How YipitData Extracts Insights From Alternative Data Using Delta Lake
by Anup Segu and Bobby Muldoon
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Choosing the right storage format for any data lake is an important responsibility for data administrators. Tradeoffs between storage costs, performance, migration cost, and compatibility are top of mind when evaluating options. One option to absolutely consider for your data lake is Delta Lake, an open source, performant storage format that can radically change how to interact with datasets of any size.
With Delta Lake and its streaming capabilities, YipitData efficiently analyzes petabytes of raw, alternative data to answer key questions from leading financial institutions and corporations. This blog will outline YipitData’s general design and approach with alternative data using the Delta Lake.
How YipitData produces insights for its clients
YipitData specializes in sourcing, productizing, and distributing alternative data to the world's largest investment funds and corporations. Product teams of data analysts complete deep research on raw datasets, design accurate methodologies to answer client questions, and distribute that research over a variety of mediums. Data engineers operate as administrators to provide tooling on top of the databricks platform to make data operations convenient, reliable, and secure for product teams. Early on, product teams were focused on analyzing public web data that was relatively small in scale. The data was stored in Parquet and transformed in a series of batch transformations using Apache Spark™ to inform the analyses in reports, charts, and granular data files delivered to clients.
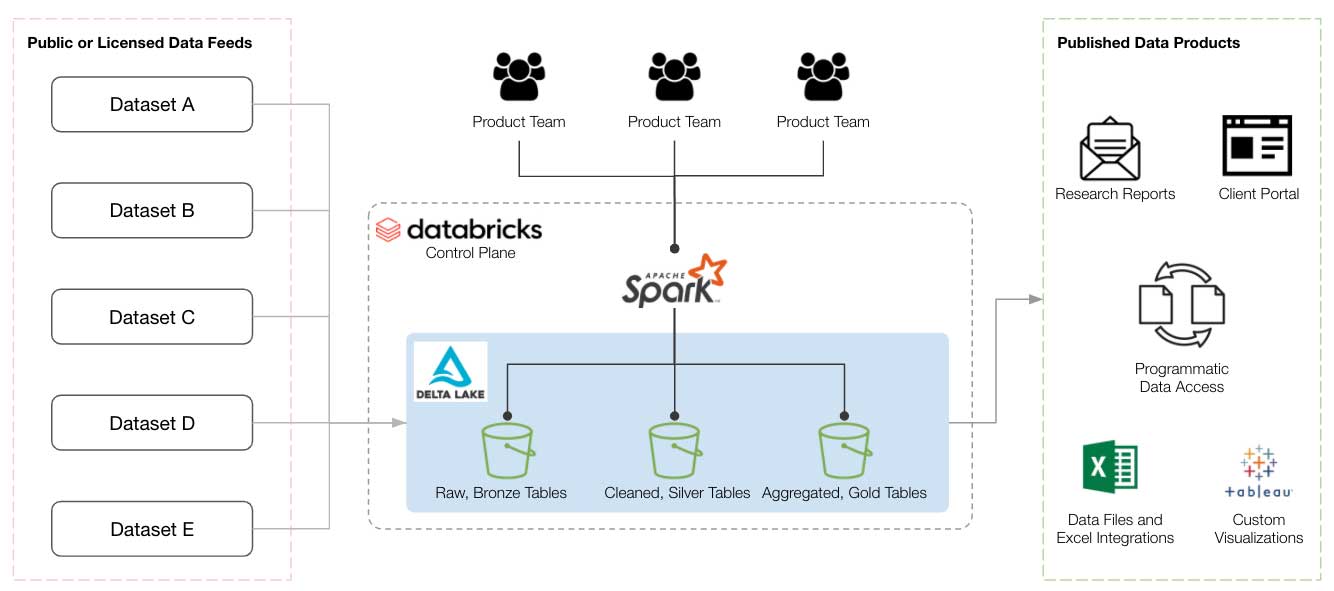
Over the last few years, teams increasingly work with a variety of new source data, such as card, email, and many other data types, to deliver research on 100+ companies and counting. These new data sources are dramatically increasing YipitData's ability to provide market insights across a variety of verticals and better service its clients.
Challenges with Alternative Data
As the number of data sources increased, the scale and volume of new datasets were concurrently growing. Traditional approaches of using batch transformations were not scaling to meet the needs of product teams.
- Large, frequent data deliveries required constant refreshes of downstream analyses in a short timeframe.
- Batch transformations would take too long, which was an important consideration in providing timely insights to clients from new data sources.
- Techniques to understand shifting data trends on production tables became complicated and unreliable for analysts with data at this scale.
- Attempts to use incremental streaming transformations were plagued by unexpected and unverifiable changes in ETL pipelines.
YipitData needed to update its approach to ingesting, cleaning, and analyzing very large datasets, to continue to fulfill its mission of helping clients answer their key questions.
Delta is a robust data storage solution that improves analytics
YipitData analysts now use Delta Lake as the storage layer for all ETL processes and ad hoc exploration to analyze alternative data. This allows them to:
- Leverage Delta's structured streaming APIs that offer intuitive, reliable, and efficient transformations on high volume datasets.
