Catalog and Discover Your Databricks Notebooks Faster
by Darin McBeath and Vuong Nguyen
As a global leader in information and analytics, Elsevier helps researchers and healthcare professionals advance science and improve health outcomes for the benefit of society. It has supported the work of its research and health partners for more than 140 years. Growing from its roots in publishing, Elsevier provides knowledge and valuable analytics that helps users make breakthroughs and drive societal progress. Digital solutions such as ScienceDirect, Scopus, SciVal, ClinicalKey and Sherpath support strategic research management, R&D performance, clinical decision support, and health education. Researchers and healthcare professionals rely on Elsevier’s 2,500+ digitized journals, including The Lancet and Cell; 40,000 eBook titles; and its iconic reference works, such as Gray's Anatomy.
Elsevier has been a customer of Databricks for about six years. There are now hundreds of users and tens of thousands of notebooks across their workspace. To some extent, Elsevier’s Databricks users have been a victim of their own success, as there are now too many notebooks to search through to find some earlier work.
The Databricks workspace does provide a keyword search, but we often find the need to define advanced search criteria, such as creator, last updated, programming language, notebook commands and results.
Interestingly, we managed to achieve this functionality using a 100% notebook-based solution with Databricks functionalities. As you will see, this makes it easy to set up in a customer’s Databricks environment.
API-first approach to scan for notebooks
Databricks provides a robust set of APIs that enables programmatic management of accounts and workspaces. For this solution, we leverage the Workspace API to programmatically list and export notebooks and folders inside our workspace.
