Understanding New Years Trends: A Simple, Unified Pipeline on the Databricks Lakehouse
Try the notebooks referenced throughout this post. Overview, Tweet Ingestion, Tweet Categorization & Result Population
For many people, the start of a new year marks the perfect time to make a change. That’s why, despite the rather polarizing nature, New Year’s resolutions remain an important tradition for kickstarting a personal goal.
Oftentimes, they’re not terribly creative – improve fitness, adopt a hobby, go someplace new. But over the past two years, as we collectively handle a global pandemic, many of us have experienced a shift in mindset on what’s important or what success means. We’ve seen this shift in all sorts of ways — The Great Resignation, definitions of wealth, new norms for socializing and more.
With this in mind and the onset of 2022, a few of us at Databricks thought it would be interesting to examine how post-pandemic life has impacted New Year’s resolutions, which are essentially snapshots into the most popular goals and trends. To do this, we used Databricks and the Twitter API to perform keyword search based on a pre-trained collection of word vectors provided by GloVe — and the results were pretty interesting.
This blog post will walk through how exactly we went about executing this use case leveraging Databricks, the Twitter API and easily-accessible open source tools. Then, we’ll share the findings of our analysis, which we think truly reflect the changing nature of the times. Let’s dive in!
Why Databricks?
First, let’s give a brief intro to Databricks and why it made this use case so simple to execute.
To perform this use case, we needed to aggregate the relevant data set from Twitter, process and prepare it for our keyword search, classify it, and then store the results in a place where the data can be queried and visualized in meaningful ways. Databricks offers us all of these capabilities out of the box with our Lakehouse platform, which combines the reliability, performance and governance of data warehouses with the openness and flexibility of data lakes. Not a single external system needed to be set up.
Databricks facilitates easy implementation of the Lakehouse architecture and Delta Lake as a managed service, allowing data practitioners to take advantage of the cost-effective and highly-scalable nature of cloud object storage while also enabling performant queries and visualizations to be built on top of the stored data. Best of all, it does all of this without requiring data to be converted to a proprietary format or funneled into a traditional data warehouse. This means that an entire data team (data scientists, analysts, and data engineers) can execute this use case end-to-end with the tools they are most comfortable with and within an open, collaborative environment.
How we did it
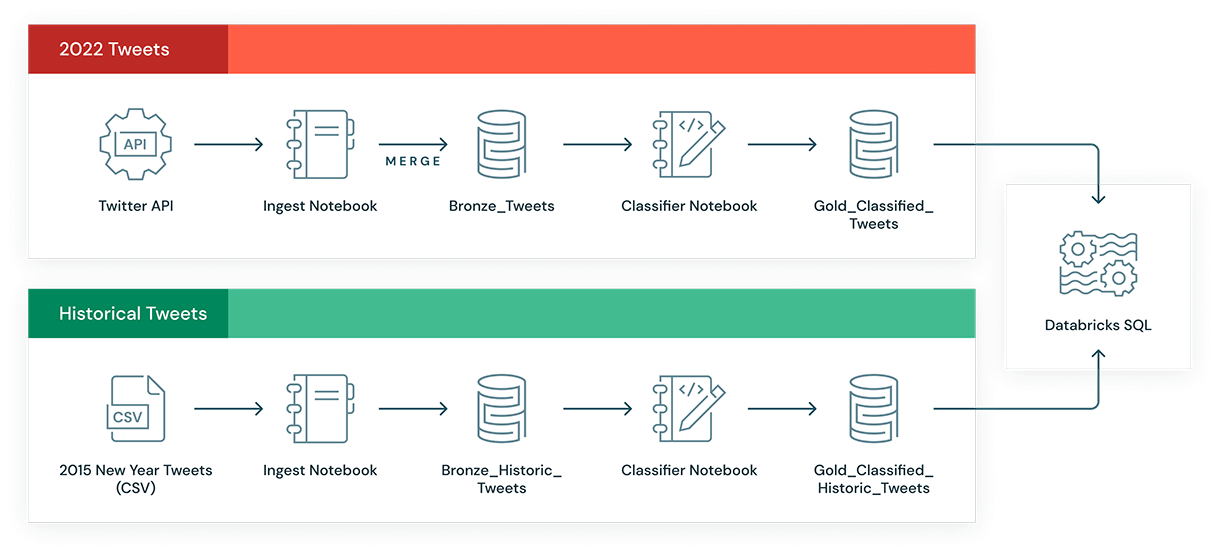
Data Ingestion & Processing
The first step was in many ways the hardest: determining what data set we’d use to capture global New Year’s resolutions. We determined Twitter was the best option since it’s a conversational platform with a global user base, is easily searchable and comes with a Developer API. Since the goal was to compare pre and post-pandemic goals, we needed a historical data set. We used a historical dataset from 2015 that provided over 5,000 New Year’s resolution-related tweets.
