Make Your Data Lakehouse Run, Faster With Delta Lake 1.1
by Scott Sandre, Ryan Zhu, Denny Lee and Vini Jaiswal
Delta Lake 1.1 improves performance for merge operations, adds the support for generated columns and improves nested field resolution
With the tremendous contributions from the open-source community, the Delta Lake community recently announced the release of Delta Lake 1.1.0 on Apache Spark™ 3.2. Similar to Apache Spark, the Delta Lake community has released Maven artifacts for both Scala 2.12 and Scala 2.13 and in PyPI (delta_spark).
This release includes notable improvements around MERGE operation and nested field resolution, as well as support for generated columns in a MERGE operation, Python type annotations, arbitrary expressions in ‘replaceWhere’ and more. It is super important that Delta Lake keeps up to date with the innovation in Apache Spark. This means that you can take advantage of increased performance in Delta Lake using the features that are available in Spark Release 3.2.0.
This post will go over the major changes and notable features in the new 1.1.0 release. Check out the project’s Github repository for details.
Want to get started with Delta Lake right away instead? Learn more about what is Delta Lake and use this guide to build lakehouses with Delta Lake.
Key features of Delta Lake 1.1.0
- Performance improvements in MERGE operation: On partitioned tables, MERGE operations will automatically repartition the output data before writing to files. This ensures better performance out-of-the-box for both the MERGE operation as well as subsequent read operations.
- Support for passing Hadoop configurations via DataFrameReader/Writer options: You can now set Hadoop FileSystem configurations (e.g., access credentials) via DataFrameReader/Writer options. Earlier, the only way to pass such configurations was to set Spark session configuration, which would set them to the same value for all reads and writes. Now you can set them to different values for each read and write. See the documentation for more details.
- Support for arbitrary expressions in replaceWhere DataFrameWriter option: Instead of expressions only on partition columns, you can now use arbitrary expressions in the replaceWhere DataFrameWriter option. That is you can replace arbitrary data in a table directly with DataFrame writes. See the documentation for more details.
- Improvements to nested field resolution and schema evolution in MERGE operation on an array of structs: When applying the MERGE operation on a target table having a column typed as an array of nested structs, the nested columns between the source and target data are now resolved by name instead of the position in the struct. This ensures structs in arrays have a consistent behavior with structs outside arrays. When automatic schema evolution is enabled for MERGE, nested columns in structs in arrays will follow the same evolution rules (e.g., column added if no column by the same name exists in the table) as columns in structs outside arrays. See the documentation for more details.
- Support for Generated Columns in MERGE operation: You can now apply MERGE operations on tables having Generated Columns.
- Fix for rare data corruption issue on GCS: Experimental GCS support released in Delta Lake 1.0 has a rare bug that can lead to Delta tables being unreadable due to partially written transaction log files. This issue has now been fixed (1, 2).
- Fix for the incorrect return object in Python DeltaTable.convertToDelta(): This existing API now returns the correct Python object of type delta.tables.DeltaTable instead of an incorrectly-typed, and therefore, unusable object.
- Python type annotations: We have added Python type annotations, which improve auto-completion performance in editors that support type hints. Optionally, you can enable static checking through mypy or built-in tools (for example Pycharm tools).
Other Notable features in the Delta Lake 1.1.0 release are as follows:
- Removed support to read tables with certain special characters in the partition column name. See the migration guide for details.
- Support for “delta.`path`” in DeltaTable.forName() for consistency with other APIs.
- Improvements to DeltaTableBuilder API introduced in Delta 1.0.0:
- Fix for bug that prevented the passing of multiple partition columns in Python DeltaTableBuilder.partitionBy.
- Throw error when the column data type is not specified.
- Improved support for MERGE/UPDATE/DELETE on temp views.
- Support for setting user metadata in the commit information when creating or replacing tables.