We also parallelize the API calls to speed up the cataloging process and make it configurable within Databricks’ rate limit of 30 requests per second. To avoid the “429: Too Many Requests” error, we have implemented the exponential retrying mechanism inspired by the Delta Sharing Apache Spark™ connector.
Cataloging using Parquet
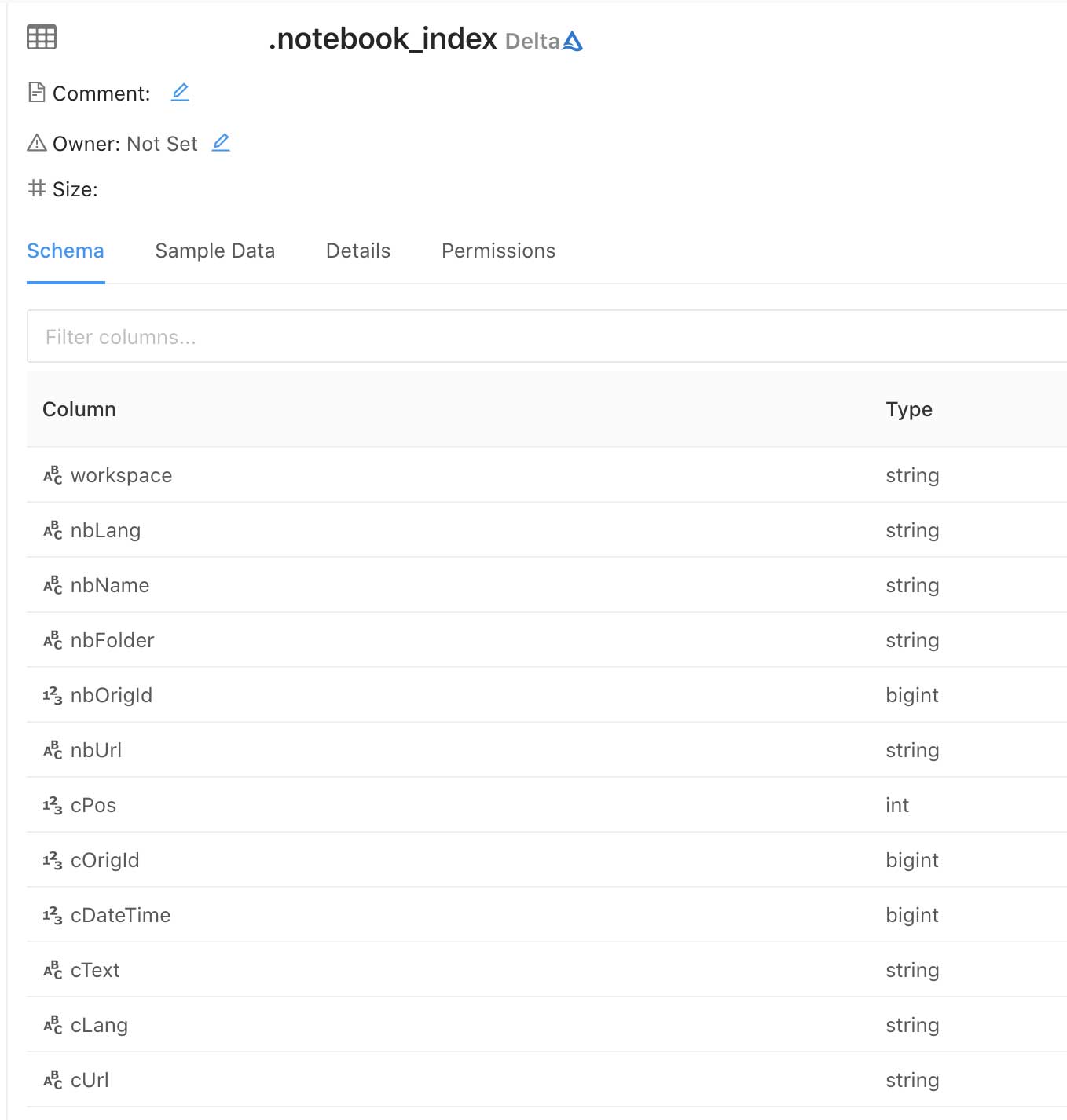
This solution does not require any external full-text search system like Solr or ElasticSearch. Instead, we leverage Parquet files for our notebook index. The index is simply a data table where each row describes a separate command cell. Each row includes fields for:
- Notebook information: language (nbLang), name (nbName), folder path (nbFolder), url (nbUrl)
- Command information: cell text (cText), last-run date (cDateTime), cell language (cLang), url (cUrl)
A notebook-based solution for notebook search
The index and search functionalities are provided by three notebooks (NotebookIndex, NotebookSearch and NotebookSimilarity). Two helper notebooks (NotebookIndexRun and NotebookSimilarityRun) make it easy to configure the index and similarity capabilities.
NotebookIndex
The notebook-based solution leverages the Workspace API to export notebooks programmatically and populate our Parquet table.
Most organizations will have Workspace object access control enabled so that a user can only manage their own notebooks and those in the Shared location. NotebookIndex runs only with the permissions of the user and is limited to notebooks that user can view.
If an organization wants a full catalog of all notebooks in their workspace, an administrator must run the indexing to have a workspace-level catalog. In addition, we expect most organizations will have users and workgroups creating their own index files, which will only contain records for notebooks the users are allowed to see.