For comparison’s sake, we then aggregated a data set of relevant tweets from this year using the Twitter API. First, we built a Notebook to ingest tweets and build our data set. We collected tweets based on selected phrases – #NewYearsResolutions and associated hashtags and keywords – between the dates of 12/17/2021 and 1/2/2022. We ended up with quite a large sample of tweets, so we randomly sampled approximately 10,000 of them to be more in line with the size of our historic data set.
To accelerate the ingestion step, we used Tweepy, a Python library that makes it easy to interact with the Twitter API. As an aside, since Databricks notebooks allow for mixing languages, it was very easy to run a shell command to import the needed Python libraries into our environment and then write the rest of the code in Python. We did some cleanup of the text by removing things like URLs, punctuation, and hashtags.
With our data prepared, and once again with the help of magic commands to mix languages, we inserted a SQL statement into our notebook to MERGE the data from our Apache Spark™ Dataframe into our bronze Delta Table. With every pull of the Twitter API, there were some tweets duplicated across multiple batches; the MERGE operation allows us to only push new tweets into our table, avoiding duplication.
Classifying & analyzing tweets
For this project, we followed a simplified version of a medallion architecture. In our case, we landed the pre-processed tweets into our bronze table via the MERGE, ran them through our classifier, and then used another MERGE to insert the results into our gold table. This highlights again how MERGE makes it really easy to push high volumes of unique records through a pipeline on top of Delta Lake without having to write complex logic for deduplication.
For the actual tweet classification, we used the pre-trained GloVe vectors (downloaded via Gensim) to construct relevant categories and keywords for classifying each resolution. One really nice thing about the GloVe vectors is that they were trained on over 2 billion tweets worth of data from Twitter. This solved the challenge of us not having enough training data upfront to build our own vectors.
After some discussion, we came up with these categories* as common New Year’s Resolutions themes:
- exercise
- learn something new
- finance
- eco-friendly
- outdoors
- travel
- healthy diet
- reading
- self-care
- quit smoking
* We also had an “other” category for all tweets that didn’t fit into the topics above. We ended up not using the other category for our analysis since a large portion of these tweets consisted of ads, sarcastic or funny comments, trolling, and other irrelevant messages
We came up with a few seed keywords for each category, and then GloVe provided additional keywords that were most relevant to each, giving us a basis to do our classification.
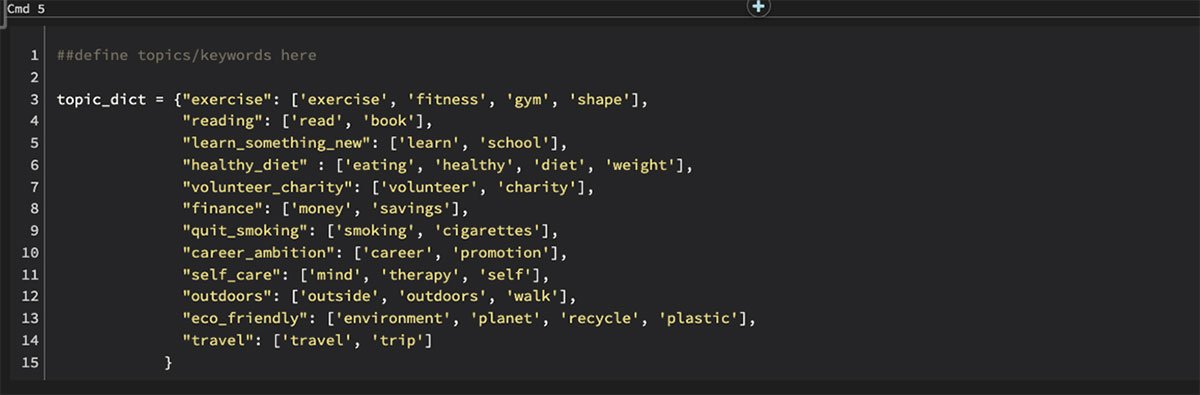
Now that we had each category seeded with a large number of keywords, we ran each tweet through our classifier to determine the dominant category. We did this by counting the number of keywords from each category that appeared in each tweet: whichever category had the largest number of matched keywords is how we classified that tweet.
We executed this process for both the 2015 and 2022 data sets. Using Databricks, we wrote these into a gold Delta Table and were able to quickly develop visualizations in Databricks SQL. This was the final product that was the basis for our analysis, which we’ll dive into below:
A glimpse into the post-pandemic mindset
While the 2015 dataset included human-labeled topics, we executed the above process for both the 2015 and 2022 data sets to classify all of the tweets according to our selected categories in order to get a consistent view.