- Fix for an incorrect analysis exception in MERGE with multiple INSERT and UPDATE clauses and automatic schema evolution enabled.
- Fix for incorrect handling of special characters (e.g. spaces) in paths by MERGE/UPDATE/DELETE operations.
- Fix for Vacuum parallel mode from being affected by the Adaptive Query Execution enabled by default in Apache Spark 3.2.
- Fix for earliest valid time travel version.
- Fix for Hadoop configurations not being used to write checkpoints.
- Multiple fixes (1, 2, 3) to Delta Constraints.
In the next section, let’s dive deeper into the most notable features of this release.
Better performance out-of-the-box for MERGE operation
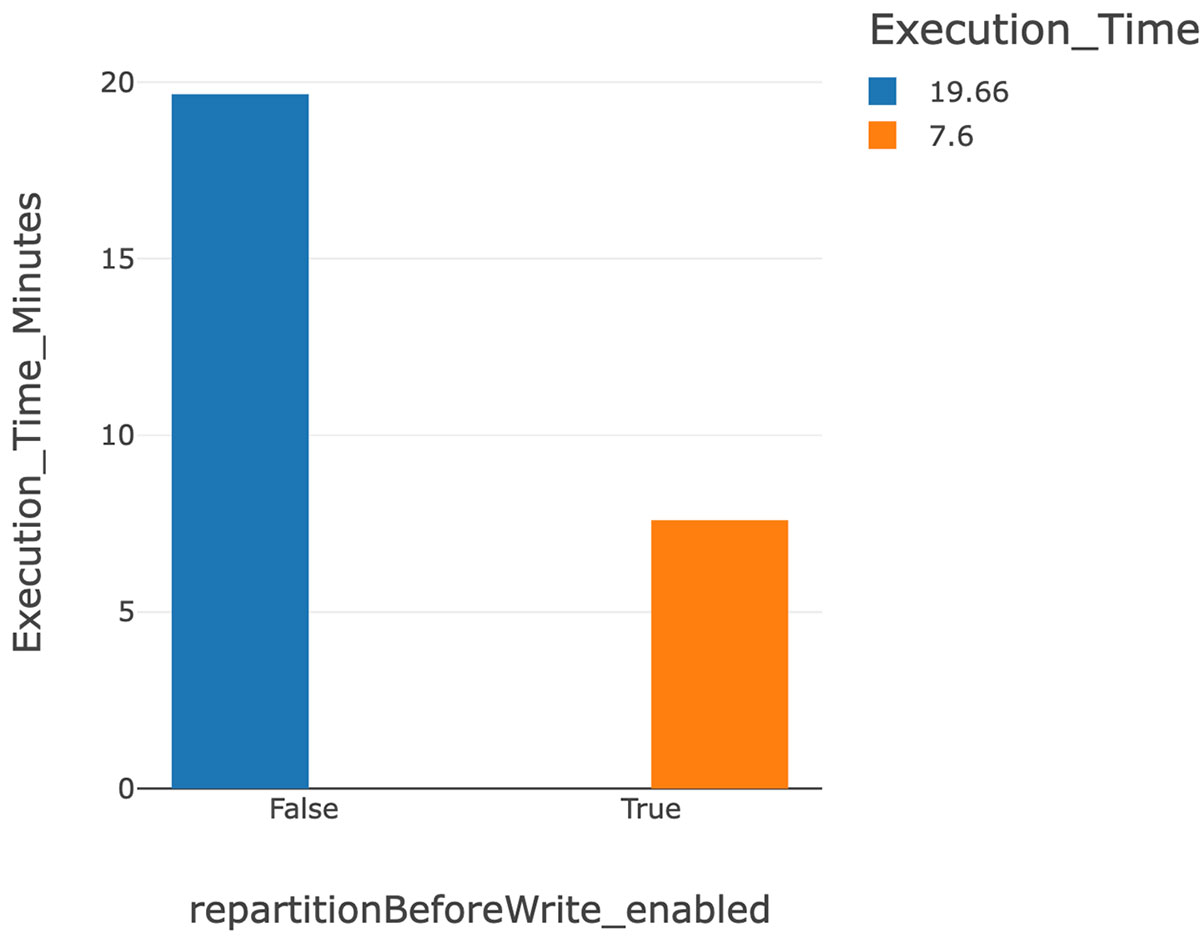
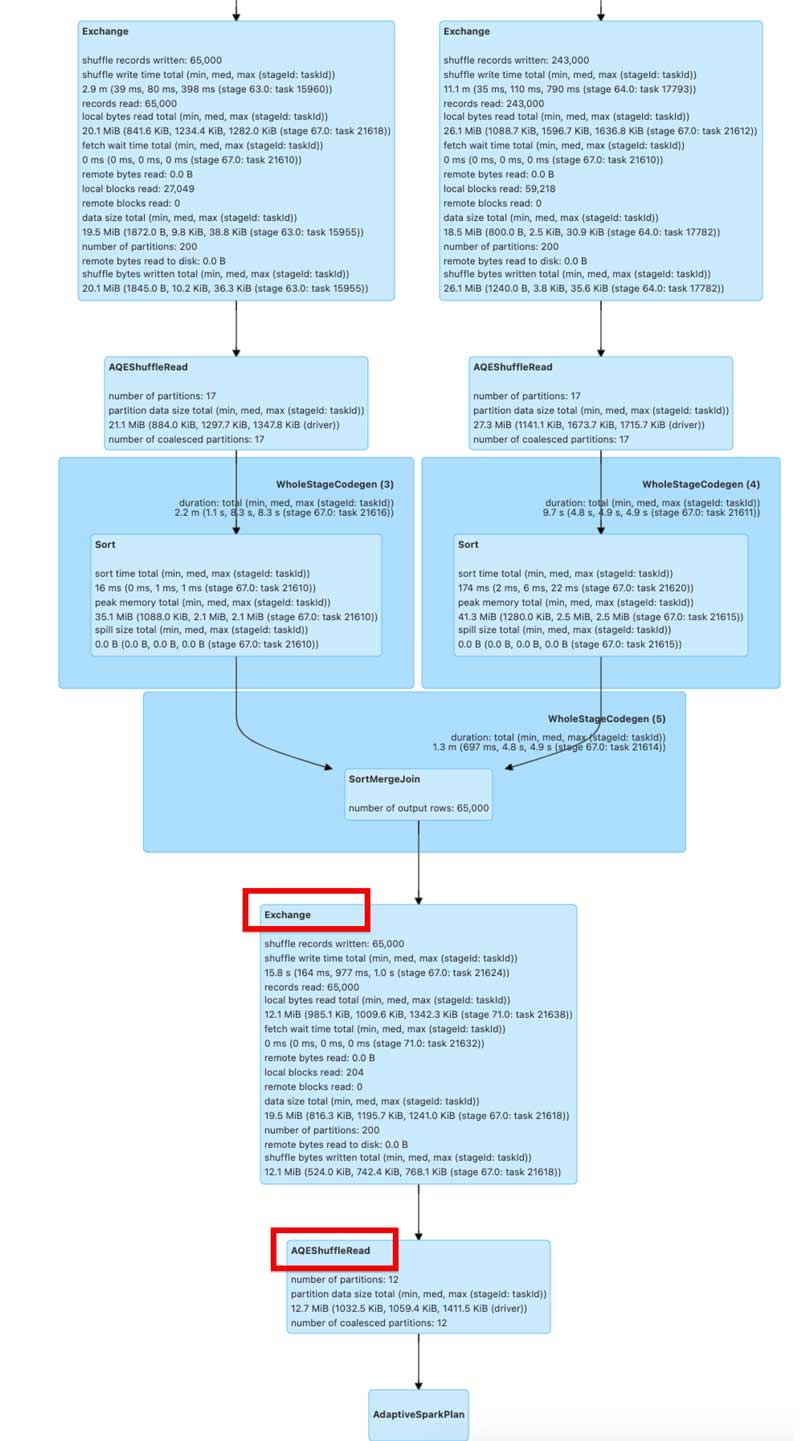
- The above graph shows the significant reduction in execution time from 19.66 minutes (before) to 7.6 minutes (after) the feature flag was enabled.