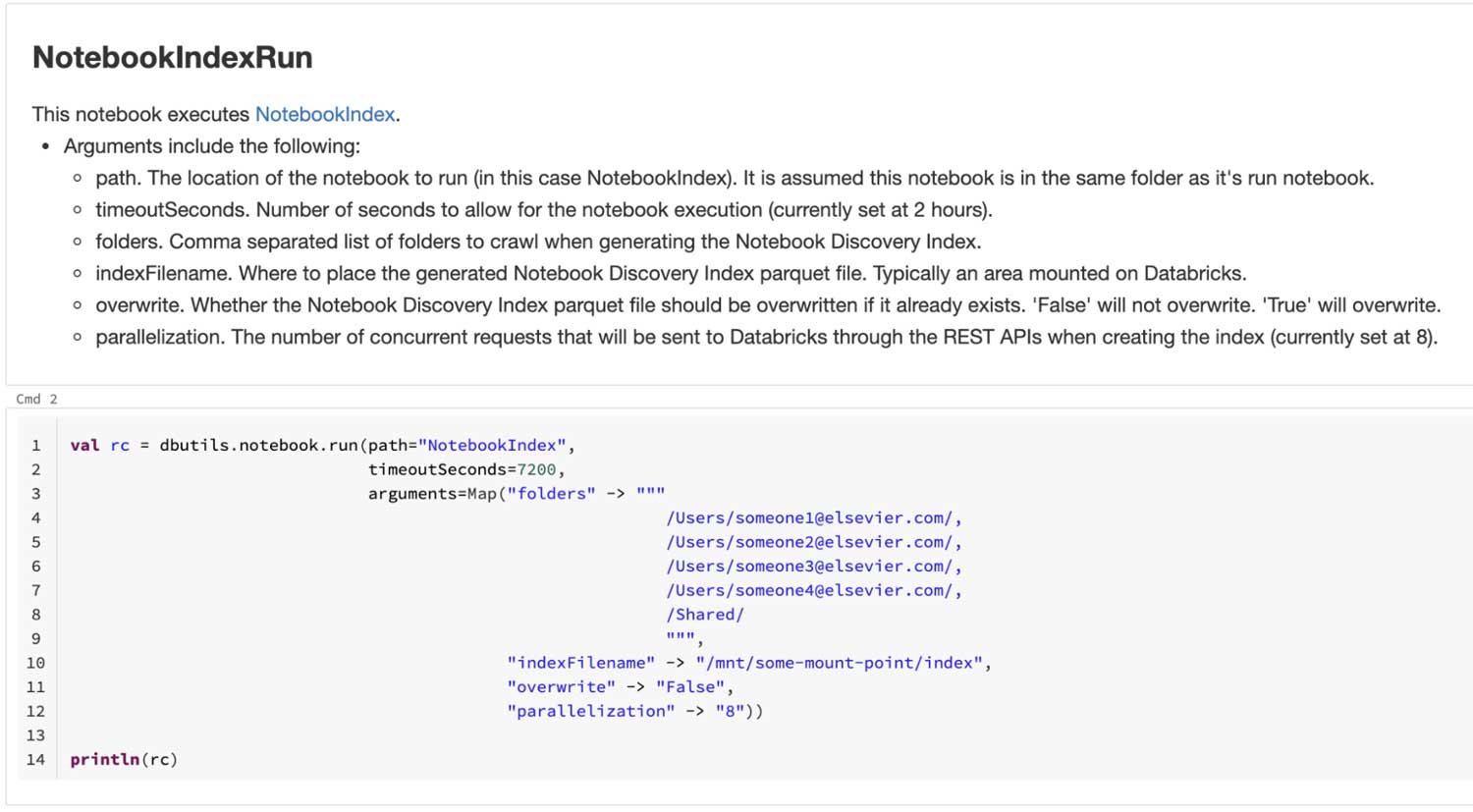
NotebookIndexRun
This is a helper notebook for users or groups to run the indexing process. It lets them select which user folders will be scanned -- such as their own or perhaps the members of their group. Elsevier found this particularly useful for users in the Labs group.
As noted above, only notebooks readable by the user running the indexing notebook will appear in the index. In the following example, the notebooks contained in the /Shared/ folder, and in someone1, someone2, someone and someone,user folders will be indexed.
NotebookSearch
Each user that wants to use NotebookSearch should clone this notebook into their own workspace. The notebook provides examples for searching the index table described earlier. We expect users will edit their copy to specify which table to use and then customize the examples to suit their needs. Several examples of such searches are given later on in this blog.