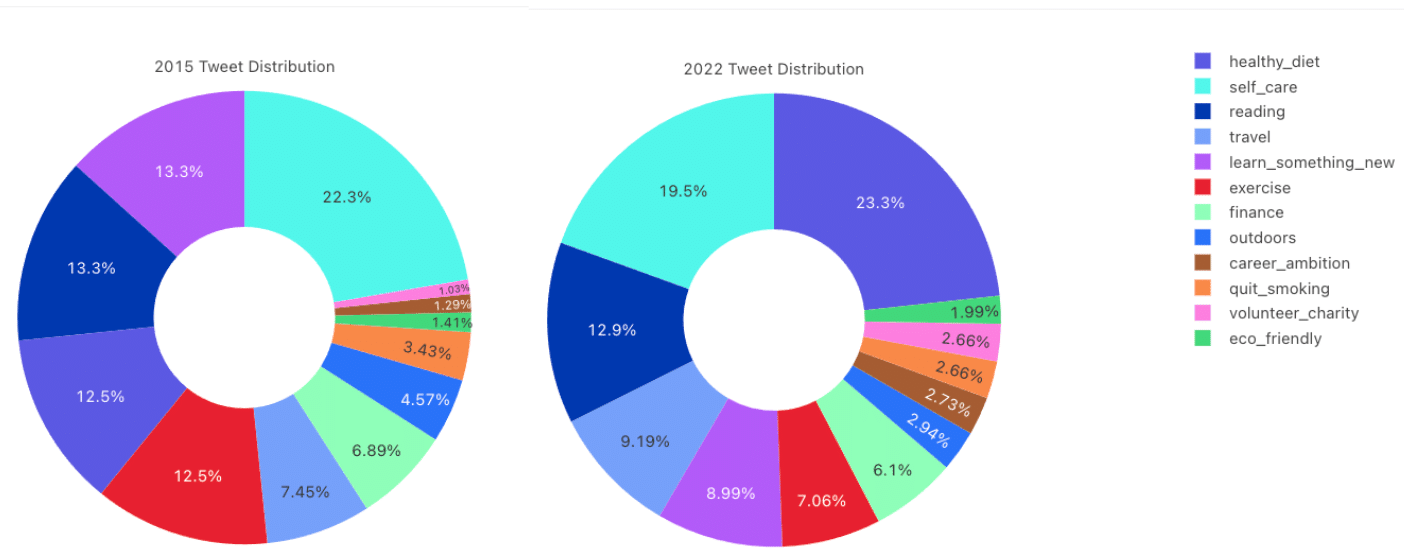
Now that our data science was complete, it was just a matter of using this data and visualizations to actually extract insights. We performed our analysis and were pretty surprised just how different the two years’ resolutions were. Here’s a summary of our findings:
A growing interest in physical health
“Eating better” and “exercising more” are some of the most stereotypical New Year’s resolutions. But when we compare 2015 and 2022, it’s clear that there’s a more meaningful shift at play.
In 2015, self-care – usually used to describe overall wellbeing with an emphasis on physical and mental behaviors, mindfulness, etc – was the most common New Year’s resolution. This theme still remains strong in 2022, as it was the second most popular resolution.
However, a stark contrast is the increased focus on physical health goals. Pre-pandemic, healthy-diet wasn’t hugely top of mind, accounting for only 12.5% of tweets. Healthy diet nearly doubled in 2022, making it the top resolution on Twitter. This dramatic change makes total sense given the context of the time. For many of us, the pandemic has pushed ideas of health risks and ailments to the top of our minds. While it might not be directly related to COVID-19, it’s not surprising to see people set goals around adopting an overall healthier lifestyle and eating habits.
Less desire to learn
Another noticeable difference between the two years is in the learn something new category, which can really describe anything from picking up a new hobby to acquiring a skill set to just expanding overall knowledge. As you can see, 2015 showed a huge interest in learning something new and ranked #2 in popularity. However, in 2022, that number shrank from 13% to less than 9%, bumping it down to #5.
Like a healthy diet, it’s possible to view this shift as a response to the past two years. In that timeframe, people have had to spend significantly more time at home, often apart from friends and most loved ones. Naturally, without the typical avenues of entertainment and going out, many of us had ample time to explore new avenues and hobbies. But two years in, it’s not surprising to see that people are rather fatigued of ‘learning’ or perhaps have already reached these goals and are ready to commit to something different, such as behaviors to improve health.
Some things never change
It’s important to note that while a lot has changed, a lot has also stayed the same in terms of what people care about and their personal motivations.
One stable New Year’s resolution was reading. While it’s great to see reading as high on the list both years, this was a little surprising given that learning-new experienced such a dip in 2022. However, its ability to remain a top priority in 2022 could be explained by fatigue around connecting online (e.g., Zoom meetings and happy hours) and more time spent online or on streaming services. With this in mind, it seems practical that a lot of people are ready to take breaks from the Internet and explore a different avenue of entertainment.
Another constant that was exciting to see was the consistent focus on self-care. While, as mentioned above, it lost its spot as the #1 resolution, there wasn’t a big change between 2015 and 2021 (22.3% and 19.5%, respectively). Considering the stresses and unknowns since 2019, all we can say is we’re happy to see that people are still prioritizing taking care of their own needs and health.
Conclusion
These are just some of our insights from comparing 2015 and 2022 New Year’s resolutions, but they do suggest a growing shift in our personal goals and interests. Even more so, this use case shows how Dabricks’ Lakehouse truly is a unified platform. Every teammate involved was able to execute every aspect of this use case on Databricks, and do it quickly and collaboratively.
New to Lakehouse? Check out this blog post from our co-founders for an overview of the architecture and how it can be leveraged across data teams.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.