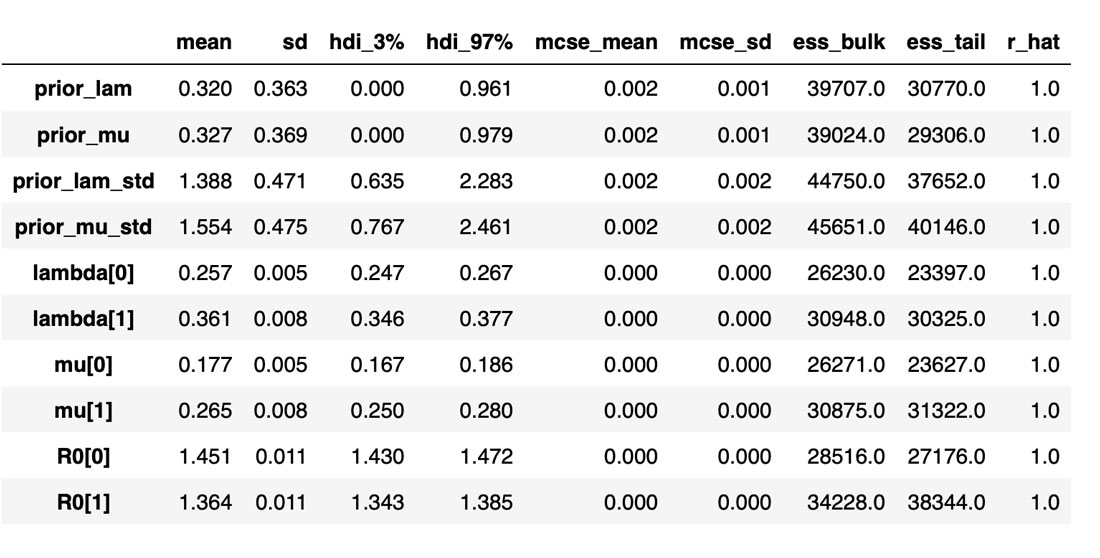
The table below summarizes the distributions of the various inferred variables and parameters, along with the sampler statistics. While estimates about the variables are essential, this table is particularly useful for informing us about the quality and efficiency of the sampler. For example, the Rhat is all equal to 1, indicating good agreement between all the chains. The effective sample size is another critical metric. If this is small compared to the total number of samples, that is a sure sign of trouble with the sampler. Even if the Rhat values look good, be sure to inspect the effective sample size!
Although this yielded satisfactory estimates for our parameters, often we run into the issue of the sampler not performing effectively. In the next post of this series, we will look at a few ways to diagnose the issues and improve the modeling process. These are listed, in increasing order of difficulty, below:
- Increase the tuning size and the number of samples drawn.
- Decrease the target_accept parameter for the sampler so as to reduce the autocorrelation among the samples. Use the autocorrelation plot to confirm this.
- Add more samples to the observed data, i.e. increase the sample frequency.
- Use better priors and hyperpriors for the parameters.
- Use an alternative parameterization of the model.
- Incorporate changes such as social-distancing measures into the model.
You can learn more about these topics at my Coursera specialization that consists of the following courses:
- Introduction to Bayesian Statistics
- Bayesian Inference with MCMC
- Introduction to PyMC3 for Bayesian Modeling and Inference
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.