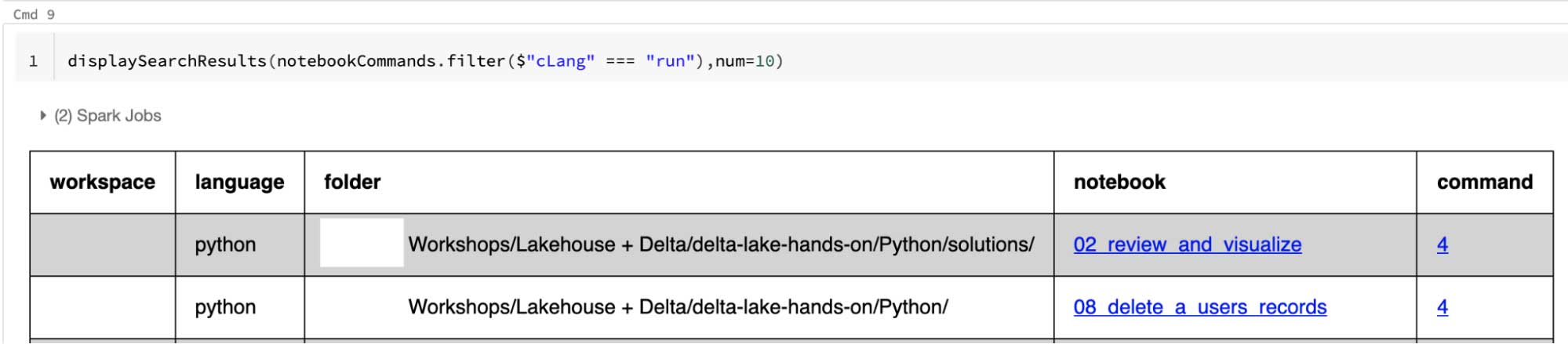
Beyond the examples, we have also provided a displaySearchResults function that displays the search results using HTML to be more user friendly:
- The language column identifies the language for the command, and the folder indicates the folder location where the notebook (identified in the notebook column) is stored.
- The notebook links take you to the notebook containing the match.
- The command links take you to the actual command cell within the notebook.
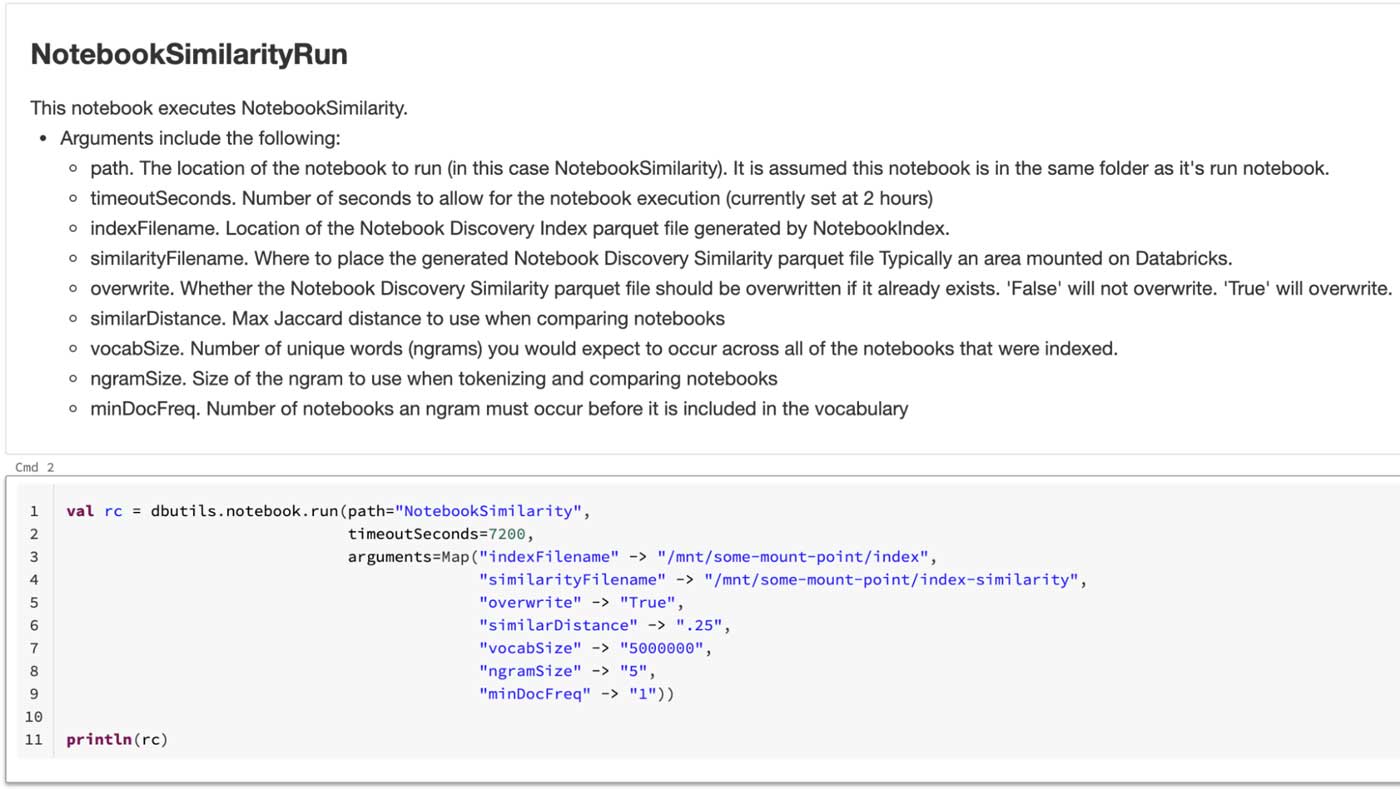
NotebookSimilarity and NotebookSimilarityRun
Now that we’ve captured all commands in all notebooks within our workspace, we can run further analysis on the notebook catalog. One idea is to identify similar notebooks using Natural language processing (NLP) techniques.
Since there is currently no provenance chain to trace the history of notebooks as they are cloned, this helps to identify notebooks that have been potentially cloned from one another. While it’s not possible to identify the initial notebook from where other notebooks were cloned, we can identify notebooks with very similar text based on a threshold.