- Notice the difference in stages in the DAG visualization below for both the queries before and after. There is an additional stage for AQE ShuffleRead after the SortMergeJoin.
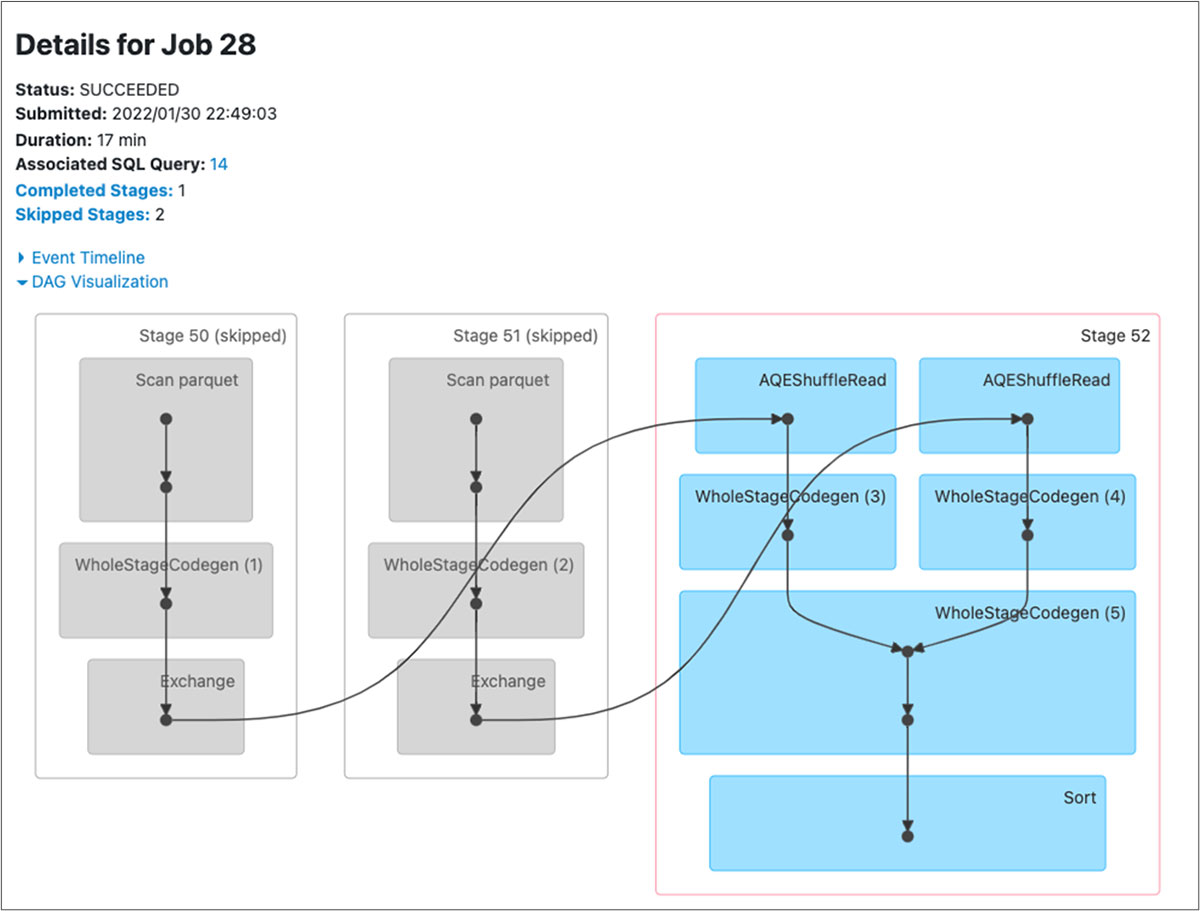
Figure: DAG for the delta merge query with repartitionBeforeWrite
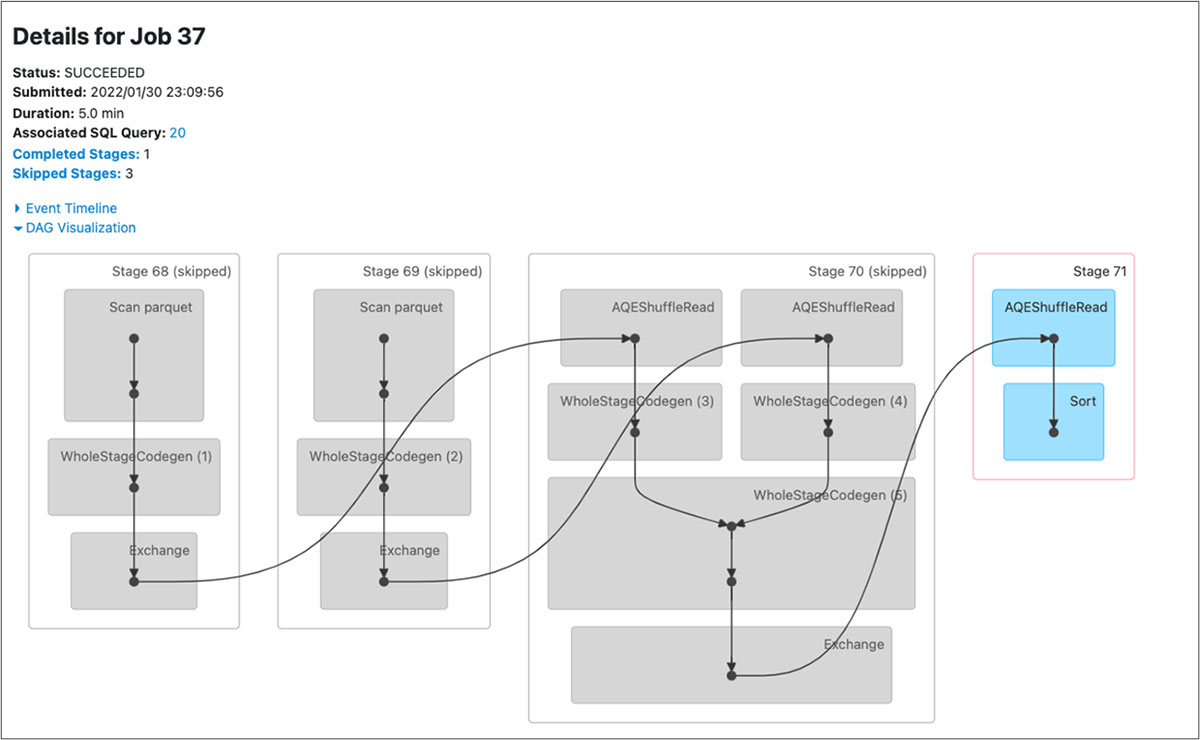
Figure: DAG for the delta merge query with repartitionBeforeWrite
Let’s take a look at the example now:
In the data set used for this example, customers1 and customers2 have 200000 rows and 11 columns with information about customers and sales. To showcase the difference between enabling the flag when running a MERGE operation on the bare minimum, we limited the Spark job to 1GB RAM and 1 core running on Macbook Pro 2019 laptop. These numbers can be further reduced by tweaking the RAM and cores used. In the MERGE table, customers_merge with 45000 rows was used to perform a MERGE operation on the former tables. Full script and results for the example are available here.