- Track changes in transformed data and retain past versions using Delta’s transaction layer to reduce the risk of data loss or corruption.
- Perform QA using Delta time travel on data generated via complex batch transformations.
- Gain a "source of truth" as Databricks autoloader reliably converts data feeds from third-party providers into "bronze" Delta tables.
Delta streaming facilitates high-volume data ingestion
Product teams are increasingly focused on extracting value from large datasets that YipitData sources externally. These raw datasets can be upwards of several TBs in size and add 10-20 GB of new data across hundreds of files each day. Prior to Delta, applying transformations via batch was time-consuming and costly. Such transformations were inefficiently reprocessing ~99% of the dataset every day to refresh downstream analyses. To generate a clean table of up-to-date records, the following code was used:
With Delta streaming, analysts can reliably and exclusively operate on the incremental data delivered and exponentially increase the efficiency of ETL workflows. Delta's declarative APIs make it easy to surgically add, replace, or delete data from a downstream Delta target table with transaction guarantees baked in to prevent data corruption:
Using APIs such as .merge, .whenMatchedDelete, and .whenMatchedUpdate, data processing costs on this dataset were reduced 50% and runtime by 75%.
While some ETL workflows created by YipitData analysts are conducive to structured streaming, many others are only possible via batch transformations. Retaining outdated data from batch transformations is useful to audit and validate the data products that are shipped to clients. With Delta, this functionality comes out of the box as each table operation creates a new version of that table. Analysts can quickly understand what operations were performed to the datasets they publish and even restore versions to revert any unanticipated changes.
Using the HISTORY operation, YipitData analysts gain visibility into the "who, what, where, and when" regarding actions on a table. They can also query past data from a table using Delta Time Travel to understand the state of the table at any point in time.
In the scenarios where a table was overwritten incorrectly, Delta offers a handy RESTORE operation to undo changes relatively quickly. This has substantially improved the durability of production data without requiring complex solutions from the engineering team. It also empowers analysts to be more creative and experimental in creating new analyses as modifying data stored in Delta is far less risky.
Creating a "source of truth" with Databricks Autoloader
As YipitData increasingly ingests alternative data from a variety of sources (web, card, email, etc.), keeping an organized data lake is paramount to ensuring new data feeds get to the right product owners. Databricks Autoloader has allowed YipitData to standardize the ingestion of these data sources by generating "Bronze Tables" in Delta format. Bronze tables serve as the starting point(s) for analyst-owned ETL workflows that create productized data in new, downstream "Silver" and "Gold" tables. YipitData analysts complete their analysis only on Delta tables and do not have to deal with the challenges of working with raw data formats that typically offer worse read performance, among other drawbacks.

Autoloader specifically manages data ingestion from common file formats (JSON, CSV, Parquet, etc.) and updates Delta tables incrementally as the data lands. The HISTORY of the table is also used to understand how much data has been delivered and to query the past versions of these tables to debug issues with downstream ETL workflows.
Migrating YipitData's data lake to Delta
To fully realize the benefits of Delta, migrating all existing workloads to store data in Delta format instead of Parquet was necessary. YipitData has over 60,000 tables housing petabytes of data, so the migration process was important to consider. Prior to this migration, analysts had an in-house PySpark function developed by the data engineering team to generate tables from SQL queries or dataframes. This "create table" utility standardized table creations in Parquet format by wrapping the PySpark dataframe APIs.
Delta operations support all spark dataframe APIs, so it was straightforward to switch to writing as Delta instead of Parquet. For tables that were in Parquet format, the CONVERT operation migrates the tables to Delta in place without duplicating cloud storage files. Through the use of these two features, the create table utility is reimplemented under the hood and all data in ETL workflows are converted to or written out in Delta automatically. As a result, YipitData's entire data lake switched to using Delta with minimal impact for its analysts.
Conclusion
YipitData’s success is driven by its ability to answer clients' questions quickly and accurately. With structured streaming ingestion backed by Delta, YipitData is able to quickly and reliably ingest, clean, and analyze very large, valuable alternative datasets.
- Declarative streaming APIs drastically reduce ETL runtime leading to timely, valuable insights for clients.
- Delta provides transactions for every table operation, which allows YipitData analysts to create resilient ingestion pipelines that they can monitor.
- Data streamed into Bronze Delta tables via autoloader can be queried and transformed by any number of downstream users, helping permeate raw data across numerous product teams.
As a result, YipitData analysts can independently incorporate new data sources using delta into multiple data products to answer their clients' questions. These sources even fuel new product development for the company. At the same time, Delta is evolving, and YipitData is excited to continue to unlock business opportunities through its data lakehouse platform.
Read More
How yipitdata slashed over 2.5 million off of aws bill
Using Databricks as an Analytic Platform at Yipitdata
Recurring data delivery and ingestion with S3 bucket replication
How Yipitdata uses Databricks integration with AWS glue
Customer Story - YipitData turns to its data team to transform financial market information overload into insight.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.