There are many other measures of similarity, each with its own eccentricities. The NotebookSimilarity notebook demonstrates a simple example using Jaccard distance by representing each notebook as sets of words.
We apply some simple preprocessing to remove markdown, results and empty cells and combine all notebook commands as a string. We then leverage the MinHash function for Jaccard distance in MLlib, which allows for scalability to tens of thousands of notebooks.
This compares notebooks discovered in the index table to produce a similarity score. Instead of keeping a full matrix of all similarities, we specify a maximum similarity distance (e.g., 0.1). For every notebook, a list of notebooks within that distance is kept ready for searching.
Example use cases: shell, Spark SQL and Scala
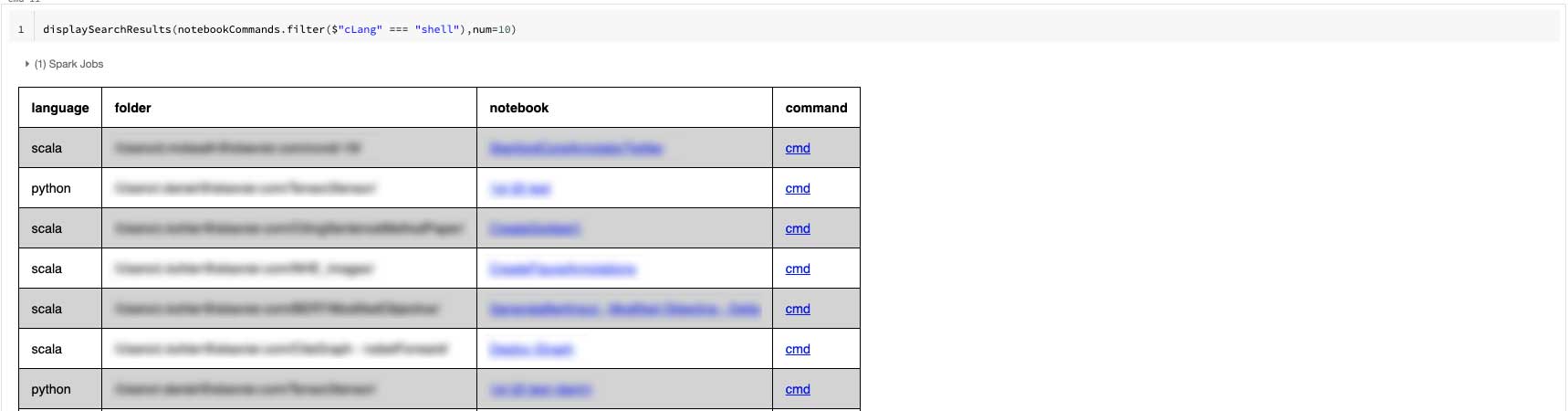
Wouldn’t it be nice to know which notebooks contain commands that leverage shell commands? The following example searches for shell commands. In other words, the cell starts with the magic command %sh. (Note:while we are looking for specific cells that use shell commands, they will appear within notebooks that have an overall default language. Thus, it makes sense to show the first column that tells what that default language is.)