To ensure that the feature was disabled, you can run the following command:
CODE:
Results:
Note: The full operation took 19.66 minutes while the feature flag was disabled. You can refer to this full result for the details of the query.
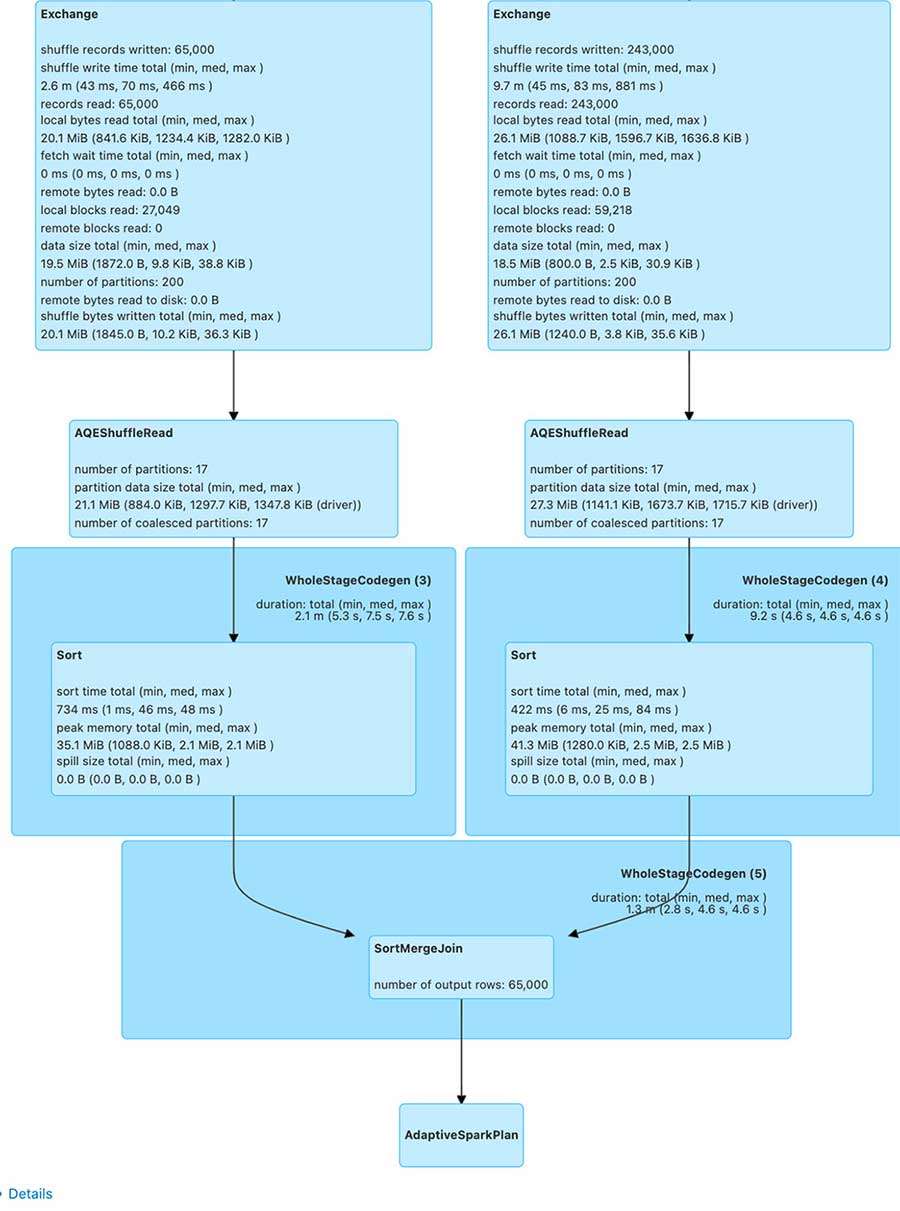
For partitioned tables, the MERGE can produce a much larger number of small files than the number of shuffle partitions. This is because every shuffle task can write multiple files in multiple partitions, and can become a performance bottleneck. To enable faster MERGE operation on our partitioned table, let's enable repartitionBeforeWrite using the code snippet below.
