100 Years of Horror Films: An Analysis Using Databricks SQL
by Mikaila Garfinkel, Hector Leano and Dan Morris
When it comes to the history of film, perhaps no genre says more about us as humans than horror, which taps into our biggest phobias and uncertainties about the world. With such a huge range – from gruesome to symbolic to comedically terrible – we thought it’d be interesting to analyze IMDb data on horror films from each decade and see what insights we’d discover. More specifically, we wanted to know things like: How has the popularity of certain subgenres shifted over time? How have the most popular horror films influenced the genre as a whole?
This blog post will walk through how we did just that using Databricks SQL and data from IMDb, the world’s most popular and authoritative source for movie, TV and celebrity content data. We thought this would be a fun way (especially with Halloween around the corner) to show just how easy it is to use Databricks SQL to immediately start querying data and creating visuals to draw quick insight.
Explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Why Databricks SQL?
Databricks SQL is a service that allows users to easily perform BI and SQL directly on their data lake for reliable, lightning-fast analytics. Normally on a data warehouse, this would require data teams to integrate a BI tool and then spend hours setting up the data pipelines and processing the data via ETL. With Databricks SQL, because we're able to query directly from a lakehouse, once we downloaded our data from IMDb (see below), we were able to start querying almost immediately and creating visuals within 30 minutes – all within a single platform.
For our analysis, we used a data set that included over 30,000 horror films from IMDb; we chose this sample data set since it’s easily accessible and available to developers. IMDb is an ideal source for any film analysis, as it includes hundreds of millions of searchable data items – including over 8 million movie, TV and entertainment titles. IMDb also leverages AWS Data Exchange, which makes it easy to find, subscribe to and use third-party data in the cloud, to provide essential metadata for every movie, TV and OTT series, and video game title in its catalog (scroll to the end of this blog for more info on IMDb as a data source).
Horror trope trends by decade
The first question we wanted to answer is: When looking at the films by decade, are there any observable trends on specific tropes (e.g. monsters, theme, etc.)? To do this, we calculated term frequency for every word that appeared in every title. From there, we used this as a foundation to identify commonly used “horror terms” and group them together. We identified the main tropes as these:
- Vampire
- Ghost
- Halloween
- Children’s Toys
- Possession
- Zombie
- Witch
- Monster
A simple word cloud gives us a high-level overview of the canon – apparently ghost films have always been a popular choice for filmmakers!
Let’s look at this more granularly. Our approach was simple. We took the tropes listed above and created an ontology to classify which movies are associated with each trope. For example, to identify movies within the ghost category, we included variations of: ghost, poltergeist, spirit, phantom and haunting. These variations were easily determined by the term frequency list. Here’s what ghost’s final set looked like:
| Ghost |
| ghost |
| GHOST |
| Ghost-Cat |
| Ghost, |
| Ghost: |
| Ghost's |
| Ghostbusters |
| Ghostbusters: |
| Ghosted |
| Ghostface |
| Ghosthunters |
| Ghosting |
| Ghostly |
| Ghostman |
| Ghosts |
| Poltergeist |
| Phantom |
| Phantoms |
| Spirit |
| spirit |
| Spirited |
| Spirits |
| Souls |
| Soul's |
| Soul |
| soul |
| Haunted |
| HAUNTED |
| haunted |
| Haunted: |
| Haunter |
| Haunting |
| Hauntings |
| Haunts |
Since we wanted to see how these different themes trended over time, we used the ontology to classify which movies belong to which trope. We then calculated and visualized the distribution of movies belonging to each trope by decade. The results were pretty interesting!
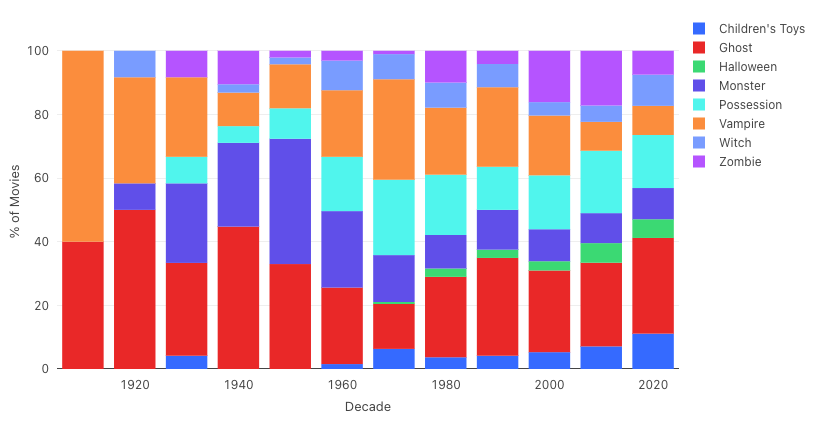
Our insights
As you can see, the early 20th century was pretty limited in terms of tropes and also contained the most vampire films from our data set. Interestingly, Dracula, probably the most famous vampire works, was published in 1897, so there is a potential correlation between this work and the prevalence of vampire films.
Another interesting point is the spike of possession films starting in the 70s. Again, this makes sense when looking at the horror film canon, as The Exorcist, arguably one of the most influential horror films ever made, premiered in 1973.
And finally, our data set shows a huge spike in monster films, which quickly tapered off in the second half of the 20th century. This does align with the canon timeline, as popular and influential films such as Godzilla, King Kong and Creature from the Black Lagoon premiered in the 1950s; it would be interesting to do a deeper analysis to see why this eventually trended downwards.
Zombie films had momentum in the 80s following the Dawn of the Dead (1978), a huge commercial success. But it made a huge comeback in the early 2000s, which is when the heavy-hitter zombie movies also hit the scene: 28 Days Later (2002), Resident Evil (2002) and the first “Rom Zom Com” Shaun of the Dead (2004). This “copycat” effect is definitely worth exploring more, and in a deeper analysis, we would like to look at the revenue and profitability of all these films.
Conclusion
While this blog post is meant to showcase the power of data analytics through a fun use case (and it gave us a good excuse to geek out on movies), more than that, it shows how simple it is to take a relatively large metadata set and start generating fast insights with SQL and visualizations. Often media companies are sitting on all sorts of data but aren’t sure how to derive value from it. We wanted to demonstrate how an analyst familiar with SQL but not more complex data science languages can start exploring these data sets to create interesting audience experiences. At Databricks, we’re all about making things simple for data practitioners of all titles and levels.
To dive into more entertainment use cases, check out our Media & Entertainment Solution Accelerators.
More about IMDb
With hundreds of millions of searchable data items, including over 8 million movie, TV and entertainment titles, more than 11 million cast and crew members and over 12 million images, IMDb is the world’s most popular and authoritative source for movie, TV and celebrity content, and has a combined web and mobile audience of more than 200 million monthly visitors.
IMDb enhances the entertainment experience by empowering fans and professionals around the world with cast and crew listings for every movie, TV series and video game, lifetime box office grosses from Box Office Mojo, proprietary film and TV user ratings from IMDb's global audience of over 200 million fans, and much more.
IMDb licenses information from its vast and authoritative database to third-party businesses, including film studios, television networks, streaming services and cable companies, as well as airlines, electronics manufacturers, non-profit organizations and software developers. These businesses rely on the IMDb database to improve their own customers’ experience, power investment decisions, shape sentiment analysis, inform content acquisition strategies, and much more. Learn more at developer.imdb.com.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.