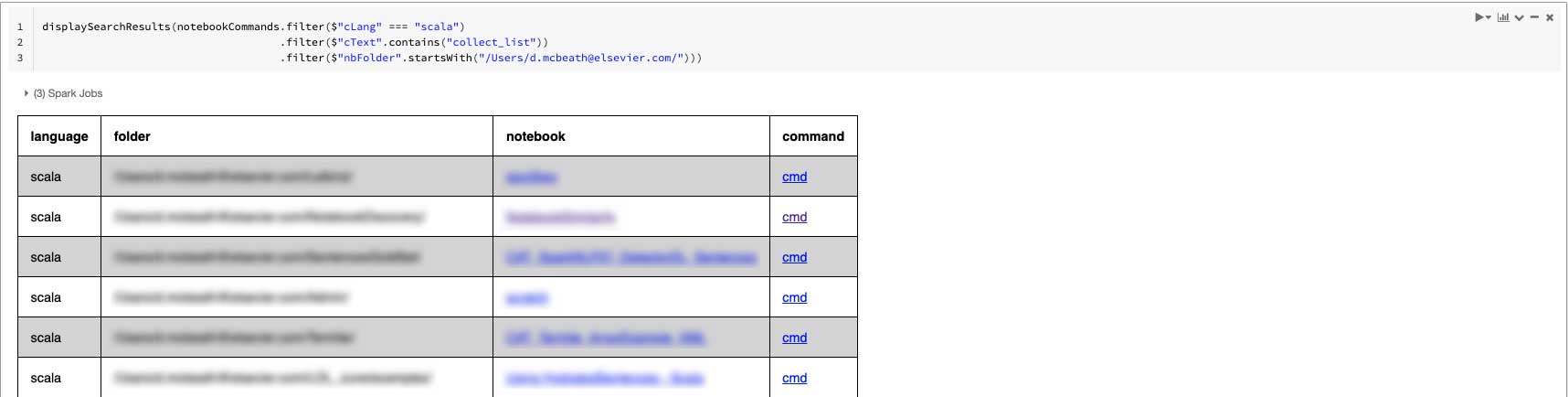
Do you ever run into the situation of trying to remember how to use a specific Spark SQL function – maybe one you or a buddy has used? Wouldn’t an in-context example be more helpful than resorting to a web search and hoping to find a needle in the web haystack? The following example searches for commands within a specific user's area containing the string “collect_list.”