Enable the flag and run the merge again.
This will allow MERGE operation to automatically repartition the output data of partitioned tables before writing to files. In many cases, it helps to repartition the output data by the table’s partition columns before writing it. This ensures better performance out-of-the-box for both the MERGE operation as well as subsequent read operations. Let’s run the MERGE operation on our table customer_t0 now.
Note: After enabling the feature “repartitionBeforeWrite”, the merge query took 7.68 minutes. You can refer to this full result for the details of the query.
Tip: Organizations working around the GDPR and CCPA use case can highly appreciate this feature, as it provides a cost-effective way to do fast point updates and deletes without rearchitecting your entire data lake.
Support for arbitrary expressions in replaceWhere DataFrameWriter option
To atomically replace all the data in a table, you can use overwrite mode:
With Delta Lake 1.1.0 and above, you can also selectively overwrite only the data that matches an arbitrary expression using dataframes. The following command atomically replaces records with the birth year ‘1924’ in the target table, which is partitioned by c_birth_year, with the data in customer_t1:
This query will result in a successful run and an output like below:
However, for the past releases of Delta Lake which were before 1.1.0, the same query would result in the following error:
You can try it by disabling the replaceWhere flag.
Python Type Annotations
Python type annotations improve auto-completion performance in editors, which support type hints. Optionally, you can enable static checking through mypy or built-in tools (for example Pycharm tools). Here is a video from the original author of the PR, Maciej Szymkiewicz describing the changes in the behavior of python within delta lake 1.1.
Hope you got to see some cool Delta Lake features through this blog post. Excited to find out where you are using these features and if you have any feedback or examples of your work, please share with the community.
Summary
Lakehouse has become a new norm for organizations wanting to build Data platforms and architecture. And all thanks to Delta Lake - which allowed in excess of 5000 organizations out there to build successful production Lakehouse Platform for their data and Artificial Intelligence applications. With the exponential data increase, it's important to process volumes of data faster and reliably. With Delta lake, developers can make their lakehouses run much faster with the improvements in version 1.1 and keep the pace of innovation.
Interested in the open-source Delta Lake?
Visit the Delta Lake online hub to learn more, you can join the Delta Lake community via Slack and Google Group. You can track all the upcoming releases and planned features in GitHub milestones and try out Managed Delta Lake on Databricks with a free account.
Credits
We want to thank the following contributors for updates, doc changes, and contributions in Delta Lake 1.1.0: Abhishek Somani, Adam Binford, Alex Jing, Alexandre Lopes, Allison Portis, Bogdan Raducanu, Bart Samwel, Burak Yavuz, David Lewis, Eunjin Song, ericfchang, Feng Zhu, Flavio Cruz, Florian Valeye, Fred Liu, gurunath, Guy Khazma, Jacek Laskowski, Jackie Zhang, Jarred Parrett, JassAbidi, Jose Torres, Junlin Zeng, Junyong Lee, KamCheung Ting, Karen Feng, Lars Kroll, Li Zhang, Linhong Liu, Liwen Sun, Maciej, Max Gekk, Meng Tong, Prakhar Jain, Pranav Anand, Rahul Mahadev, Ryan Johnson, Sabir Akhadov, Scott Sandre, Shixiong Zhu, Shuting Zhang, Tathagata Das, Terry Kim, Tom Lynch, Vijayan Prabhakaran, Vítor Mussa, Wenchen Fan, Yaohua Zhao, Yijia Cui, YuXuan Tay, Yuchen Huo, Yuhong Chen, Yuming Wang, Yuyuan Tang, and Zach Schuermann.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.