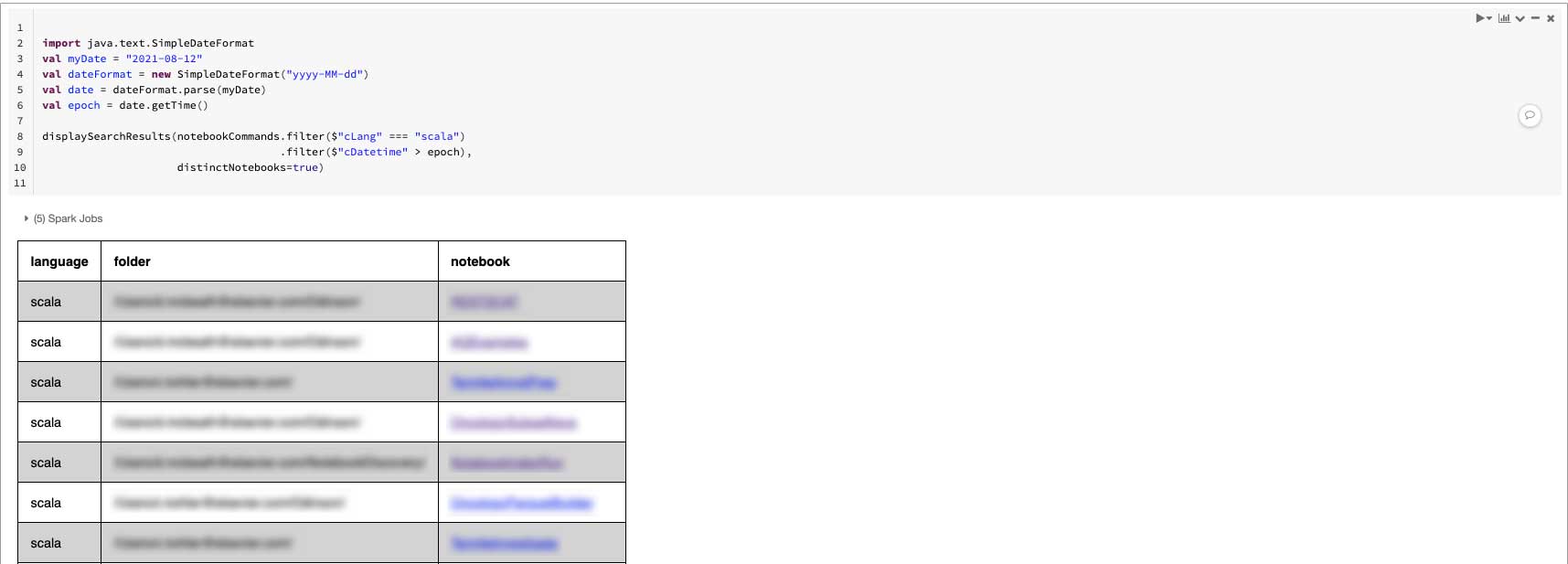
Do you ever wonder what notebooks have been executed recently? The following example searches for notebooks containing a cell that has been executed since Aug. 12, 2021. By specifying distinctNotebooks=true, we roll up all of the commands (containing a match) for the same notebook to a single hit for the notebook and only present a link to the notebook.
The above basic examples only scratch the surface for what can be searched in the index table. The following are some representative questions we have seen on the Databricks Community (formerly Forums) over the past couple of years and should easily be addressed by Notebook Discovery:
- I'm updating a source table and need to find all the notebooks that have that table. I tried using the search function in Databricks UI, but my problem is I'm getting results from every folder, including other users. Is there a way to conditionally limit searches to a certain folder?
- Can you search notebooks using conditionals, such as exact phrases, contains(not), wildcards or regular expressions?
- Is there a way to search for a string in all notebooks? I like to find out whether a Delta table is used in any notebooks.
- Can I search for similar commands in other notebooks for debugging?
Get started
Elsevier Labs has released this solution as the Notebook Discovery tool and is now publishing it as open source under the very permissive MIT License. Notebook Discovery is provided as a DBC (Databricks archive) file, and it is very simple to get started:
- Download the archive: Download the Notebook Discovery archive (DBC file) to a location on your machine.
- Importing the notebooks: From the Databricks UI, import the downloaded DBC file into a folder. The workspace folder where the archive is imported is unrelated to the workspace folders that you want to index.
- Generating the index file: The person generating the index file needs to edit the NotebookIndexRun helper, indicating folders to index and specify the location of the index file. The indexing process will start and produce the index file when done.
- Searching for notebooks: Other users should clone the NotebookSearch notebook into their area and edit it to use the right index file. They can then edit the searches to their liking. Several example searches are given below in the Examples section.
- Detecting similar notebooks: If users want to look for similar notebooks, they need to edit the NotebookSimilarityRun file and run the job to generate the similarity file.
Over the past couple of months, Elsevier users have found Notebook Discovery to be very useful and decided to share this with the community. We hope you benefit from using this tool as well.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.